 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Multi-Task Learning Model for Image-based Table Recognition
Mar 29, 2023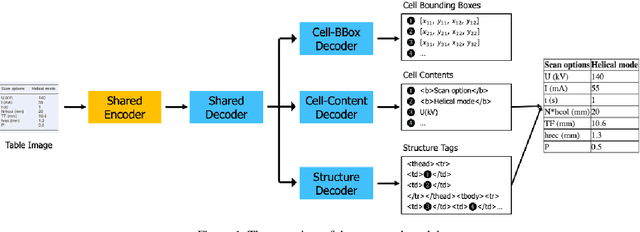

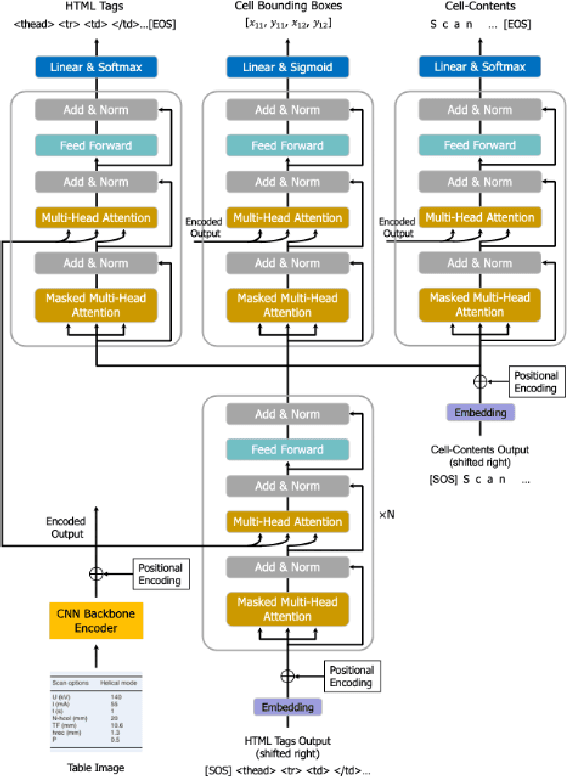

Image-based table recognition is a challenging task due to the diversity of table styles and the complexity of table structures. Most of the previous methods focus on a non-end-to-end approach which divides the problem into two separate sub-problems: table structure recognition; and cell-content recognition and then attempts to solve each sub-problem independently using two separate systems. In this paper, we propose an end-to-end multi-task learning model for image-based table recognition. The proposed model consists of one shared encoder, one shared decoder, and three separate decoders which are used for learning three sub-tasks of table recognition: table structure recognition, cell detection, and cell-content recognition. The whole system can be easily trained and inferred in an end-to-end approach. In the experiments, we evaluate the performance of the proposed model on two large-scale datasets: FinTabNet and PubTabNet. The experiment results show that the proposed model outperforms the state-of-the-art methods in all benchmark datasets.
* 10 pages, VISAPP2023. arXiv admin note: substantial text overlap with arXiv:2303.07641
TabIQA: Table Questions Answering on Business Document Images
Mar 27, 2023



Table answering questions from business documents has many challenges that require understanding tabular structures, cross-document referencing, and additional numeric computations beyond simple search queries. This paper introduces a novel pipeline, named TabIQA, to answer questions about business document images. TabIQA combines state-of-the-art deep learning techniques 1) to extract table content and structural information from images and 2) to answer various questions related to numerical data, text-based information, and complex queries from structured tables. The evaluation results on VQAonBD 2023 dataset demonstrate the effectiveness of TabIQA in achieving promising performance in answering table-related questions. The TabIQA repository is available at https://github.com/phucty/itabqa.
Rethinking Image-based Table Recognition Using Weakly Supervised Methods
Mar 14, 2023



Most of the previous methods for table recognition rely on training datasets containing many richly annotated table images. Detailed table image annotation, e.g., cell or text bounding box annotation, however, is costly and often subjective. In this paper, we propose a weakly supervised model named WSTabNet for table recognition that relies only on HTML (or LaTeX) code-level annotations of table images. The proposed model consists of three main parts: an encoder for feature extraction, a structure decoder for generating table structure, and a cell decoder for predicting the content of each cell in the table. Our system is trained end-to-end by stochastic gradient descent algorithms, requiring only table images and their ground-truth HTML (or LaTeX) representations. To facilitate table recognition with deep learning, we create and release WikiTableSet, the largest publicly available image-based table recognition dataset built from Wikipedia. WikiTableSet contains nearly 4 million English table images, 590K Japanese table images, and 640k French table images with corresponding HTML representation and cell bounding boxes. The extensive experiments on WikiTableSet and two large-scale datasets: FinTabNet and PubTabNet demonstrate that the proposed weakly supervised model achieves better, or similar accuracies compared to the state-of-the-art models on all benchmark datasets.
* 10 pages, ICPRAM2023
Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition
Jun 28, 2021


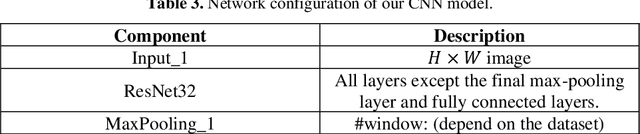
In this paper, we propose an RNN-Transducer model for recognizing Japanese and Chinese offline handwritten text line images. As far as we know, it is the first approach that adopts the RNN-Transducer model for offline handwritten text recognition. The proposed model consists of three main components: a visual feature encoder that extracts visual features from an input image by CNN and then encodes the visual features by BLSTM; a linguistic context encoder that extracts and encodes linguistic features from the input image by embedded layers and LSTM; and a joint decoder that combines and then decodes the visual features and the linguistic features into the final label sequence by fully connected and softmax layers. The proposed model takes advantage of both visual and linguistic information from the input image. In the experiments, we evaluated the performance of the proposed model on the two datasets: Kuzushiji and SCUT-EPT. Experimental results show that the proposed model achieves state-of-the-art performance on all datasets.