Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect and Analysis of Large-scale Language Model Rescoring on Competitive ASR Systems
Apr 01, 2022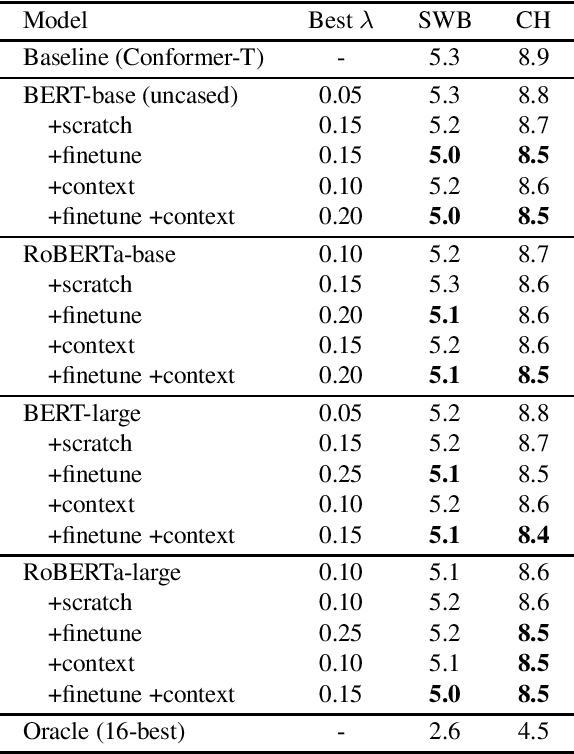
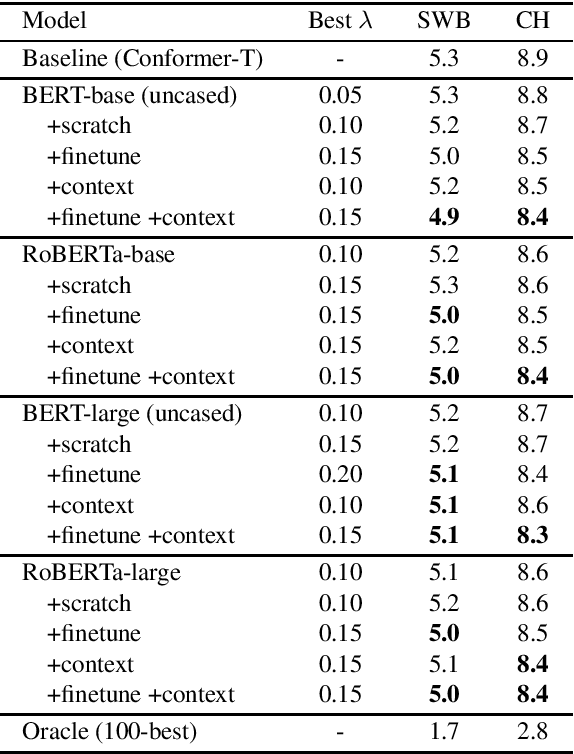
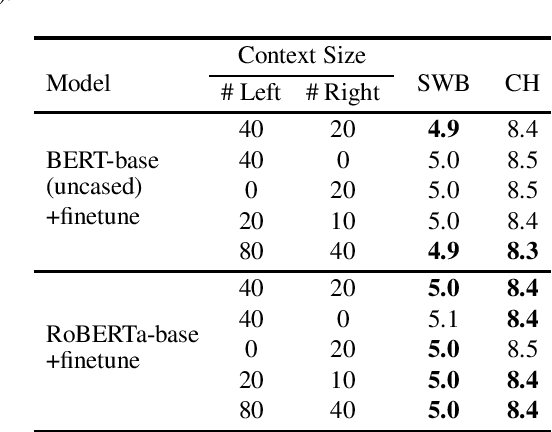
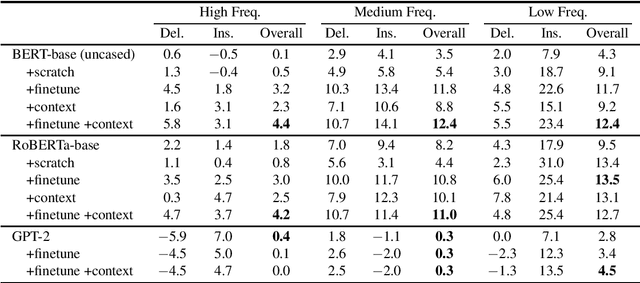
Large-scale language models (LLMs) such as GPT-2, BERT and RoBERTa have been successfully applied to ASR N-best rescoring. However, whether or how they can benefit competitive, near state-of-the-art ASR systems remains unexplored. In this study, we incorporate LLM rescoring into one of the most competitive ASR baselines: the Conformer-Transducer model. We demonstrate that consistent improvement is achieved by the LLM's bidirectionality, pretraining, in-domain finetuning and context augmentation. Furthermore, our lexical analysis sheds light on how each of these components may be contributing to the ASR performance.
* Submitted to Interspeech 2022
Via