 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAYEL at SemEval-2020 Task 12: TF/IDF-Based Approach for Automatic Offensive Language Detection in Arabic Tweets
Jul 27, 2020

In this paper, we present the system submitted to "SemEval-2020 Task 12". The proposed system aims at automatically identify the Offensive Language in Arabic Tweets. A machine learning based approach has been used to design our system. We implemented a linear classifier with Stochastic Gradient Descent (SGD) as optimization algorithm. Our model reported 84.20%, 81.82% f1-score on development set and test set respectively. The best performed system and the system in the last rank reported 90.17% and 44.51% f1-score on test set respectively.
Integrating Dictionary Feature into A Deep Learning Model for Disease Named Entity Recognition
Nov 05, 2019

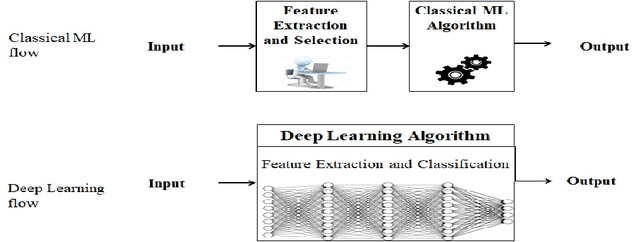

In recent years, Deep Learning (DL) models are becoming important due to their demonstrated success at overcoming complex learning problems. DL models have been applied effectively for different Natural Language Processing (NLP) tasks such as part-of-Speech (PoS) tagging and Machine Translation (MT). Disease Named Entity Recognition (Disease-NER) is a crucial task which aims at extracting disease Named Entities (NEs) from text. In this paper, a DL model for Disease-NER using dictionary information is proposed and evaluated on National Center for Biotechnology Information (NCBI) disease corpus and BC5CDR dataset. Word embeddings trained over general domain texts as well as biomedical texts have been used to represent input to the proposed model. This study also compares two different Segment Representation (SR) schemes, namely IOB2 and IOBES for Disease-NER. The results illustrate that using dictionary information, pre-trained word embeddings, character embeddings and CRF with global score improves the performance of Disease-NER system.
Improving Multi-Word Entity Recognition for Biomedical Texts
Aug 15, 2019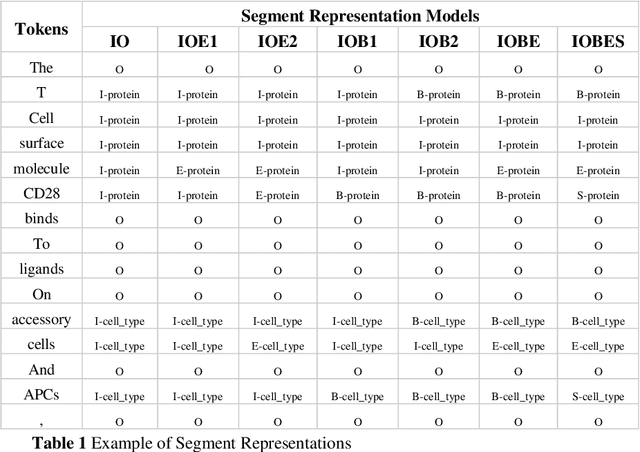
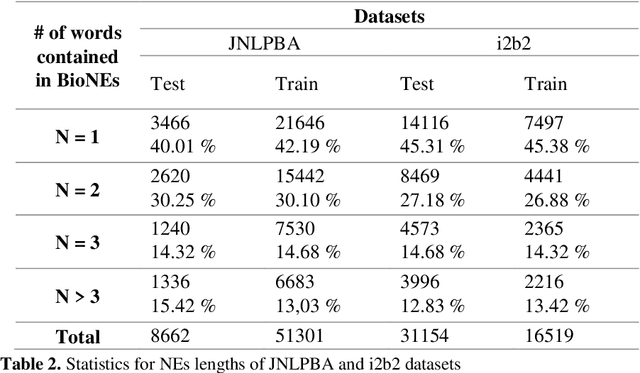
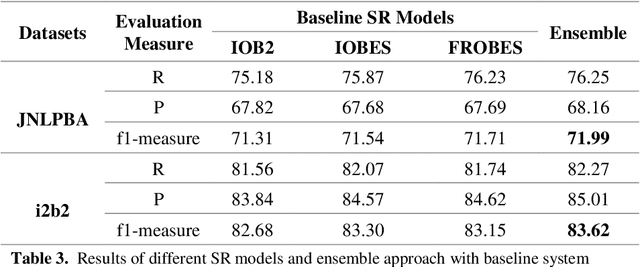
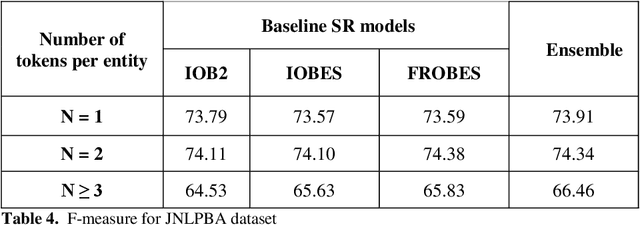
Biomedical Named Entity Recognition (BioNER) is a crucial step for analyzing Biomedical texts, which aims at extracting biomedical named entities from a given text. Different supervised machine learning algorithms have been applied for BioNER by various researchers. The main requirement of these approaches is an annotated dataset used for learning the parameters of machine learning algorithms. Segment Representation (SR) models comprise of different tag sets used for representing the annotated data, such as IOB2, IOE2 and IOBES. In this paper, we propose an extension of IOBES model to improve the performance of BioNER. The proposed SR model, FROBES, improves the representation of multi-word entities. We used Bidirectional Long Short-Term Memory (BiLSTM) network; an instance of Recurrent Neural Networks (RNN), to design a baseline system for BioNER and evaluated the new SR model on two datasets, i2b2/VA 2010 challenge dataset and JNLPBA 2004 shared task dataset. The proposed SR model outperforms other models for multi-word entities with length greater than two. Further, the outputs of different SR models have been combined using majority voting ensemble method which outperforms the baseline models performance.
* 13 pages, 2 figures, International Conference on Cognitive Informatics and Soft Computing (ICCISC-2017)