 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Neurons and Heads in Transformer-based LLMs for Typographical Errors
Feb 27, 2025



This paper investigates how LLMs encode inputs with typos. We hypothesize that specific neurons and attention heads recognize typos and fix them internally using local and global contexts. We introduce a method to identify typo neurons and typo heads that work actively when inputs contain typos. Our experimental results suggest the following: 1) LLMs can fix typos with local contexts when the typo neurons in either the early or late layers are activated, even if those in the other are not. 2) Typo neurons in the middle layers are responsible for the core of typo-fixing with global contexts. 3) Typo heads fix typos by widely considering the context not focusing on specific tokens. 4) Typo neurons and typo heads work not only for typo-fixing but also for understanding general contexts.
SubRegWeigh: Effective and Efficient Annotation Weighing with Subword Regularization
Sep 10, 2024


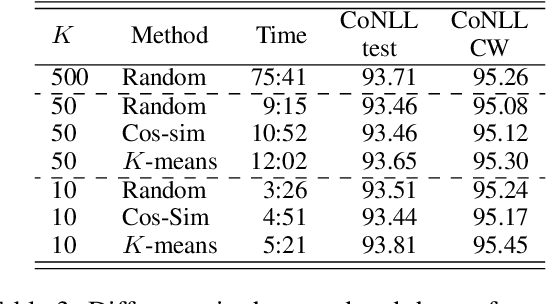
Many datasets of natural language processing (NLP) sometimes include annotation errors. Researchers have attempted to develop methods to reduce the adverse effect of errors in datasets automatically. However, an existing method is time-consuming because it requires many trained models to detect errors. We propose a novel method to reduce the time of error detection. Specifically, we use a tokenization technique called subword regularization to create pseudo-multiple models which are used to detect errors. Our proposed method, SubRegWeigh, can perform annotation weighting four to five times faster than the existing method. Additionally, SubRegWeigh improved performance in both document classification and named entity recognition tasks. In experiments with pseudo-incorrect labels, pseudo-incorrect labels were adequately detected.
Downstream Task-Oriented Neural Tokenizer Optimization with Vocabulary Restriction as Post Processing
Apr 21, 2023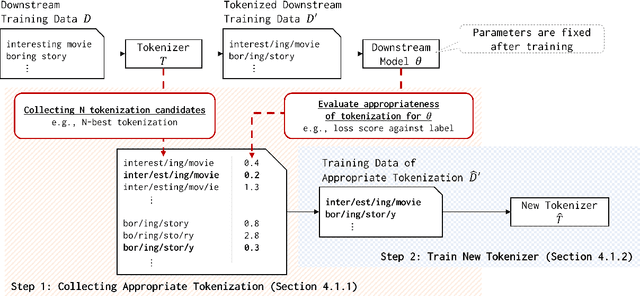
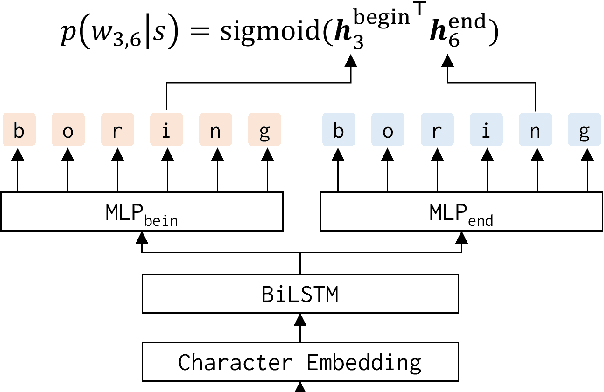
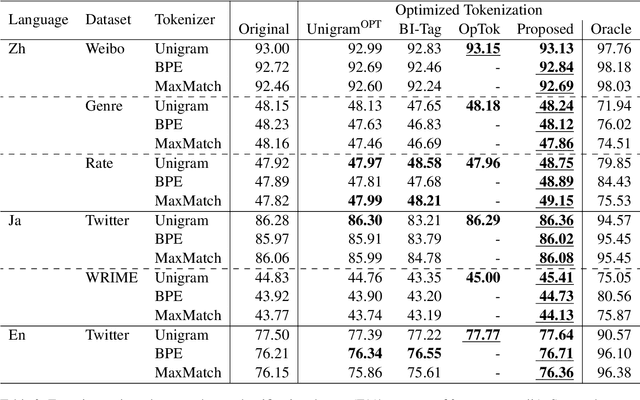
This paper proposes a method to optimize tokenization for the performance improvement of already trained downstream models. Our method generates tokenization results attaining lower loss values of a given downstream model on the training data for restricting vocabularies and trains a tokenizer reproducing the tokenization results. Therefore, our method can be applied to variety of tokenization methods, while existing work cannot due to the simultaneous learning of the tokenizer and the downstream model. This paper proposes an example of the BiLSTM-based tokenizer with vocabulary restriction, which can capture wider contextual information for the tokenization process than non-neural-based tokenization methods used in existing work. Experimental results on text classification in Japanese, Chinese, and English text classification tasks show that the proposed method improves performance compared to the existing methods for tokenization optimization.
Tokenization Tractability for Human and Machine Learning Model: An Annotation Study
Apr 21, 2023

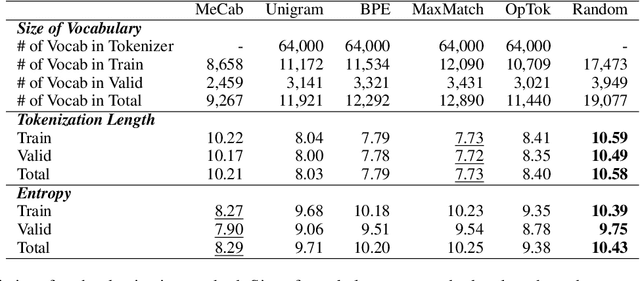

Is tractable tokenization for humans also tractable for machine learning models? This study investigates relations between tractable tokenization for humans (e.g., appropriateness and readability) and one for models of machine learning (e.g., performance on an NLP task). We compared six tokenization methods on the Japanese commonsense question-answering dataset (JCommmonsenseQA in JGLUE). We tokenized question texts of the QA dataset with different tokenizers and compared the performance of human annotators and machine-learning models. Besides,we analyze relationships among the performance, appropriateness of tokenization, and response time to questions. This paper provides a quantitative investigation result that shows the tractable tokenizations for humans and machine learning models are not necessarily the same as each other.