 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Primacy and Recency Effect in Mamba: A Mechanistic Point of View
Jun 18, 2025We study memory in state-space language models using primacy and recency effects as behavioral tools to uncover how information is retained and forgotten over time. Applying structured recall tasks to the Mamba architecture, we observe a consistent U-shaped accuracy profile, indicating strong performance at the beginning and end of input sequences. We identify three mechanisms that give rise to this pattern. First, long-term memory is supported by a sparse subset of channels within the model's selective state space block, which persistently encode early input tokens and are causally linked to primacy effects. Second, short-term memory is governed by delta-modulated recurrence: recent inputs receive more weight due to exponential decay, but this recency advantage collapses when distractor items are introduced, revealing a clear limit to memory depth. Third, we find that memory allocation is dynamically modulated by semantic regularity: repeated relations in the input sequence shift the delta gating behavior, increasing the tendency to forget intermediate items. We validate these findings via targeted ablations and input perturbations on two large-scale Mamba-based language models: one with 1.4B and another with 7B parameters.
Mechanistic Insights into Grokking from the Embedding Layer
May 21, 2025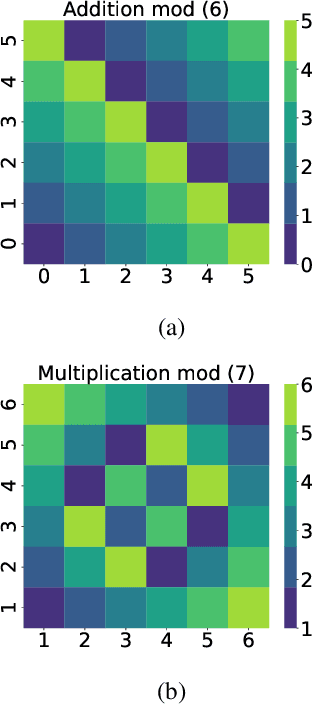
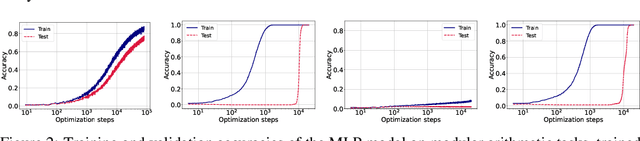
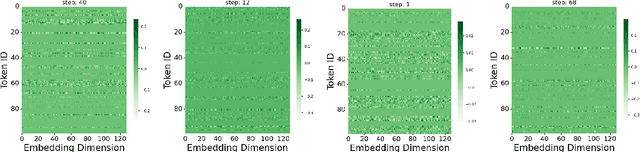
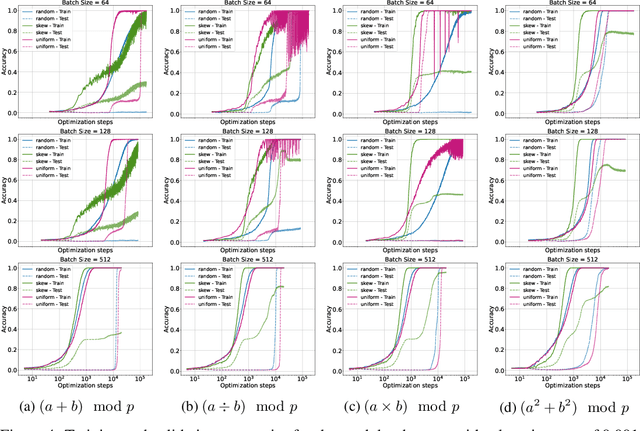
Grokking, a delayed generalization in neural networks after perfect training performance, has been observed in Transformers and MLPs, but the components driving it remain underexplored. We show that embeddings are central to grokking: introducing them into MLPs induces delayed generalization in modular arithmetic tasks, whereas MLPs without embeddings can generalize immediately. Our analysis identifies two key mechanisms: (1) Embedding update dynamics, where rare tokens stagnate due to sparse gradient updates and weight decay, and (2) Bilinear coupling, where the interaction between embeddings and downstream weights introduces saddle points and increases sensitivity to initialization. To confirm these mechanisms, we investigate frequency-aware sampling, which balances token updates by minimizing gradient variance, and embedding-specific learning rates, derived from the asymmetric curvature of the bilinear loss landscape. We prove that an adaptive learning rate ratio, \(\frac{\eta_E}{\eta_W} \propto \frac{\sigma_{\max}(E)}{\sigma_{\max}(W)} \cdot \frac{f_W}{f_E}\), mitigates bilinear coupling effects, accelerating convergence. Our methods not only improve grokking dynamics but also extend to broader challenges in Transformer optimization, where bilinear interactions hinder efficient training.
Number Representations in LLMs: A Computational Parallel to Human Perception
Feb 22, 2025Humans are believed to perceive numbers on a logarithmic mental number line, where smaller values are represented with greater resolution than larger ones. This cognitive bias, supported by neuroscience and behavioral studies, suggests that numerical magnitudes are processed in a sublinear fashion rather than on a uniform linear scale. Inspired by this hypothesis, we investigate whether large language models (LLMs) exhibit a similar logarithmic-like structure in their internal numerical representations. By analyzing how numerical values are encoded across different layers of LLMs, we apply dimensionality reduction techniques such as PCA and PLS followed by geometric regression to uncover latent structures in the learned embeddings. Our findings reveal that the model's numerical representations exhibit sublinear spacing, with distances between values aligning with a logarithmic scale. This suggests that LLMs, much like humans, may encode numbers in a compressed, non-uniform manner.
The Geometry of Numerical Reasoning: Language Models Compare Numeric Properties in Linear Subspaces
Oct 17, 2024This paper investigates whether large language models (LLMs) utilize numerical attributes encoded in a low-dimensional subspace of the embedding space when answering logical comparison questions (e.g., Was Cristiano born before Messi?). We first identified these subspaces using partial least squares regression, which effectively encodes the numerical attributes associated with the entities in comparison prompts. Further, we demonstrate causality by intervening in these subspaces to manipulate hidden states, thereby altering the LLM's comparison outcomes. Experimental results show that our findings hold for different numerical attributes, indicating that LLMs utilize the linearly encoded information for numerical reasoning.
Limited Memory Online Gradient Descent for Kernelized Pairwise Learning with Dynamic Averaging
Feb 02, 2024
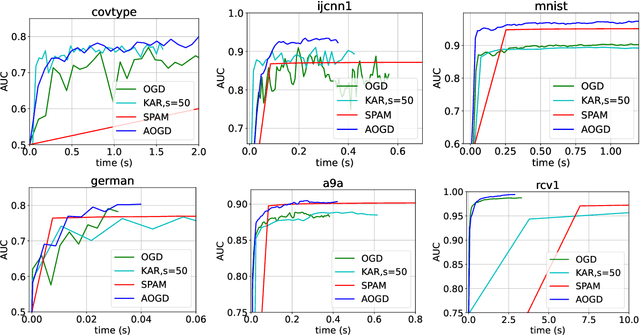

Pairwise learning, an important domain within machine learning, addresses loss functions defined on pairs of training examples, including those in metric learning and AUC maximization. Acknowledging the quadratic growth in computation complexity accompanying pairwise loss as the sample size grows, researchers have turned to online gradient descent (OGD) methods for enhanced scalability. Recently, an OGD algorithm emerged, employing gradient computation involving prior and most recent examples, a step that effectively reduces algorithmic complexity to $O(T)$, with $T$ being the number of received examples. This approach, however, confines itself to linear models while assuming the independence of example arrivals. We introduce a lightweight OGD algorithm that does not require the independence of examples and generalizes to kernel pairwise learning. Our algorithm builds the gradient based on a random example and a moving average representing the past data, which results in a sub-linear regret bound with a complexity of $O(T)$. Furthermore, through the integration of $O(\sqrt{T}{\log{T}})$ random Fourier features, the complexity of kernel calculations is effectively minimized. Several experiments with real-world datasets show that the proposed technique outperforms kernel and linear algorithms in offline and online scenarios.
Variance Reduced Online Gradient Descent for Kernelized Pairwise Learning with Limited Memory
Oct 10, 2023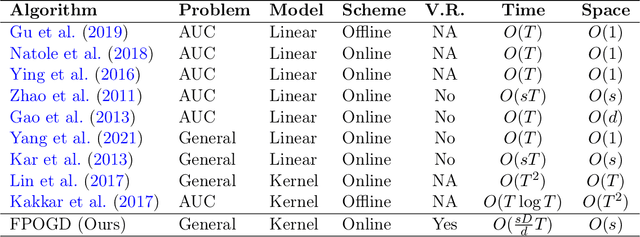
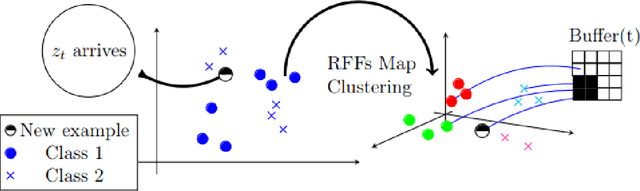
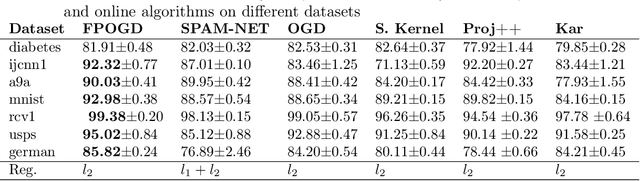
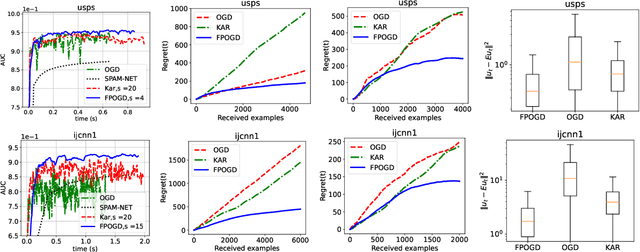
Pairwise learning is essential in machine learning, especially for problems involving loss functions defined on pairs of training examples. Online gradient descent (OGD) algorithms have been proposed to handle online pairwise learning, where data arrives sequentially. However, the pairwise nature of the problem makes scalability challenging, as the gradient computation for a new sample involves all past samples. Recent advancements in OGD algorithms have aimed to reduce the complexity of calculating online gradients, achieving complexities less than $O(T)$ and even as low as $O(1)$. However, these approaches are primarily limited to linear models and have induced variance. In this study, we propose a limited memory OGD algorithm that extends to kernel online pairwise learning while improving the sublinear regret. Specifically, we establish a clear connection between the variance of online gradients and the regret, and construct online gradients using the most recent stratified samples with a limited buffer of size of $s$ representing all past data, which have a complexity of $O(sT)$ and employs $O(\sqrt{T}\log{T})$ random Fourier features for kernel approximation. Importantly, our theoretical results demonstrate that the variance-reduced online gradients lead to an improved sublinear regret bound. The experiments on real-world datasets demonstrate the superiority of our algorithm over both kernelized and linear online pairwise learning algorithms.
Computational Complexity of Sub-Linear Convergent Algorithms
Oct 05, 2022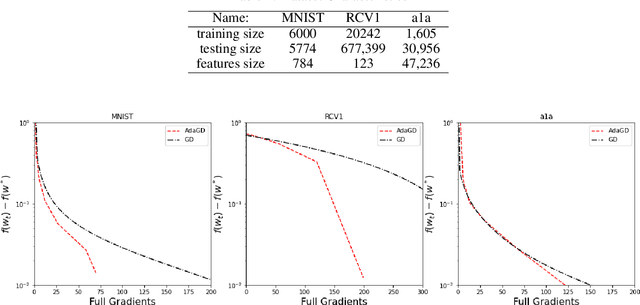

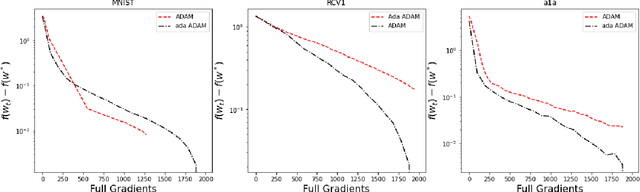
Optimizing machine learning algorithms that are used to solve the objective function has been of great interest. Several approaches to optimize common algorithms, such as gradient descent and stochastic gradient descent, were explored. One of these approaches is reducing the gradient variance through adaptive sampling to solve large-scale optimization's empirical risk minimization (ERM) problems. In this paper, we will explore how starting with a small sample and then geometrically increasing it and using the solution of the previous sample ERM to compute the new ERM. This will solve ERM problems with first-order optimization algorithms of sublinear convergence but with lower computational complexity. This paper starts with theoretical proof of the approach, followed by two experiments comparing the gradient descent with the adaptive sampling of the gradient descent and ADAM with adaptive sampling ADAM on different datasets.
Pairwise Learning via Stagewise Training in Proximal Setting
Aug 08, 2022
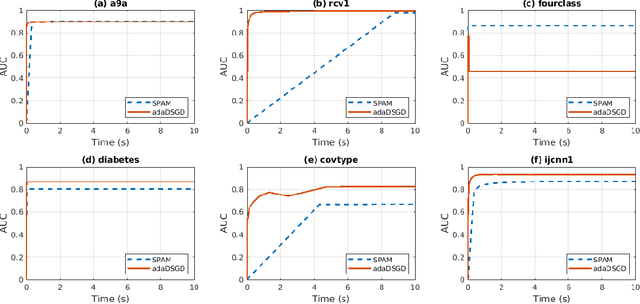
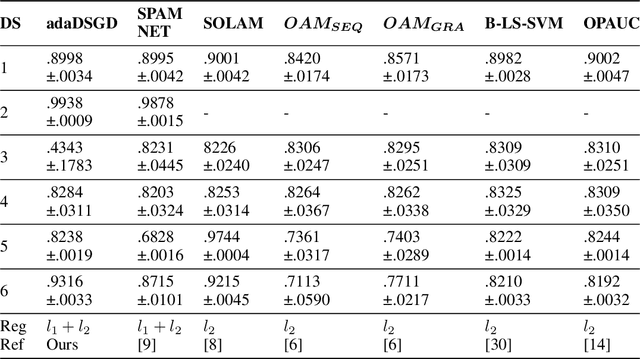
The pairwise objective paradigms are an important and essential aspect of machine learning. Examples of machine learning approaches that use pairwise objective functions include differential network in face recognition, metric learning, bipartite learning, multiple kernel learning, and maximizing of area under the curve (AUC). Compared to pointwise learning, pairwise learning's sample size grows quadratically with the number of samples and thus its complexity. Researchers mostly address this challenge by utilizing an online learning system. Recent research has, however, offered adaptive sample size training for smooth loss functions as a better strategy in terms of convergence and complexity, but without a comprehensive theoretical study. In a distinct line of research, importance sampling has sparked a considerable amount of interest in finite pointwise-sum minimization. This is because of the stochastic gradient variance, which causes the convergence to be slowed considerably. In this paper, we combine adaptive sample size and importance sampling techniques for pairwise learning, with convergence guarantees for nonsmooth convex pairwise loss functions. In particular, the model is trained stochastically using an expanded training set for a predefined number of iterations derived from the stability bounds. In addition, we demonstrate that sampling opposite instances at each iteration reduces the variance of the gradient, hence accelerating convergence. Experiments on a broad variety of datasets in AUC maximization confirm the theoretical results.
Investigating a Baseline Of Self Supervised Learning Towards Reducing Labeling Costs For Image Classification
Aug 17, 2021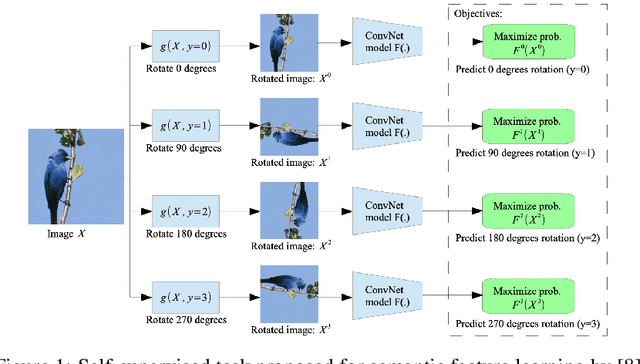
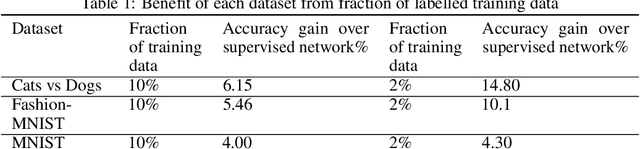
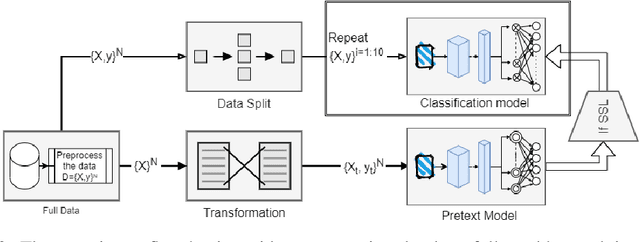
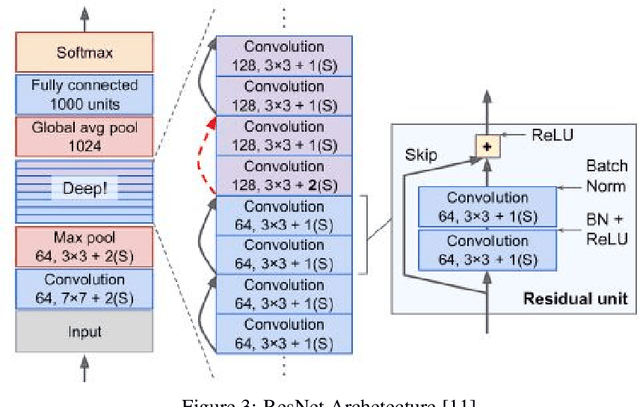
Data labeling in supervised learning is considered an expensive and infeasible tool in some conditions. The self-supervised learning method is proposed to tackle the learning effectiveness with fewer labeled data, however, there is a lack of confidence in the size of labeled data needed to achieve adequate results. This study aims to draw a baseline on the proportion of the labeled data that models can appreciate to yield competent accuracy when compared to training with additional labels. The study implements the kaggle.com' cats-vs-dogs dataset, Mnist and Fashion-Mnist to investigate the self-supervised learning task by implementing random rotations augmentation on the original datasets. To reveal the true effectiveness of the pretext process in self-supervised learning, the original dataset is divided into smaller batches, and learning is repeated on each batch with and without the pretext pre-training. Results show that the pretext process in the self-supervised learning improves the accuracy around 15% in the downstream classification task when compared to the plain supervised learning.