 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegSwin: Gated MLP Vision Model with Hierarchical Structure of Shifted Window
Paper and Code
Aug 24, 2022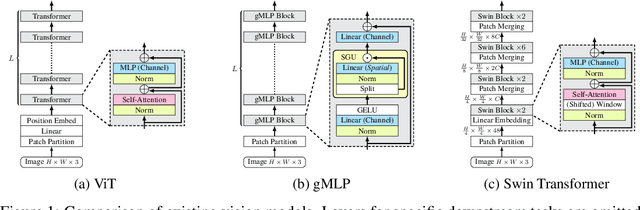
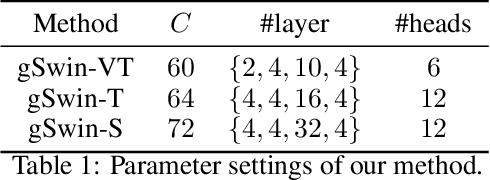

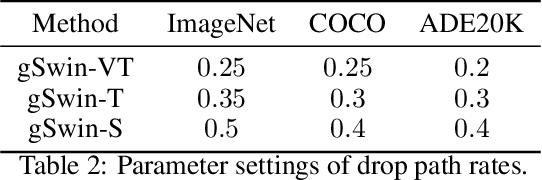
Following the success in language domain, the self-attention mechanism (transformer) is adopted in the vision domain and achieving great success recently. Additionally, as another stream, multi-layer perceptron (MLP) is also explored in the vision domain. These architectures, other than traditional CNNs, have been attracting attention recently, and many methods have been proposed. As one that combines parameter efficiency and performance with locality and hierarchy in image recognition, we propose gSwin, which merges the two streams; Swin Transformer and (multi-head) gMLP. We showed that our gSwin can achieve better accuracy on three vision tasks, image classification, object detection and semantic segmentation, than Swin Transformer, with smaller model size.