 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Debiased Learning from Positive, Unlabeled, and Exposure Data
Paper and Code
Mar 08, 2023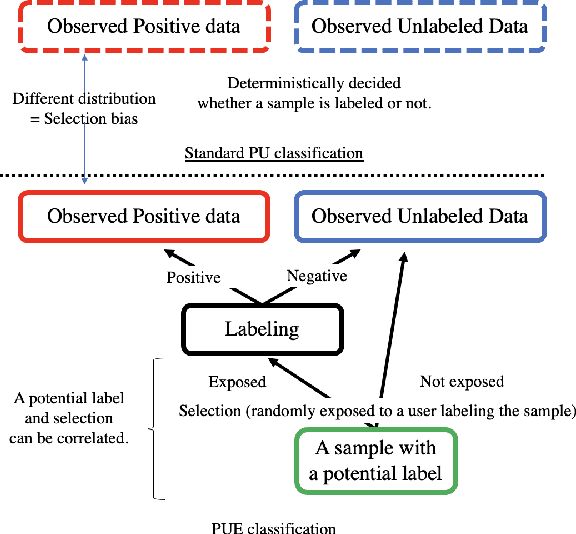

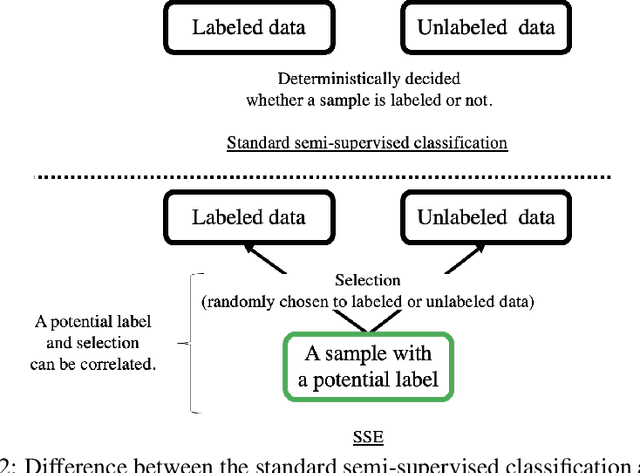
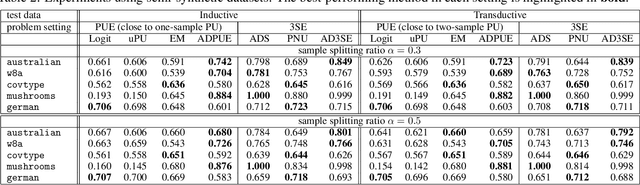
We address the issue of binary classification from positive and unlabeled data (PU classification) with a selection bias in the positive data. During the observation process, (i) a sample is exposed to a user, (ii) the user then returns the label for the exposed sample, and (iii) we however can only observe the positive samples. Therefore, the positive labels that we observe are a combination of both the exposure and the labeling, which creates a selection bias problem for the observed positive samples. This scenario represents a conceptual framework for many practical applications, such as recommender systems, which we refer to as ``learning from positive, unlabeled, and exposure data'' (PUE classification). To tackle this problem, we initially assume access to data with exposure labels. Then, we propose a method to identify the function of interest using a strong ignorability assumption and develop an ``Automatic Debiased PUE'' (ADPUE) learning method. This algorithm directly debiases the selection bias without requiring intermediate estimates, such as the propensity score, which is necessary for other learning methods. Through experiments, we demonstrate that our approach outperforms traditional PU learning methods on various semi-synthetic datasets.