 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Experimental Design for Policy Learning
Jan 09, 2024Evidence-based targeting has been a topic of growing interest among the practitioners of policy and business. Formulating decision-maker's policy learning as a fixed-budget best arm identification (BAI) problem with contextual information, we study an optimal adaptive experimental design for policy learning with multiple treatment arms. In the sampling stage, the planner assigns treatment arms adaptively over sequentially arriving experimental units upon observing their contextual information (covariates). After the experiment, the planner recommends an individualized assignment rule to the population. Setting the worst-case expected regret as the performance criterion of adaptive sampling and recommended policies, we derive its asymptotic lower bounds, and propose a strategy, Adaptive Sampling-Policy Learning strategy (PLAS), whose leading factor of the regret upper bound aligns with the lower bound as the size of experimental units increases.
Counterfactual Learning with General Data-generating Policies
Dec 04, 2022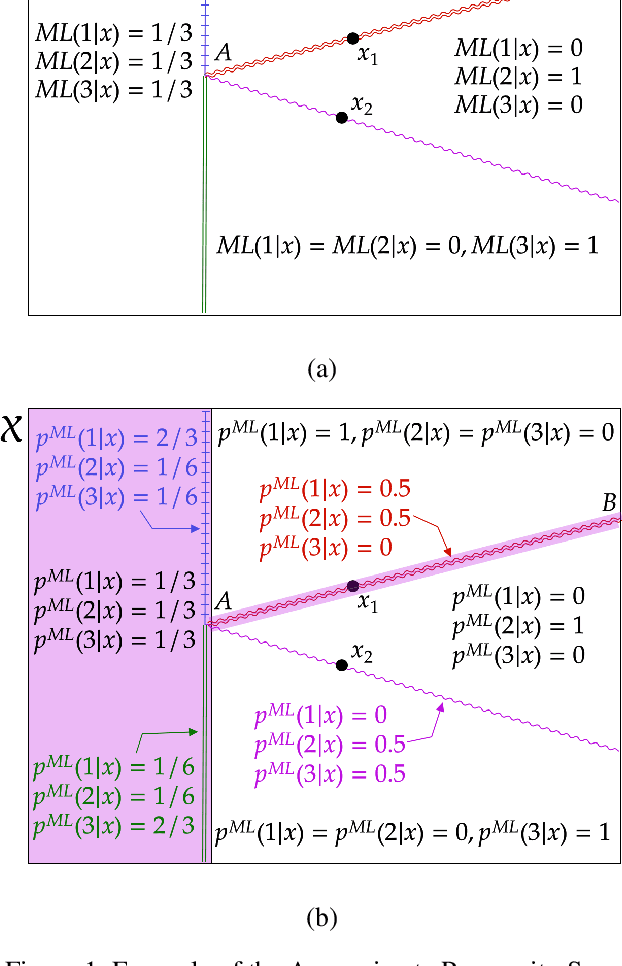
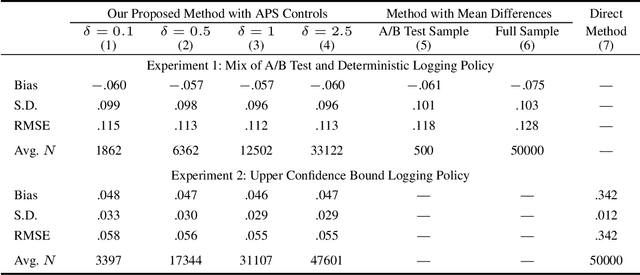
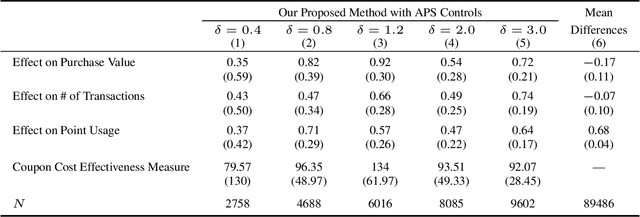
Off-policy evaluation (OPE) attempts to predict the performance of counterfactual policies using log data from a different policy. We extend its applicability by developing an OPE method for a class of both full support and deficient support logging policies in contextual-bandit settings. This class includes deterministic bandit (such as Upper Confidence Bound) as well as deterministic decision-making based on supervised and unsupervised learning. We prove that our method's prediction converges in probability to the true performance of a counterfactual policy as the sample size increases. We validate our method with experiments on partly and entirely deterministic logging policies. Finally, we apply it to evaluate coupon targeting policies by a major online platform and show how to improve the existing policy.