 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Average: Distributional Causal Inference under Imperfect Compliance
Sep 19, 2025We study the estimation of distributional treatment effects in randomized experiments with imperfect compliance. When participants do not adhere to their assigned treatments, we leverage treatment assignment as an instrumental variable to identify the local distributional treatment effect-the difference in outcome distributions between treatment and control groups for the subpopulation of compliers. We propose a regression-adjusted estimator based on a distribution regression framework with Neyman-orthogonal moment conditions, enabling robustness and flexibility with high-dimensional covariates. Our approach accommodates continuous, discrete, and mixed discrete-continuous outcomes, and applies under a broad class of covariate-adaptive randomization schemes, including stratified block designs and simple random sampling. We derive the estimator's asymptotic distribution and show that it achieves the semiparametric efficiency bound. Simulation results demonstrate favorable finite-sample performance, and we demonstrate the method's practical relevance in an application to the Oregon Health Insurance Experiment.
Efficient and Scalable Estimation of Distributional Treatment Effects with Multi-Task Neural Networks
Jul 10, 2025We propose a novel multi-task neural network approach for estimating distributional treatment effects (DTE) in randomized experiments. While DTE provides more granular insights into the experiment outcomes over conventional methods focusing on the Average Treatment Effect (ATE), estimating it with regression adjustment methods presents significant challenges. Specifically, precision in the distribution tails suffers due to data imbalance, and computational inefficiencies arise from the need to solve numerous regression problems, particularly in large-scale datasets commonly encountered in industry. To address these limitations, our method leverages multi-task neural networks to estimate conditional outcome distributions while incorporating monotonic shape constraints and multi-threshold label learning to enhance accuracy. To demonstrate the practical effectiveness of our proposed method, we apply our method to both simulated and real-world datasets, including a randomized field experiment aimed at reducing water consumption in the US and a large-scale A/B test from a leading streaming platform in Japan. The experimental results consistently demonstrate superior performance across various datasets, establishing our method as a robust and practical solution for modern causal inference applications requiring a detailed understanding of treatment effect heterogeneity.
On Efficient Estimation of Distributional Treatment Effects under Covariate-Adaptive Randomization
Jun 06, 2025This paper focuses on the estimation of distributional treatment effects in randomized experiments that use covariate-adaptive randomization (CAR). These include designs such as Efron's biased-coin design and stratified block randomization, where participants are first grouped into strata based on baseline covariates and assigned treatments within each stratum to ensure balance across groups. In practice, datasets often contain additional covariates beyond the strata indicators. We propose a flexible distribution regression framework that leverages off-the-shelf machine learning methods to incorporate these additional covariates, enhancing the precision of distributional treatment effect estimates. We establish the asymptotic distribution of the proposed estimator and introduce a valid inference procedure. Furthermore, we derive the semiparametric efficiency bound for distributional treatment effects under CAR and demonstrate that our regression-adjusted estimator attains this bound. Simulation studies and empirical analyses of microcredit programs highlight the practical advantages of our method.
Estimating Distributional Treatment Effects in Randomized Experiments: Machine Learning for Variance Reduction
Jul 22, 2024We propose a novel regression adjustment method designed for estimating distributional treatment effect parameters in randomized experiments. Randomized experiments have been extensively used to estimate treatment effects in various scientific fields. However, to gain deeper insights, it is essential to estimate distributional treatment effects rather than relying solely on average effects. Our approach incorporates pre-treatment covariates into a distributional regression framework, utilizing machine learning techniques to improve the precision of distributional treatment effect estimators. The proposed approach can be readily implemented with off-the-shelf machine learning methods and remains valid as long as the nuisance components are reasonably well estimated. Also, we establish the asymptotic properties of the proposed estimator and present a uniformly valid inference method. Through simulation results and real data analysis, we demonstrate the effectiveness of integrating machine learning techniques in reducing the variance of distributional treatment effect estimators in finite samples.
Automatic Debiased Learning from Positive, Unlabeled, and Exposure Data
Mar 08, 2023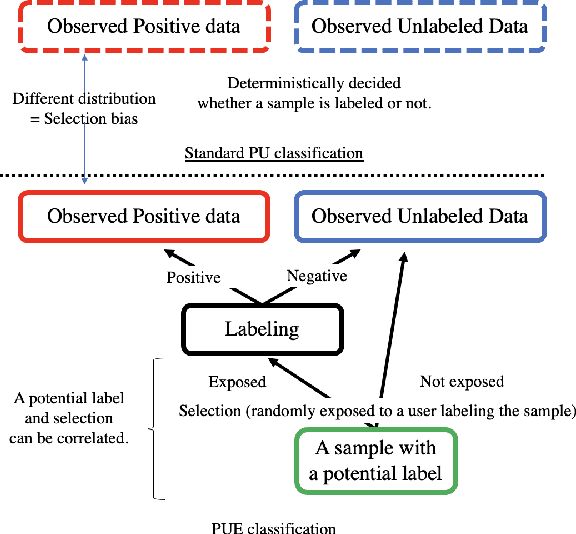

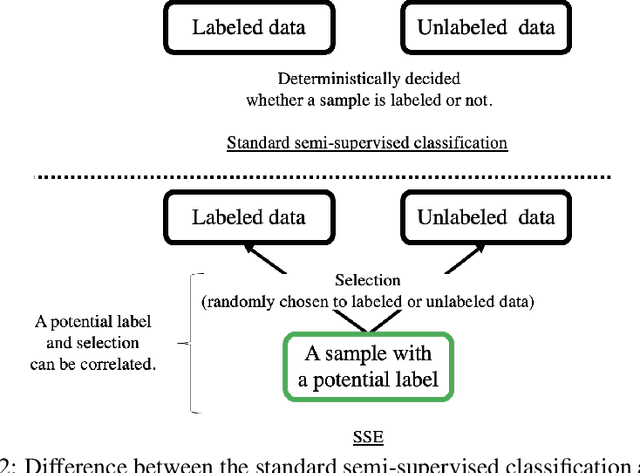
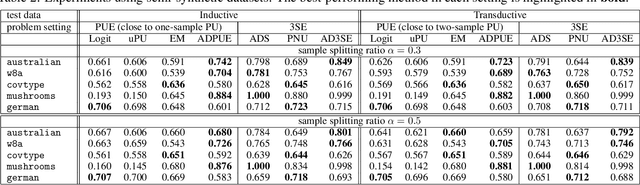
We address the issue of binary classification from positive and unlabeled data (PU classification) with a selection bias in the positive data. During the observation process, (i) a sample is exposed to a user, (ii) the user then returns the label for the exposed sample, and (iii) we however can only observe the positive samples. Therefore, the positive labels that we observe are a combination of both the exposure and the labeling, which creates a selection bias problem for the observed positive samples. This scenario represents a conceptual framework for many practical applications, such as recommender systems, which we refer to as ``learning from positive, unlabeled, and exposure data'' (PUE classification). To tackle this problem, we initially assume access to data with exposure labels. Then, we propose a method to identify the function of interest using a strong ignorability assumption and develop an ``Automatic Debiased PUE'' (ADPUE) learning method. This algorithm directly debiases the selection bias without requiring intermediate estimates, such as the propensity score, which is necessary for other learning methods. Through experiments, we demonstrate that our approach outperforms traditional PU learning methods on various semi-synthetic datasets.
Learning Causal Relationships from Conditional Moment Conditions by Importance Weighting
Aug 03, 2021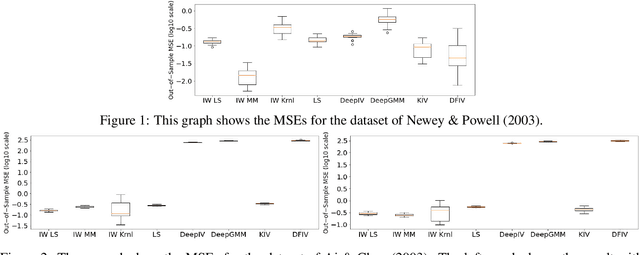



We consider learning causal relationships under conditional moment conditions. Unlike causal inference under unconditional moment conditions, conditional moment conditions pose serious challenges for causal inference, especially in complex, high-dimensional settings. To address this issue, we propose a method that transforms conditional moment conditions to unconditional moment conditions through importance weighting using the conditional density ratio. Then, using this transformation, we propose a method that successfully approximates conditional moment conditions. Our proposed approach allows us to employ methods for estimating causal parameters from unconditional moment conditions, such as generalized method of moments, adequately in a straightforward manner. In experiments, we confirm that our proposed method performs well compared to existing methods.
A Practical Guide of Off-Policy Evaluation for Bandit Problems
Oct 23, 2020


Off-policy evaluation (OPE) is the problem of estimating the value of a target policy from samples obtained via different policies. Recently, applying OPE methods for bandit problems has garnered attention. For the theoretical guarantees of an estimator of the policy value, the OPE methods require various conditions on the target policy and policy used for generating the samples. However, existing studies did not carefully discuss the practical situation where such conditions hold, and the gap between them remains. This paper aims to show new results for bridging the gap. Based on the properties of the evaluation policy, we categorize OPE situations. Then, among practical applications, we mainly discuss the best policy selection. For the situation, we propose a meta-algorithm based on existing OPE estimators. We investigate the proposed concepts using synthetic and open real-world datasets in experiments.
Learning Classifiers under Delayed Feedback with a Time Window Assumption
Sep 28, 2020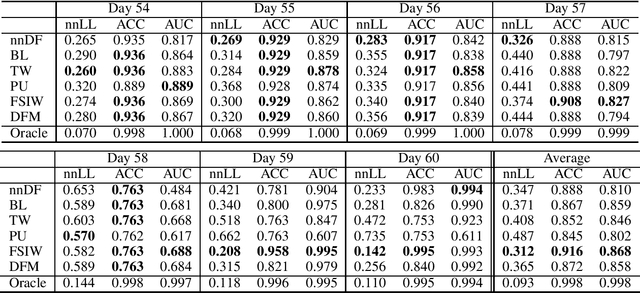

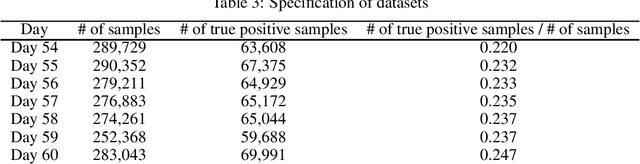
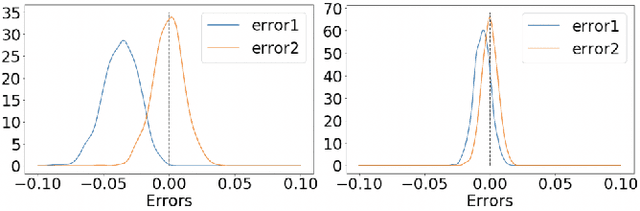
We consider training a binary classifier under delayed feedback (DF Learning). In DF Learning, we first receive negative samples; subsequently, some samples turn positive. This problem is conceivable in various real-world applications such as online advertisements, where the user action takes place long after the first click. Owing to the delayed feedback, simply separating the positive and negative data causes a sample selection bias. One solution is to assume that a long time window after first observing a sample reduces the sample selection bias. However, existing studies report that only using a portion of all samples based on the time window assumption yields suboptimal performance, and the use of all samples along with the time window assumption improves empirical performance. Extending these existing studies, we propose a method with an unbiased and convex empirical risk constructed from the whole samples under the time window assumption. We provide experimental results to demonstrate the effectiveness of the proposed method using a real traffic log dataset.
Off-Policy Evaluation and Learning for External Validity under a Covariate Shift
Feb 26, 2020

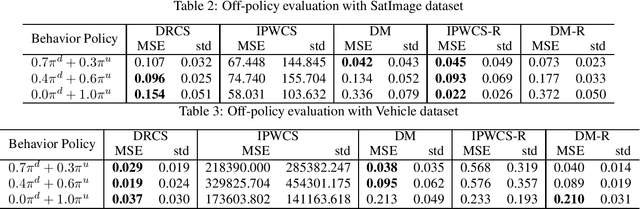
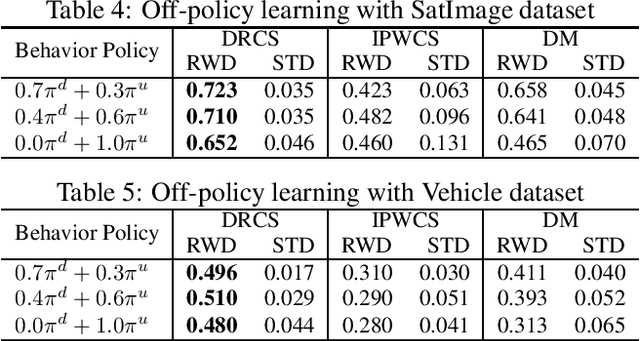
We consider the evaluation and training of a new policy for the evaluation data by using the historical data obtained from a different policy. The goal of off-policy evaluation (OPE) is to estimate the expected reward of a new policy over the evaluation data, and that of off-policy learning (OPL) is to find a new policy that maximizes the expected reward over the evaluation data. Although the standard OPE and OPL assume the same distribution of covariate between the historical and evaluation data, there often exists a problem of a covariate shift, i.e., the distribution of the covariate of the historical data is different from that of the evaluation data. In this paper, we derive the efficiency bound of OPE under a covariate shift. Then, we propose doubly robust and efficient estimators for OPE and OPL under a covariate shift by using an estimator of the density ratio between the distributions of the historical and evaluation data. We also discuss other possible estimators and compare their theoretical properties. Finally, we confirm the effectiveness of the proposed estimators through experiments.
Safe Counterfactual Reinforcement Learning
Feb 20, 2020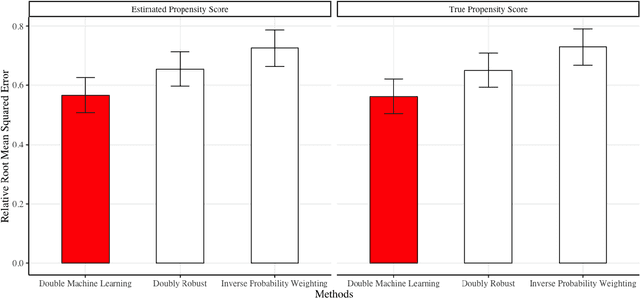


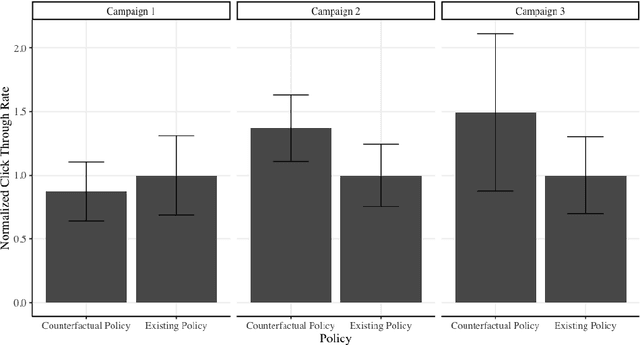
We develop a method for predicting the performance of reinforcement learning and bandit algorithms, given historical data that may have been generated by a different algorithm. Our estimator has the property that its prediction converges in probability to the true performance of a counterfactual algorithm at the fast $\sqrt{N}$ rate, as the sample size $N$ increases. We also show a correct way to estimate the variance of our prediction, thus allowing the analyst to quantify the uncertainty in the prediction. These properties hold even when the analyst does not know which among a large number of potentially important state variables are really important. These theoretical guarantees make our estimator safe to use. We finally apply it to improve advertisement design by a major advertisement company. We find that our method produces smaller mean squared errors than state-of-the-art methods.