 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying Catan with Cross-dimensional Neural Network
Paper and Code



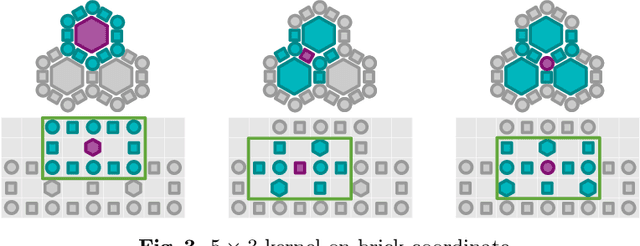
Catan is a strategic board game having interesting properties, including multi-player, imperfect information, stochastic, complex state space structure (hexagonal board where each vertex, edge and face has its own features, cards for each player, etc), and a large action space (including negotiation). Therefore, it is challenging to build AI agents by Reinforcement Learning (RL for short), without domain knowledge nor heuristics. In this paper, we introduce cross-dimensional neural networks to handle a mixture of information sources and a wide variety of outputs, and empirically demonstrate that the network dramatically improves RL in Catan. We also show that, for the first time, a RL agent can outperform jsettler, the best heuristic agent available.