 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Mask-Guided Vision Transformer for Fine-Grained Classification
May 11, 2023
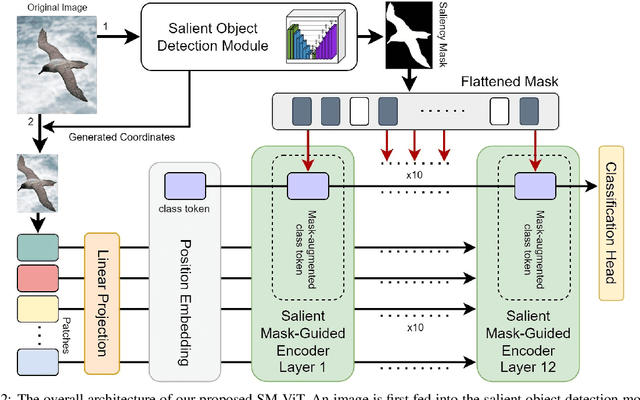
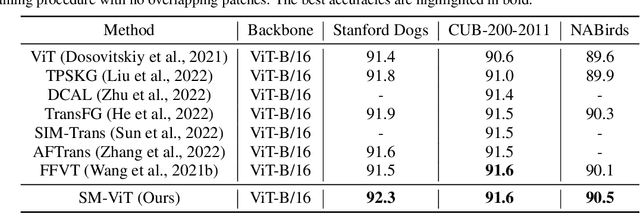
Fine-grained visual classification (FGVC) is a challenging computer vision problem, where the task is to automatically recognise objects from subordinate categories. One of its main difficulties is capturing the most discriminative inter-class variances among visually similar classes. Recently, methods with Vision Transformer (ViT) have demonstrated noticeable achievements in FGVC, generally by employing the self-attention mechanism with additional resource-consuming techniques to distinguish potentially discriminative regions while disregarding the rest. However, such approaches may struggle to effectively focus on truly discriminative regions due to only relying on the inherent self-attention mechanism, resulting in the classification token likely aggregating global information from less-important background patches. Moreover, due to the immense lack of the datapoints, classifiers may fail to find the most helpful inter-class distinguishing features, since other unrelated but distinctive background regions may be falsely recognised as being valuable. To this end, we introduce a simple yet effective Salient Mask-Guided Vision Transformer (SM-ViT), where the discriminability of the standard ViT`s attention maps is boosted through salient masking of potentially discriminative foreground regions. Extensive experiments demonstrate that with the standard training procedure our SM-ViT achieves state-of-the-art performance on popular FGVC benchmarks among existing ViT-based approaches while requiring fewer resources and lower input image resolution.
* Accepted by VISAPP 2023 (Best Student Paper Award)
Pairwise Learning via Stagewise Training in Proximal Setting
Aug 08, 2022
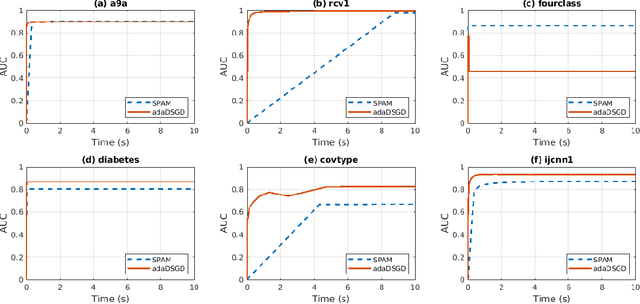
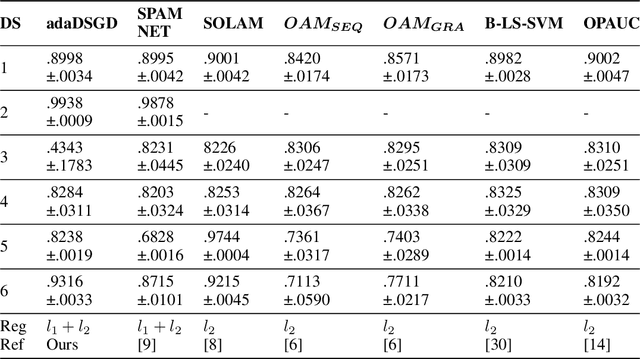
The pairwise objective paradigms are an important and essential aspect of machine learning. Examples of machine learning approaches that use pairwise objective functions include differential network in face recognition, metric learning, bipartite learning, multiple kernel learning, and maximizing of area under the curve (AUC). Compared to pointwise learning, pairwise learning's sample size grows quadratically with the number of samples and thus its complexity. Researchers mostly address this challenge by utilizing an online learning system. Recent research has, however, offered adaptive sample size training for smooth loss functions as a better strategy in terms of convergence and complexity, but without a comprehensive theoretical study. In a distinct line of research, importance sampling has sparked a considerable amount of interest in finite pointwise-sum minimization. This is because of the stochastic gradient variance, which causes the convergence to be slowed considerably. In this paper, we combine adaptive sample size and importance sampling techniques for pairwise learning, with convergence guarantees for nonsmooth convex pairwise loss functions. In particular, the model is trained stochastically using an expanded training set for a predefined number of iterations derived from the stability bounds. In addition, we demonstrate that sampling opposite instances at each iteration reduces the variance of the gradient, hence accelerating convergence. Experiments on a broad variety of datasets in AUC maximization confirm the theoretical results.