 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Guideline for the Labovian-Structural Analysis of Oral Narratives in Japanese
Mar 31, 2026Narrative analysis is a cornerstone of qualitative research. One leading approach is the Labovian model, but its application is labor-intensive, requiring a holistic, recursive interpretive process that moves back and forth between individual parts of the transcript and the transcript as a whole. Existing Labovian datasets are available only in English, which differs markedly from Japanese in terms of grammar and discourse conventions. To address this gap, we introduce the first systematic guidelines for Labovian narrative analysis of Japanese narrative data. Our guidelines retain all six Labovian categories and extend the framework by providing explicit rules for clause segmentation tailored to Japanese constructions. In addition, our guidelines cover a broader range of clause types and narrative types. Using these guidelines, annotators achieved high agreement in clause segmentation (Fleiss' kappa = 0.80) and moderate agreement in two structural classification tasks (Krippendorff's alpha = 0.41 and 0.45, respectively), one of which is slightly higher than that found in prior work despite the use of finer-grained distinctions. This paper describes the Labovian model, the proposed guidelines, the annotation process, and their utility. It concludes by discussing the challenges encountered during the annotation process and the prospects for developing a larger dataset for structural narrative analysis in Japanese qualitative research.
Investigating Training and Generalization in Faithful Self-Explanations of Large Language Models
Dec 08, 2025Large language models have the potential to generate explanations for their own predictions in a variety of styles based on user instructions. Recent research has examined whether these self-explanations faithfully reflect the models' actual behavior and has found that they often lack faithfulness. However, the question of how to improve faithfulness remains underexplored. Moreover, because different explanation styles have superficially distinct characteristics, it is unclear whether improvements observed in one style also arise when using other styles. This study analyzes the effects of training for faithful self-explanations and the extent to which these effects generalize, using three classification tasks and three explanation styles. We construct one-word constrained explanations that are likely to be faithful using a feature attribution method, and use these pseudo-faithful self-explanations for continual learning on instruction-tuned models. Our experiments demonstrate that training can improve self-explanation faithfulness across all classification tasks and explanation styles, and that these improvements also show signs of generalization to the multi-word settings and to unseen tasks. Furthermore, we find consistent cross-style generalization among three styles, suggesting that training may contribute to a broader improvement in faithful self-explanation ability.
Do Large Vision-Language Models Distinguish between the Actual and Apparent Features of Illusions?
Jun 06, 2025Humans are susceptible to optical illusions, which serve as valuable tools for investigating sensory and cognitive processes. Inspired by human vision studies, research has begun exploring whether machines, such as large vision language models (LVLMs), exhibit similar susceptibilities to visual illusions. However, studies often have used non-abstract images and have not distinguished actual and apparent features, leading to ambiguous assessments of machine cognition. To address these limitations, we introduce a visual question answering (VQA) dataset, categorized into genuine and fake illusions, along with corresponding control images. Genuine illusions present discrepancies between actual and apparent features, whereas fake illusions have the same actual and apparent features even though they look illusory due to the similar geometric configuration. We evaluate the performance of LVLMs for genuine and fake illusion VQA tasks and investigate whether the models discern actual and apparent features. Our findings indicate that although LVLMs may appear to recognize illusions by correctly answering questions about both feature types, they predict the same answers for both Genuine Illusion and Fake Illusion VQA questions. This suggests that their responses might be based on prior knowledge of illusions rather than genuine visual understanding. The dataset is available at https://github.com/ynklab/FILM
Topic Modeling for Short Texts with Large Language Models
Jun 02, 2024

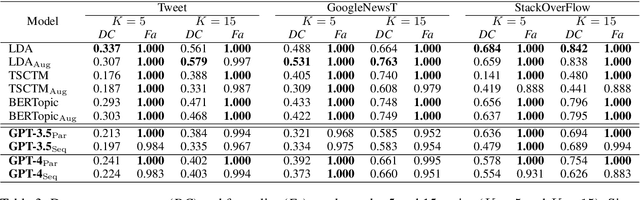

As conventional topic models rely on word co-occurrence to infer latent topics, topic modeling for short texts has been a long-standing challenge. Large Language Models (LLMs) can potentially overcome this challenge by contextually learning the semantics of words via pretraining. This paper studies two approaches, parallel prompting and sequential prompting, to use LLMs for topic modeling. Due to the input length limitations, LLMs cannot process many texts at once. By splitting the texts into smaller subsets and processing them parallelly or sequentially, an arbitrary number of texts can be handled by LLMs. Experimental results demonstrated that our methods can identify more coherent topics than existing ones while maintaining the diversity of the induced topics. Furthermore, we found that the inferred topics adequately covered the input texts, while hallucinated topics were hardly generated.