 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-VITS: Enhancing TTS Synthesis with Semantic Awareness
Paper and Code
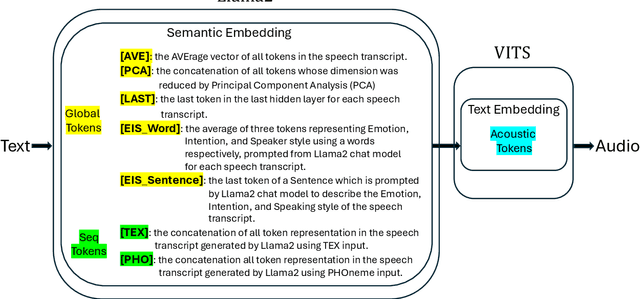



Recent advancements in Natural Language Processing (NLP) have seen Large-scale Language Models (LLMs) excel at producing high-quality text for various purposes. Notably, in Text-To-Speech (TTS) systems, the integration of BERT for semantic token generation has underscored the importance of semantic content in producing coherent speech outputs. Despite this, the specific utility of LLMs in enhancing TTS synthesis remains considerably limited. This research introduces an innovative approach, Llama-VITS, which enhances TTS synthesis by enriching the semantic content of text using LLM. Llama-VITS integrates semantic embeddings from Llama2 with the VITS model, a leading end-to-end TTS framework. By leveraging Llama2 for the primary speech synthesis process, our experiments demonstrate that Llama-VITS matches the naturalness of the original VITS (ORI-VITS) and those incorporate BERT (BERT-VITS), on the LJSpeech dataset, a substantial collection of neutral, clear speech. Moreover, our method significantly enhances emotive expressiveness on the EmoV_DB_bea_sem dataset, a curated selection of emotionally consistent speech from the EmoV_DB dataset, highlighting its potential to generate emotive speech.