 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Learning with General Data-generating Policies
Paper and Code
Dec 04, 2022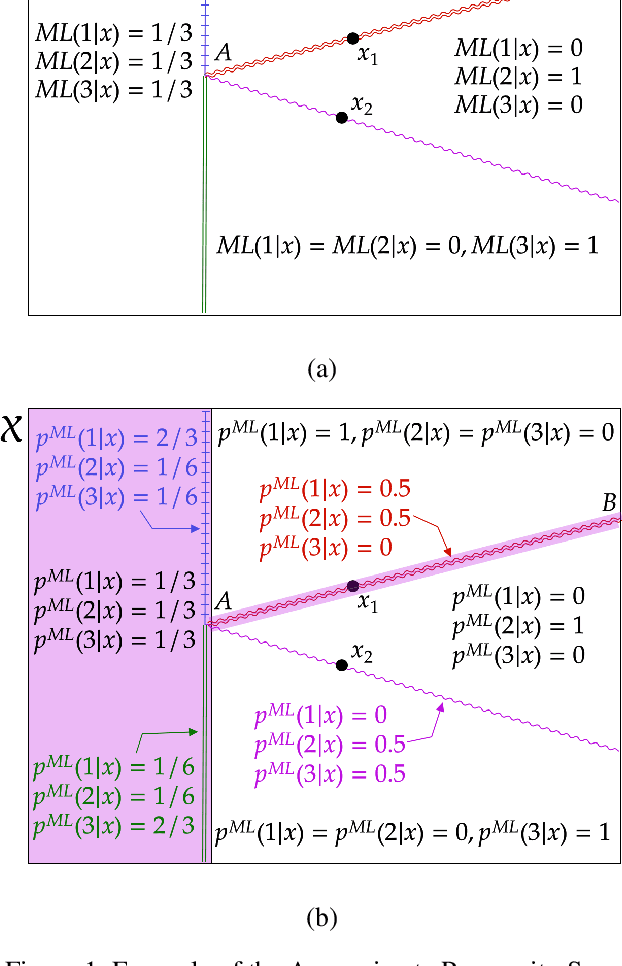
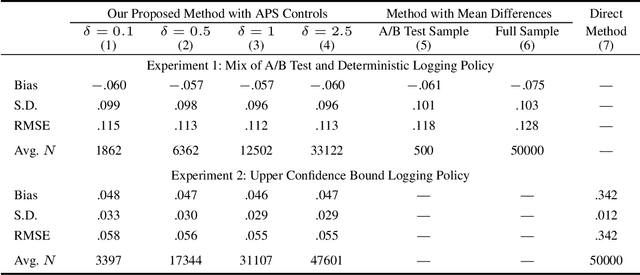
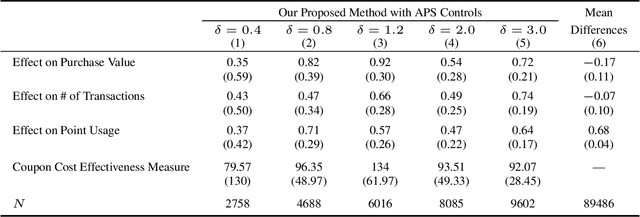
Off-policy evaluation (OPE) attempts to predict the performance of counterfactual policies using log data from a different policy. We extend its applicability by developing an OPE method for a class of both full support and deficient support logging policies in contextual-bandit settings. This class includes deterministic bandit (such as Upper Confidence Bound) as well as deterministic decision-making based on supervised and unsupervised learning. We prove that our method's prediction converges in probability to the true performance of a counterfactual policy as the sample size increases. We validate our method with experiments on partly and entirely deterministic logging policies. Finally, we apply it to evaluate coupon targeting policies by a major online platform and show how to improve the existing policy.