 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRogue-Gym: A New Challenge for Generalization in Reinforcement Learning
Paper and Code
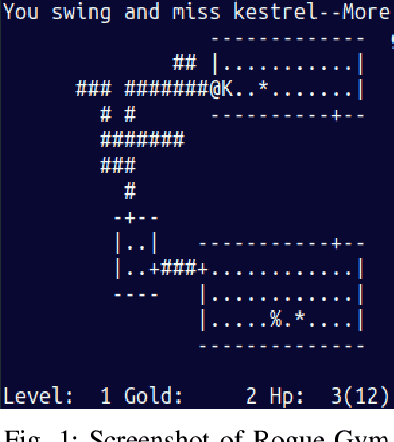
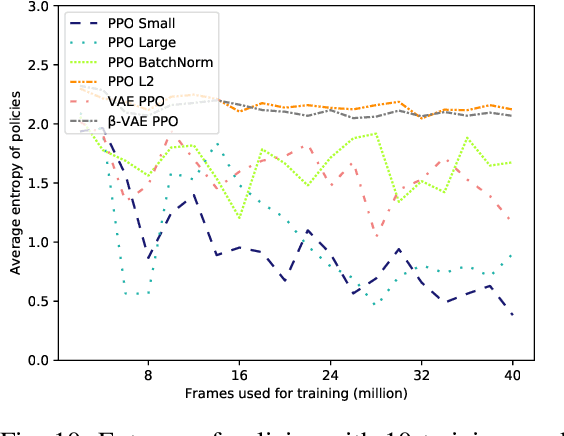
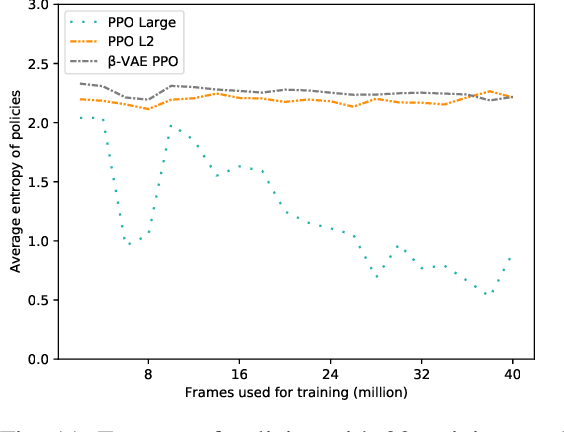
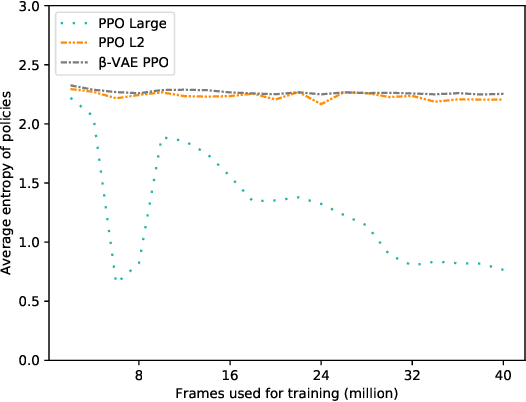
This paper presents Rogue-Gym, that enables agents to learn and play a subset of the original Rogue game with the OpenAI Gym interface. In roguelike games, a player explores a dungeon where each floor is two dimensional grid maze with enemies, golds, and downstairs. Because the map of a dungeon is different each time an agent starts a new game, learning in Rogue-Gym inevitably involves generalization of experiences, in a highly abstract manner. We argue that this generalization in reinforcement learning is a big challenge for AI agents. Recently, deep reinforcement learning (DRL) has succeeded in many games. However, it has been pointed out that agents trained by DRL methods often overfit to the training environment. To investigate this problem, some research environments with procedural content generation have been proposed. Following these studies, we show that our Rogue-Gym imposes a new generalization problem of their policies. In our experiments, we evaluate a standard reinforcement learning method, PPO, with and without enhancements for generalization. The results show that some enhancements work effective, but that there is still a large room for improvement. Therefore, Rogue-Gym a is a new challenging domain for further studies.