 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Feb 03, 2022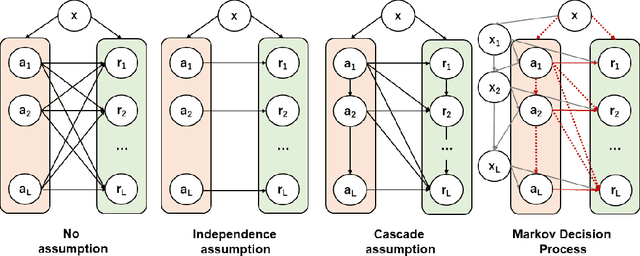
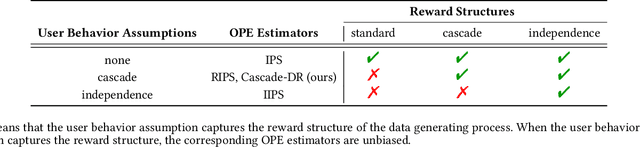

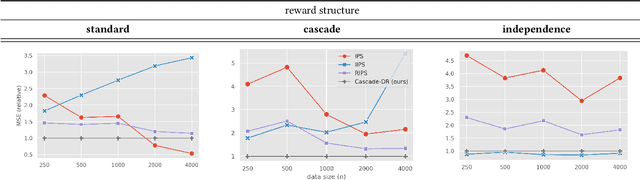
In real-world recommender systems and search engines, optimizing ranking decisions to present a ranked list of relevant items is critical. Off-policy evaluation (OPE) for ranking policies is thus gaining a growing interest because it enables performance estimation of new ranking policies using only logged data. Although OPE in contextual bandits has been studied extensively, its naive application to the ranking setting faces a critical variance issue due to the huge item space. To tackle this problem, previous studies introduce some assumptions on user behavior to make the combinatorial item space tractable. However, an unrealistic assumption may, in turn, cause serious bias. Therefore, appropriately controlling the bias-variance tradeoff by imposing a reasonable assumption is the key for success in OPE of ranking policies. To achieve a well-balanced bias-variance tradeoff, we propose the Cascade Doubly Robust estimator building on the cascade assumption, which assumes that a user interacts with items sequentially from the top position in a ranking. We show that the proposed estimator is unbiased in more cases compared to existing estimators that make stronger assumptions. Furthermore, compared to a previous estimator based on the same cascade assumption, the proposed estimator reduces the variance by leveraging a control variate. Comprehensive experiments on both synthetic and real-world data demonstrate that our estimator leads to more accurate OPE than existing estimators in a variety of settings.