 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Experimental Design for Policy Learning
Jan 09, 2024Evidence-based targeting has been a topic of growing interest among the practitioners of policy and business. Formulating decision-maker's policy learning as a fixed-budget best arm identification (BAI) problem with contextual information, we study an optimal adaptive experimental design for policy learning with multiple treatment arms. In the sampling stage, the planner assigns treatment arms adaptively over sequentially arriving experimental units upon observing their contextual information (covariates). After the experiment, the planner recommends an individualized assignment rule to the population. Setting the worst-case expected regret as the performance criterion of adaptive sampling and recommended policies, we derive its asymptotic lower bounds, and propose a strategy, Adaptive Sampling-Policy Learning strategy (PLAS), whose leading factor of the regret upper bound aligns with the lower bound as the size of experimental units increases.
Asymptotically Minimax Optimal Fixed-Budget Best Arm Identification for Expected Simple Regret Minimization
Feb 06, 2023We investigate fixed-budget best arm identification (BAI) for expected simple regret minimization. In each round of an adaptive experiment, a decision maker draws one of multiple treatment arms based on past observations and subsequently observes the outcomes of the chosen arm. After the experiment, the decision maker recommends a treatment arm with the highest projected outcome. We evaluate this decision in terms of the expected simple regret, a difference between the expected outcomes of the best and recommended treatment arms. Due to the inherent uncertainty, we evaluate the regret using the minimax criterion. For distributions with fixed variances (location-shift models), such as Gaussian distributions, we derive asymptotic lower bounds for the worst-case expected simple regret. Then, we show that the Random Sampling (RS)-Augmented Inverse Probability Weighting (AIPW) strategy proposed by Kato et al. (2022) is asymptotically minimax optimal in the sense that the leading factor of its worst-case expected simple regret asymptotically matches our derived worst-case lower bound. Our result indicates that, for location-shift models, the optimal RS-AIPW strategy draws treatment arms with varying probabilities based on their variances. This result contrasts with the results of Bubeck et al. (2011), which shows that drawing each treatment arm with an equal ratio is minimax optimal in a bounded outcome setting.
Semiparametric Best Arm Identification with Contextual Information
Sep 19, 2022We study best-arm identification with a fixed budget and contextual (covariate) information in stochastic multi-armed bandit problems. In each round, after observing contextual information, we choose a treatment arm using past observations and current context. Our goal is to identify the best treatment arm, a treatment arm with the maximal expected reward marginalized over the contextual distribution, with a minimal probability of misidentification. First, we derive semiparametric lower bounds for this problem, where we regard the gaps between the expected rewards of the best and suboptimal treatment arms as parameters of interest, and all other parameters, such as the expected rewards conditioned on contexts, as the nuisance parameters. We then develop the "Contextual RS-AIPW strategy," which consists of the random sampling (RS) rule tracking a target allocation ratio and the recommendation rule using the augmented inverse probability weighting (AIPW) estimator. Our proposed Contextual RS-AIPW strategy is optimal because the upper bound for the probability of misidentification matches the semiparametric lower bound when the budget goes to infinity, and the gaps converge to zero.
Adaptive Experimental Design for Efficient Treatment Effect Estimation: Randomized Allocation via Contextual Bandit Algorithm
Feb 13, 2020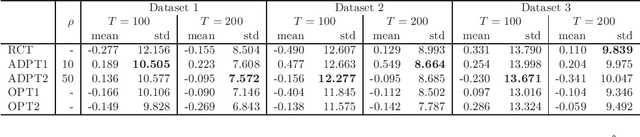
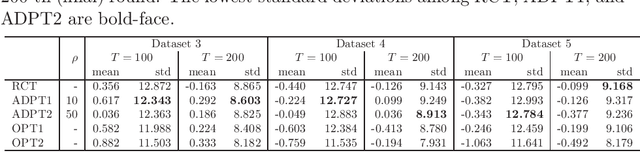


Many scientific experiments have an interest in the estimation of the average treatment effect (ATE), which is defined as the difference between the expected outcomes of two or more treatments. In this paper, we consider a situation called adaptive experimental design where research subjects sequentially visit a researcher, and the researcher assigns a treatment. For estimating the ATE efficiently, we consider changing the probability of assigning a treatment at a period by using past information obtained until the period. However, in this approach, it is difficult to apply the standard statistical method to construct an estimator because the observations are not independent and identically distributed. In this paper, to construct an efficient estimator, we overcome this conventional problem by using an algorithm of the multi-armed bandit problem and the theory of martingale. In the proposed method, we use the probability of assigning a treatment that minimizes the asymptotic variance of an estimator of the ATE. We also elucidate the theoretical properties of an estimator obtained from the proposed algorithm for both infinite and finite samples. Finally, we experimentally show that the proposed algorithm outperforms the standard RCT in some cases.