 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new perspective of paramodulation complexity by solving massive 8 puzzles
Dec 15, 2020



A sliding puzzle is a combination puzzle where a player slide pieces along certain routes on a board to reach a certain end-configuration. In this paper, we propose a novel measurement of complexity of massive sliding puzzles with paramodulation which is an inference method of automated reasoning. It turned out that by counting the number of clauses yielded with paramodulation, we can evaluate the difficulty of each puzzle. In experiment, we have generated 100 * 8 puzzles which passed the solvability checking by countering inversions. By doing this, we can distinguish the complexity of 8 puzzles with the number of generated with paramodulation. For example, board [2,3,6,1,7,8,5,4, hole] is the easiest with score 3008 and board [6,5,8,7,4,3,2,1, hole] is the most difficult with score 48653. Besides, we have succeeded to obverse several layers of complexity (the number of clauses generated) in 100 puzzles. We can conclude that proposal method can provide a new perspective of paramodulation complexity concerning sliding block puzzles.
A Curious New Result of Resolution Strategies in Negation-Limited Inverters Problem
Nov 02, 2020



Generally, negation-limited inverters problem is known as a puzzle of constructing an inverter with AND gates and OR gates and a few inverters. In this paper, we introduce a curious new result about the effectiveness of two powerful ATP (Automated Theorem Proving) strategies on tackling negation limited inverter problem. Two resolution strategies are UR (Unit Resulting) resolution and hyper-resolution. In experiment, we come two kinds of automated circuit construction: 3 input/output inverters and 4 input/output BCD Counter Circuit. Both circuits are constructed with a few limited inverters. Curiously, it has been turned out that UR resolution is drastically faster than hyper-resolution in the measurement of the size of SOS (Set of Support). Besides, we discuss the syntactic and semantic criteria which might causes considerable difference of computation cost between UR resolution and hyper-resolution.
A constrained recursion algorithm for batch normalization of tree-sturctured LSTM
Aug 21, 2020



Tree-structured LSTM is promising way to consider long-distance interaction over hierarchies. However, there have been few research efforts on the hyperparameter tuning of the construction and traversal of tree-structured LSTM. To name a few, hyperparamters such as the interval of state initialization, the number of batches for normalization have been left unexplored specifically in applying batch normalization for reducing training cost and parallelization. In this paper, we propose a novel recursive algorithm for traversing batch normalized tree-structured LSTM. In proposal method, we impose the constraint on the recursion algorithm for the depth-first search of binary tree representation of LSTM for which batch normalization is applied. With our constrained recursion, we can control the hyperparameter in the traversal of several tree-structured LSTMs which is generated in the process of batch normalization. The tree traversal is divided into two steps. At first stage, the width-first search over models is applied for discover the start point of the latest tree-structured LSTM block. Then, the depth-first search is run to traverse tree-structured LSTM. Proposed method enables us to explore the optimized selection of hyperparameters of recursive neural network implementation by changing the constraints of our recursion algorithm. In experiment, we measure and plot the validation loss and computing time with changing the length of internal of state initialization of tree-structured LSTM. It has been turned out that proposal method is effective for hyperparameter tuning such as the number of batches and length of interval of state initialization of tree-structured LSTM.
Wikipedia2Vec: An Optimized Tool for Learning Embeddings of Words and Entities from Wikipedia
Dec 26, 2018
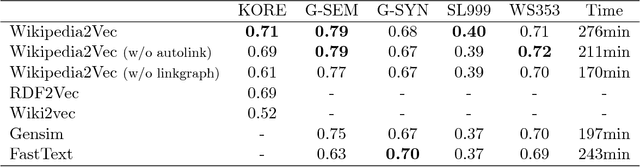
We present Wikipedia2Vec, an open source tool for learning embeddings of words and entities from Wikipedia. This tool enables users to easily obtain high-quality embeddings of words and entities from a Wikipedia dump with a single command. The learned embeddings can be used as features in downstream natural language processing (NLP) models. The tool can be installed via PyPI. The source code, documentation, and pretrained embeddings for 12 major languages can be obtained at http://wikipedia2vec.github.io.
Representation Learning of Entities and Documents from Knowledge Base Descriptions
Jun 08, 2018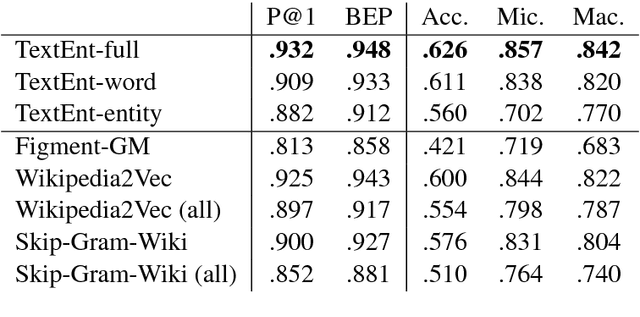
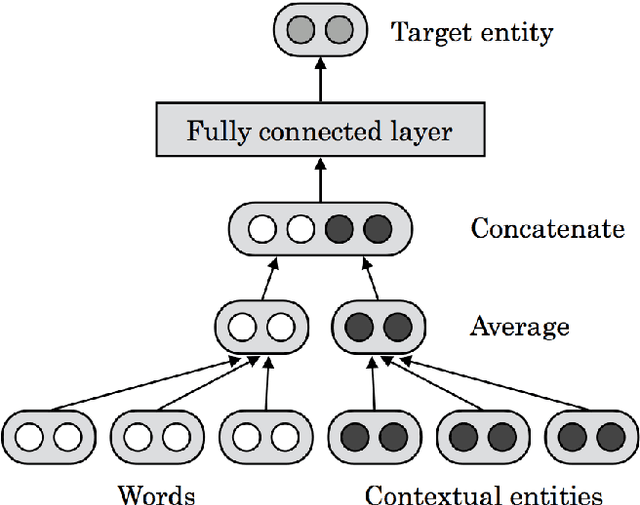
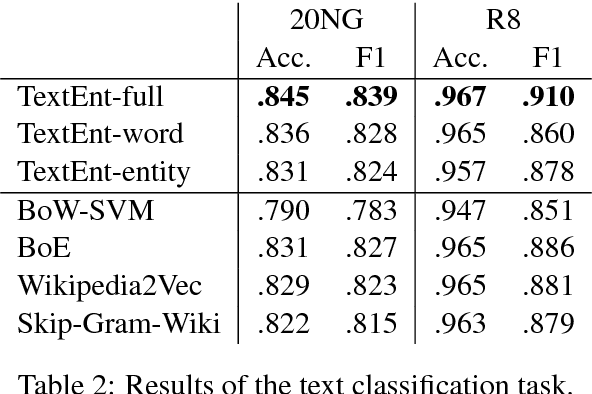
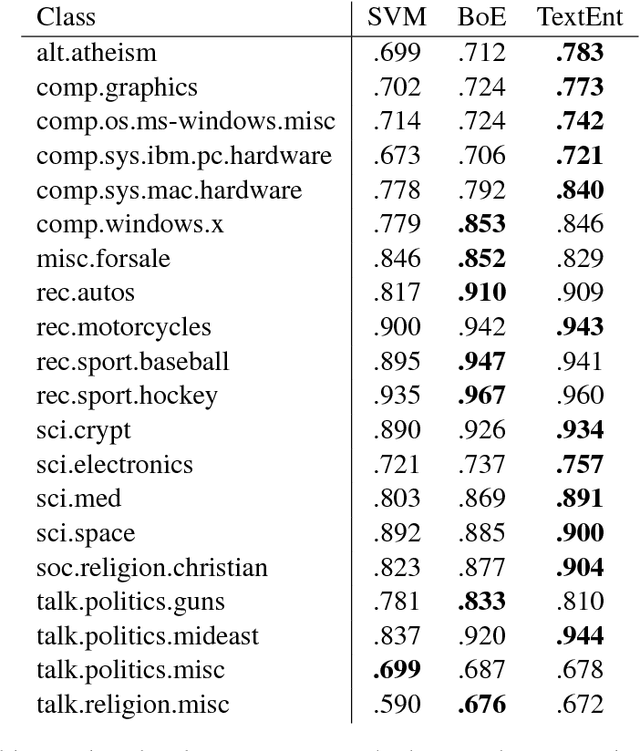
In this paper, we describe TextEnt, a neural network model that learns distributed representations of entities and documents directly from a knowledge base (KB). Given a document in a KB consisting of words and entity annotations, we train our model to predict the entity that the document describes and map the document and its target entity close to each other in a continuous vector space. Our model is trained using a large number of documents extracted from Wikipedia. The performance of the proposed model is evaluated using two tasks, namely fine-grained entity typing and multiclass text classification. The results demonstrate that our model achieves state-of-the-art performance on both tasks. The code and the trained representations are made available online for further academic research.
Studio Ousia's Quiz Bowl Question Answering System
Mar 23, 2018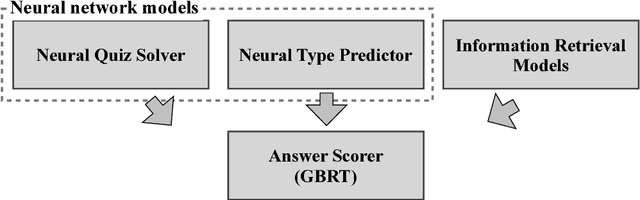
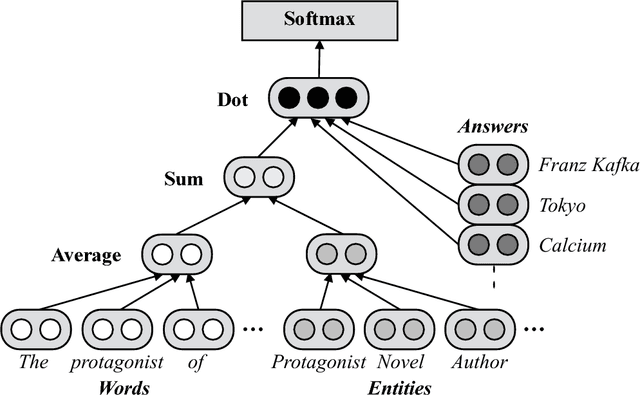
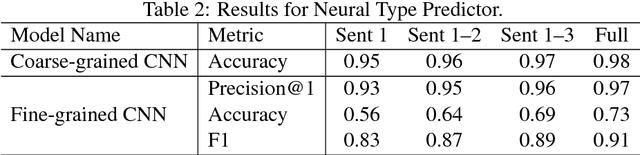
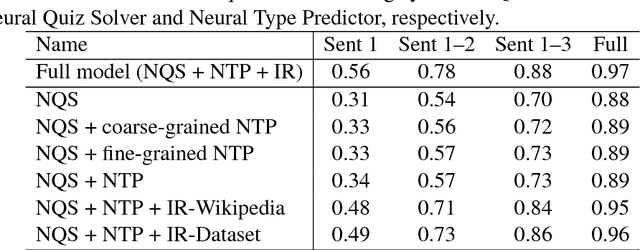
In this chapter, we describe our question answering system, which was the winning system at the Human-Computer Question Answering (HCQA) Competition at the Thirty-first Annual Conference on Neural Information Processing Systems (NIPS). The competition requires participants to address a factoid question answering task referred to as quiz bowl. To address this task, we use two novel neural network models and combine these models with conventional information retrieval models using a supervised machine learning model. Our system achieved the best performance among the systems submitted in the competition and won a match against six top human quiz experts by a wide margin.
Learning Distributed Representations of Texts and Entities from Knowledge Base
Nov 07, 2017We describe a neural network model that jointly learns distributed representations of texts and knowledge base (KB) entities. Given a text in the KB, we train our proposed model to predict entities that are relevant to the text. Our model is designed to be generic with the ability to address various NLP tasks with ease. We train the model using a large corpus of texts and their entity annotations extracted from Wikipedia. We evaluated the model on three important NLP tasks (i.e., sentence textual similarity, entity linking, and factoid question answering) involving both unsupervised and supervised settings. As a result, we achieved state-of-the-art results on all three of these tasks. Our code and trained models are publicly available for further academic research.
Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation
Jun 10, 2016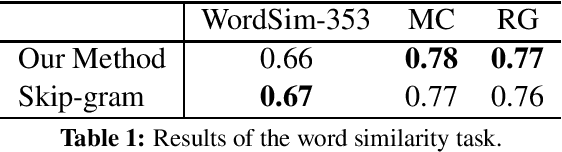

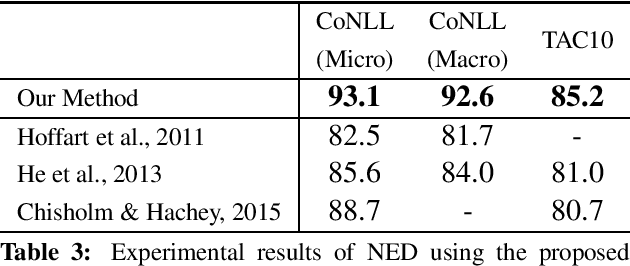
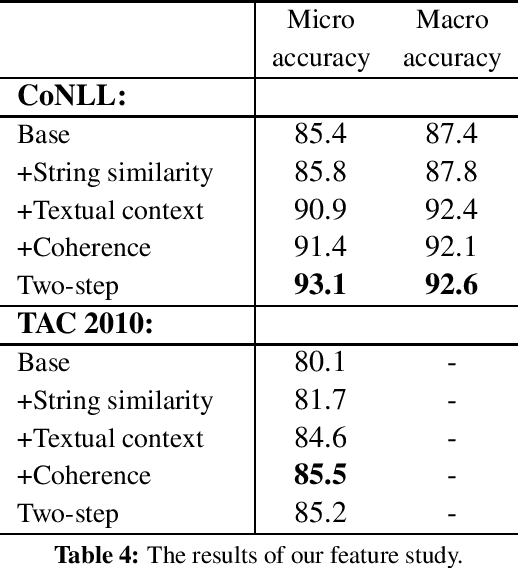
Named Entity Disambiguation (NED) refers to the task of resolving multiple named entity mentions in a document to their correct references in a knowledge base (KB) (e.g., Wikipedia). In this paper, we propose a novel embedding method specifically designed for NED. The proposed method jointly maps words and entities into the same continuous vector space. We extend the skip-gram model by using two models. The KB graph model learns the relatedness of entities using the link structure of the KB, whereas the anchor context model aims to align vectors such that similar words and entities occur close to one another in the vector space by leveraging KB anchors and their context words. By combining contexts based on the proposed embedding with standard NED features, we achieved state-of-the-art accuracy of 93.1% on the standard CoNLL dataset and 85.2% on the TAC 2010 dataset.