 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling for Short Texts with Large Language Models
Paper and Code


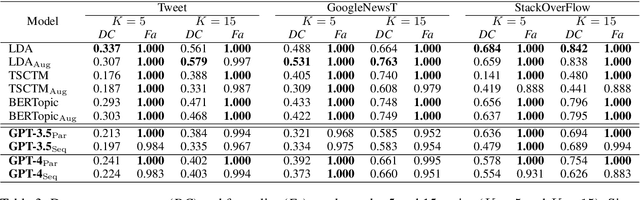

As conventional topic models rely on word co-occurrence to infer latent topics, topic modeling for short texts has been a long-standing challenge. Large Language Models (LLMs) can potentially overcome this challenge by contextually learning the semantics of words via pretraining. This paper studies two approaches, parallel prompting and sequential prompting, to use LLMs for topic modeling. Due to the input length limitations, LLMs cannot process many texts at once. By splitting the texts into smaller subsets and processing them parallelly or sequentially, an arbitrary number of texts can be handled by LLMs. Experimental results demonstrated that our methods can identify more coherent topics than existing ones while maintaining the diversity of the induced topics. Furthermore, we found that the inferred topics adequately covered the input texts, while hallucinated topics were hardly generated.