 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEIR: Efficient and Robust Exploration through Discriminative-Model-Based Episodic Intrinsic Rewards
Apr 21, 2023
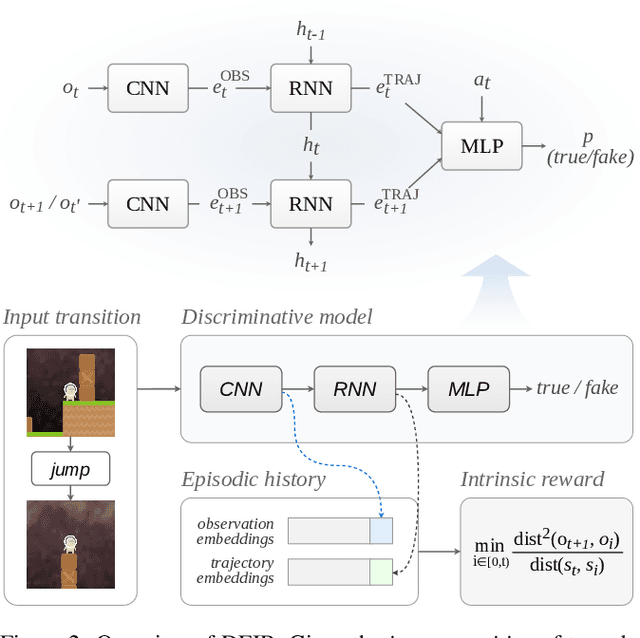


Exploration is a fundamental aspect of reinforcement learning (RL), and its effectiveness crucially decides the performance of RL algorithms, especially when facing sparse extrinsic rewards. Recent studies showed the effectiveness of encouraging exploration with intrinsic rewards estimated from novelty in observations. However, there is a gap between the novelty of an observation and an exploration in general, because the stochasticity in the environment as well as the behavior of an agent may affect the observation. To estimate exploratory behaviors accurately, we propose DEIR, a novel method where we theoretically derive an intrinsic reward from a conditional mutual information term that principally scales with the novelty contributed by agent explorations, and materialize the reward with a discriminative forward model. We conduct extensive experiments in both standard and hardened exploration games in MiniGrid to show that DEIR quickly learns a better policy than baselines. Our evaluations in ProcGen demonstrate both generalization capabilities and the general applicability of our intrinsic reward.