 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell-Based Representation of Relational Binding in Language Models
Apr 21, 2026Understanding a discourse requires tracking entities and the relations that hold between them. While Large Language Models (LLMs) perform well on relational reasoning, the mechanism by which they bind entities, relations, and attributes remains unclear. We study discourse-level relational binding and show that LLMs encode it via a Cell-based Binding Representation (CBR): a low-dimensional linear subspace in which each ``cell'' corresponds to an entity--relation index pair, and bound attributes are retrieved from the corresponding cell during inference. Using controlled multi-sentence data annotated with entity and relation indices, we identify the CBR subspace by decoding these indices from attribute-token activations with Partial Least Squares regression. Across domains and two model families, the indices are linearly decodable and form a grid-like geometry in the projected space. We further find that context-specific CBR representations are related by translation vectors in activation space, enabling cross-context transfer. Finally, activation patching shows that manipulating this subspace systematically changes relational predictions and that perturbing it disrupts performance, providing causal evidence that LLMs rely on CBR for relational binding.
Representational Analysis of Binding in Large Language Models
Sep 09, 2024Entity tracking is essential for complex reasoning. To perform in-context entity tracking, language models (LMs) must bind an entity to its attribute (e.g., bind a container to its content) to recall attribute for a given entity. For example, given a context mentioning ``The coffee is in Box Z, the stone is in Box M, the map is in Box H'', to infer ``Box Z contains the coffee'' later, LMs must bind ``Box Z'' to ``coffee''. To explain the binding behaviour of LMs, Feng and Steinhardt (2023) introduce a Binding ID mechanism and state that LMs use a abstract concept called Binding ID (BI) to internally mark entity-attribute pairs. However, they have not directly captured the BI determinant information from entity activations. In this work, we provide a novel view of the Binding ID mechanism by localizing the prototype of BI information. Specifically, we discover that there exists a low-rank subspace in the hidden state (or activation) of LMs, that primarily encodes the order of entity and attribute and which is used as the prototype of BI to causally determine the binding. To identify this subspace, we choose principle component analysis as our first attempt and it is empirically proven to be effective. Moreover, we also discover that when editing representations along directions in the subspace, LMs tend to bind a given entity to other attributes accordingly. For example, by patching activations along the BI encoding direction we can make the LM to infer ``Box Z contains the stone'' and ``Box Z contains the map''.
Cross-stitching Text and Knowledge Graph Encoders for Distantly Supervised Relation Extraction
Nov 02, 2022



Bi-encoder architectures for distantly-supervised relation extraction are designed to make use of the complementary information found in text and knowledge graphs (KG). However, current architectures suffer from two drawbacks. They either do not allow any sharing between the text encoder and the KG encoder at all, or, in case of models with KG-to-text attention, only share information in one direction. Here, we introduce cross-stitch bi-encoders, which allow full interaction between the text encoder and the KG encoder via a cross-stitch mechanism. The cross-stitch mechanism allows sharing and updating representations between the two encoders at any layer, with the amount of sharing being dynamically controlled via cross-attention-based gates. Experimental results on two relation extraction benchmarks from two different domains show that enabling full interaction between the two encoders yields strong improvements.
Two Training Strategies for Improving Relation Extraction over Universal Graph
Feb 12, 2021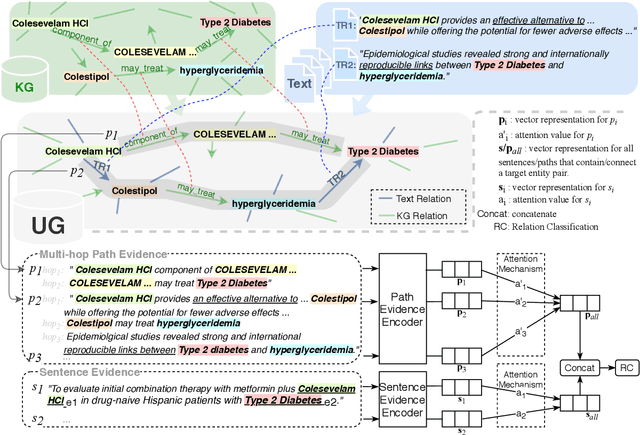
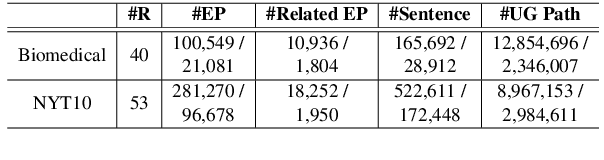
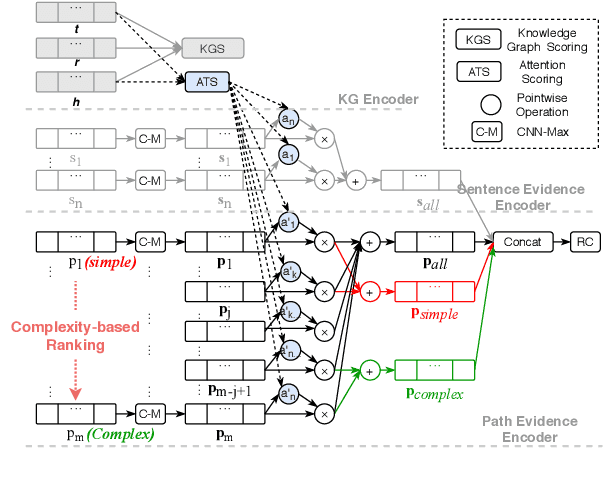
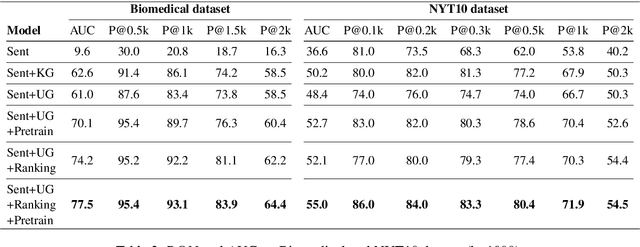
This paper explores how the Distantly Supervised Relation Extraction (DS-RE) can benefit from the use of a Universal Graph (UG), the combination of a Knowledge Graph (KG) and a large-scale text collection. A straightforward extension of a current state-of-the-art neural model for DS-RE with a UG may lead to degradation in performance. We first report that this degradation is associated with the difficulty in learning a UG and then propose two training strategies: (1) Path Type Adaptive Pretraining, which sequentially trains the model with different types of UG paths so as to prevent the reliance on a single type of UG path; and (2) Complexity Ranking Guided Attention mechanism, which restricts the attention span according to the complexity of a UG path so as to force the model to extract features not only from simple UG paths but also from complex ones. Experimental results on both biomedical and NYT10 datasets prove the robustness of our methods and achieve a new state-of-the-art result on the NYT10 dataset. The code and datasets used in this paper are available at https://github.com/baodaiqin/UGDSRE.