 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training of Deep Contextualized Embeddings of Words and Entities for Named Entity Disambiguation
Paper and Code
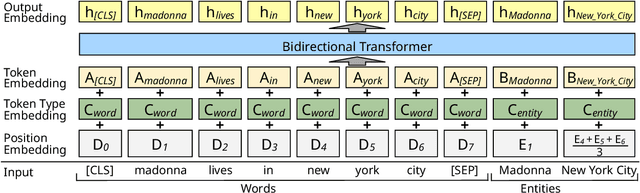

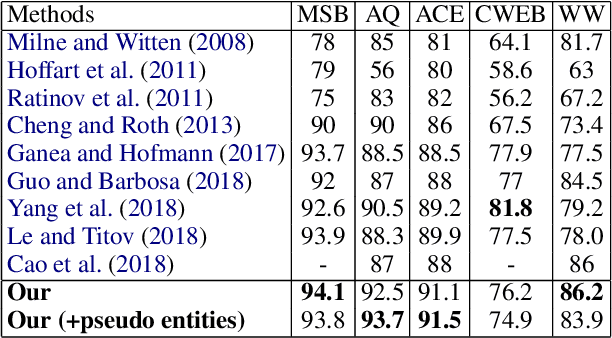
Deep contextualized embeddings trained using unsupervised language modeling (e.g., ELMo and BERT) are successful in a wide range of NLP tasks. In this paper, we propose a new contextualized embedding model of words and entities for named entity disambiguation (NED). Our model is based on the bidirectional transformer encoder and produces contextualized embeddings for words and entities in the input text. The embeddings are trained using a new masked entity prediction task that aims to train the model by predicting randomly masked entities in entity-annotated texts. We trained the model using entity-annotated texts obtained from Wikipedia. We evaluated our model by addressing NED using a simple NED model based on the trained contextualized embeddings. As a result, we achieved state-of-the-art or competitive results on several standard NED datasets.