 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeY-CA-Net: A Convolutional Attention Based Network for Volumetric Medical Image Segmentation
Oct 01, 2024



Recent attention-based volumetric segmentation (VS) methods have achieved remarkable performance in the medical domain which focuses on modeling long-range dependencies. However, for voxel-wise prediction tasks, discriminative local features are key components for the performance of the VS models which is missing in attention-based VS methods. Aiming at resolving this issue, we deliberately incorporate the convolutional encoder branch with transformer backbone to extract local and global features in a parallel manner and aggregate them in Cross Feature Mixer Module (CFMM) for better prediction of segmentation mask. Consequently, we observe that the derived model, Y-CT-Net, achieves competitive performance on multiple medical segmentation tasks. For example, on multi-organ segmentation, Y-CT-Net achieves an 82.4% dice score, surpassing well-tuned VS Transformer/CNN-like baselines UNETR/ResNet-3D by 2.9%/1.4%. With the success of Y-CT-Net, we extend this concept with hybrid attention models, that derived Y-CH-Net model, which brings a 3% improvement in terms of HD95 score for same segmentation task. The effectiveness of both models Y-CT-Net and Y-CH-Net verifies our hypothesis and motivates us to initiate the concept of Y-CA-Net, a versatile generic architecture based upon any two encoders and a decoder backbones, to fully exploit the complementary strengths of both convolution and attention mechanisms. Based on experimental results, we argue Y-CA-Net is a key player in achieving superior results for volumetric segmentation.
TransResNet: Integrating the Strengths of ViTs and CNNs for High Resolution Medical Image Segmentation via Feature Grafting
Oct 01, 2024



High-resolution images are preferable in medical imaging domain as they significantly improve the diagnostic capability of the underlying method. In particular, high resolution helps substantially in improving automatic image segmentation. However, most of the existing deep learning-based techniques for medical image segmentation are optimized for input images having small spatial dimensions and perform poorly on high-resolution images. To address this shortcoming, we propose a parallel-in-branch architecture called TransResNet, which incorporates Transformer and CNN in a parallel manner to extract features from multi-resolution images independently. In TransResNet, we introduce Cross Grafting Module (CGM), which generates the grafted features, enriched in both global semantic and low-level spatial details, by combining the feature maps from Transformer and CNN branches through fusion and self-attention mechanism. Moreover, we use these grafted features in the decoding process, increasing the information flow for better prediction of the segmentation mask. Extensive experiments on ten datasets demonstrate that TransResNet achieves either state-of-the-art or competitive results on several segmentation tasks, including skin lesion, retinal vessel, and polyp segmentation. The source code and pre-trained models are available at https://github.com/Sharifmhamza/TransResNet.
Salient Mask-Guided Vision Transformer for Fine-Grained Classification
May 11, 2023
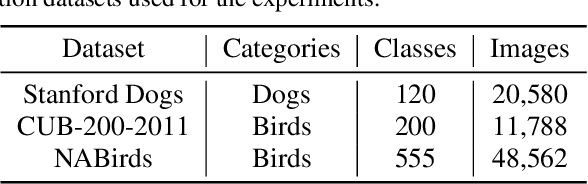
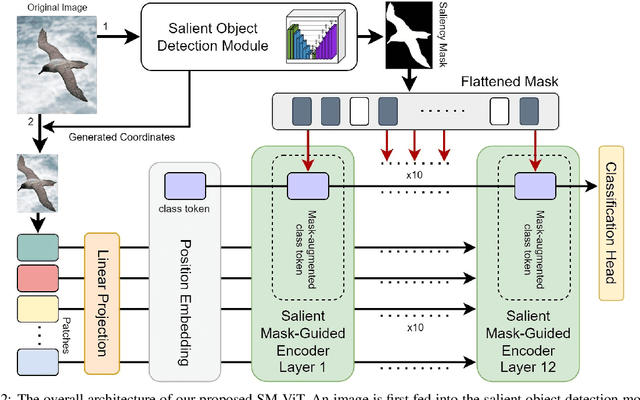
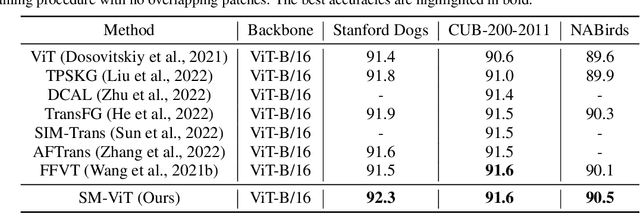
Fine-grained visual classification (FGVC) is a challenging computer vision problem, where the task is to automatically recognise objects from subordinate categories. One of its main difficulties is capturing the most discriminative inter-class variances among visually similar classes. Recently, methods with Vision Transformer (ViT) have demonstrated noticeable achievements in FGVC, generally by employing the self-attention mechanism with additional resource-consuming techniques to distinguish potentially discriminative regions while disregarding the rest. However, such approaches may struggle to effectively focus on truly discriminative regions due to only relying on the inherent self-attention mechanism, resulting in the classification token likely aggregating global information from less-important background patches. Moreover, due to the immense lack of the datapoints, classifiers may fail to find the most helpful inter-class distinguishing features, since other unrelated but distinctive background regions may be falsely recognised as being valuable. To this end, we introduce a simple yet effective Salient Mask-Guided Vision Transformer (SM-ViT), where the discriminability of the standard ViT`s attention maps is boosted through salient masking of potentially discriminative foreground regions. Extensive experiments demonstrate that with the standard training procedure our SM-ViT achieves state-of-the-art performance on popular FGVC benchmarks among existing ViT-based approaches while requiring fewer resources and lower input image resolution.
* Accepted by VISAPP 2023 (Best Student Paper Award)