 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLI-Machine Learning Approaches for Code-mixed Language Identification at the Word Level in Kannada-English Texts
Nov 17, 2022The task of automatically identifying a language used in a given text is called Language Identification (LI). India is a multilingual country and many Indians especially youths are comfortable with Hindi and English, in addition to their local languages. Hence, they often use more than one language to post their comments on social media. Texts containing more than one language are called "code-mixed texts" and are a good source of input for LI. Languages in these texts may be mixed at sentence level, word level or even at sub-word level. LI at word level is a sequence labeling problem where each and every word in a sentence is tagged with one of the languages in the predefined set of languages. In order to address word level LI in code-mixed Kannada-English (Kn-En) texts, this work presents i) the construction of code-mixed Kn-En dataset called CoLI-Kenglish dataset, ii) code-mixed Kn-En embedding and iii) learning models using Machine Learning (ML), Deep Learning (DL) and Transfer Learning (TL) approaches. Code-mixed Kn-En texts are extracted from Kannada YouTube video comments to construct CoLI-Kenglish dataset and code-mixed Kn-En embedding. The words in CoLI-Kenglish dataset are grouped into six major categories, namely, "Kannada", "English", "Mixed-language", "Name", "Location" and "Other". The learning models, namely, CoLI-vectors and CoLI-ngrams based on ML, CoLI-BiLSTM based on DL and CoLI-ULMFiT based on TL approaches are built and evaluated using CoLI-Kenglish dataset. The performances of the learning models illustrated, the superiority of CoLI-ngrams model, compared to other models with a macro average F1-score of 0.64. However, the results of all the learning models were quite competitive with each other.
Improving Multi-Word Entity Recognition for Biomedical Texts
Aug 15, 2019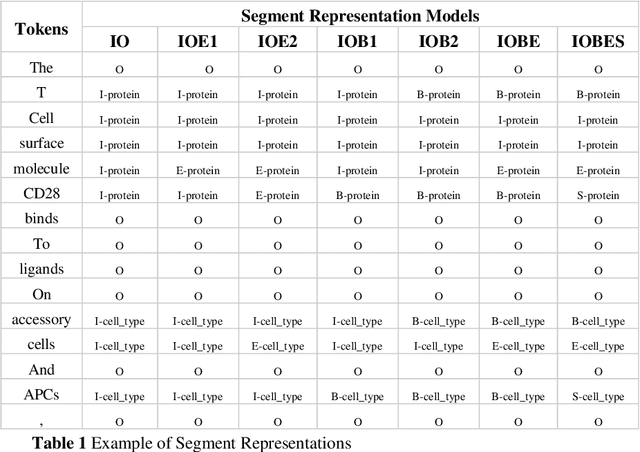
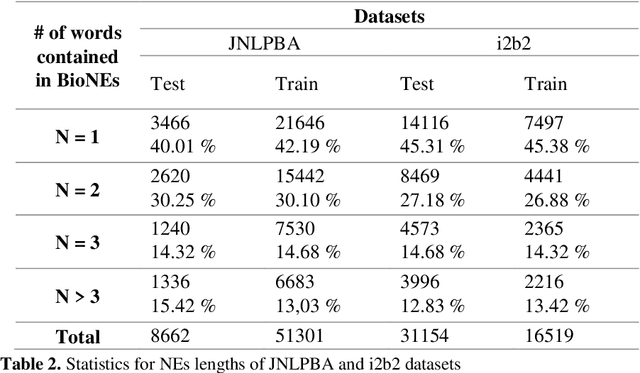
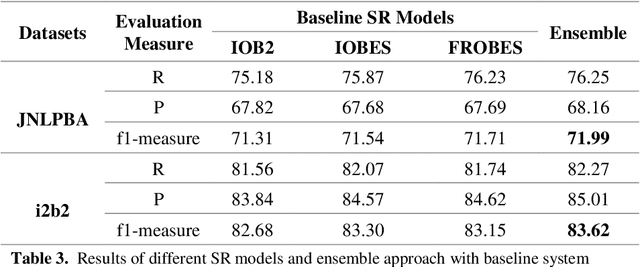
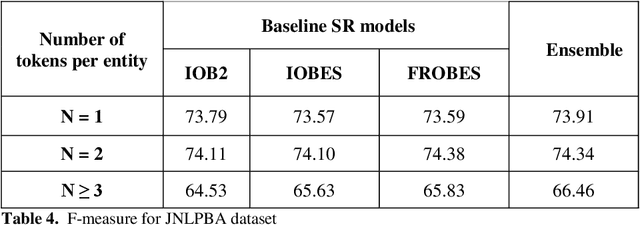
Biomedical Named Entity Recognition (BioNER) is a crucial step for analyzing Biomedical texts, which aims at extracting biomedical named entities from a given text. Different supervised machine learning algorithms have been applied for BioNER by various researchers. The main requirement of these approaches is an annotated dataset used for learning the parameters of machine learning algorithms. Segment Representation (SR) models comprise of different tag sets used for representing the annotated data, such as IOB2, IOE2 and IOBES. In this paper, we propose an extension of IOBES model to improve the performance of BioNER. The proposed SR model, FROBES, improves the representation of multi-word entities. We used Bidirectional Long Short-Term Memory (BiLSTM) network; an instance of Recurrent Neural Networks (RNN), to design a baseline system for BioNER and evaluated the new SR model on two datasets, i2b2/VA 2010 challenge dataset and JNLPBA 2004 shared task dataset. The proposed SR model outperforms other models for multi-word entities with length greater than two. Further, the outputs of different SR models have been combined using majority voting ensemble method which outperforms the baseline models performance.
* 13 pages, 2 figures, International Conference on Cognitive Informatics and Soft Computing (ICCISC-2017)