 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Problem-Oriented Domain Adaptation Framework for Machine Learning
Jan 08, 2025Domain adaptation is a sub-field of machine learning that involves transferring knowledge from a source domain to perform the same task in the target domain. It is a typical challenge in machine learning that arises, e.g., when data is obtained from various sources or when using a data basis that changes over time. Recent advances in the field offer promising methods, but it is still challenging for researchers and practitioners to determine if domain adaptation is suitable for a given problem -- and, subsequently, to select the appropriate approach. This article employs design science research to develop a problem-oriented framework for domain adaptation, which is matured in three evaluation episodes. We describe a framework that distinguishes between five domain adaptation scenarios, provides recommendations for addressing each scenario, and offers guidelines for determining if a problem falls into one of these scenarios. During the multiple evaluation episodes, the framework is tested on artificial and real-world datasets and an experimental study involving 100 participants. The evaluation demonstrates that the framework has the explanatory power to capture any domain adaptation problem effectively. In summary, we provide clear guidance for researchers and practitioners who want to employ domain adaptation but lack in-depth knowledge of the possibilities.
On the Effect of Contextual Information on Human Delegation Behavior in Human-AI collaboration
Jan 09, 2024The constantly increasing capabilities of artificial intelligence (AI) open new possibilities for human-AI collaboration. One promising approach to leverage existing complementary capabilities is allowing humans to delegate individual instances to the AI. However, enabling humans to delegate instances effectively requires them to assess both their own and the AI's capabilities in the context of the given task. In this work, we explore the effects of providing contextual information on human decisions to delegate instances to an AI. We find that providing participants with contextual information significantly improves the human-AI team performance. Additionally, we show that the delegation behavior changes significantly when participants receive varying types of contextual information. Overall, this research advances the understanding of human-AI interaction in human delegation and provides actionable insights for designing more effective collaborative systems.
Enabling Inter-organizational Analytics in Business Networks Through Meta Machine Learning
Mar 28, 2023



Successful analytics solutions that provide valuable insights often hinge on the connection of various data sources. While it is often feasible to generate larger data pools within organizations, the application of analytics within (inter-organizational) business networks is still severely constrained. As data is distributed across several legal units, potentially even across countries, the fear of disclosing sensitive information as well as the sheer volume of the data that would need to be exchanged are key inhibitors for the creation of effective system-wide solutions -- all while still reaching superior prediction performance. In this work, we propose a meta machine learning method that deals with these obstacles to enable comprehensive analyses within a business network. We follow a design science research approach and evaluate our method with respect to feasibility and performance in an industrial use case. First, we show that it is feasible to perform network-wide analyses that preserve data confidentiality as well as limit data transfer volume. Second, we demonstrate that our method outperforms a conventional isolated analysis and even gets close to a (hypothetical) scenario where all data could be shared within the network. Thus, we provide a fundamental contribution for making business networks more effective, as we remove a key obstacle to tap the huge potential of learning from data that is scattered throughout the network.
Deep Domain Adaptation for Detecting Bomb Craters in Aerial Images
Sep 22, 2022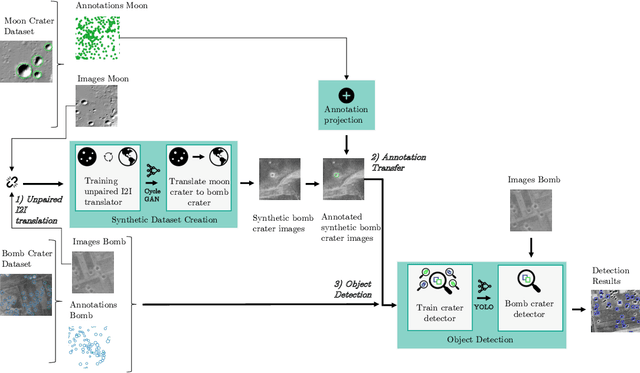



The aftermath of air raids can still be seen for decades after the devastating events. Unexploded ordnance (UXO) is an immense danger to human life and the environment. Through the assessment of wartime images, experts can infer the occurrence of a dud. The current manual analysis process is expensive and time-consuming, thus automated detection of bomb craters by using deep learning is a promising way to improve the UXO disposal process. However, these methods require a large amount of manually labeled training data. This work leverages domain adaptation with moon surface images to address the problem of automated bomb crater detection with deep learning under the constraint of limited training data. This paper contributes to both academia and practice (1) by providing a solution approach for automated bomb crater detection with limited training data and (2) by demonstrating the usability and associated challenges of using synthetic images for domain adaptation.
Deep Learning Strategies for Industrial Surface Defect Detection Systems
Sep 23, 2021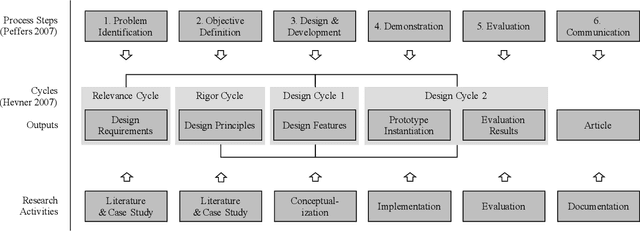

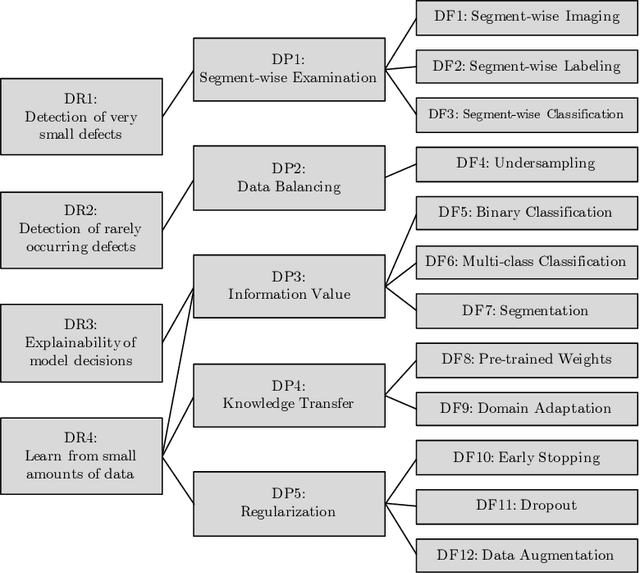

Deep learning methods have proven to outperform traditional computer vision methods in various areas of image processing. However, the application of deep learning in industrial surface defect detection systems is challenging due to the insufficient amount of training data, the expensive data generation process, the small size, and the rare occurrence of surface defects. From literature and a polymer products manufacturing use case, we identify design requirements which reflect the aforementioned challenges. Addressing these, we conceptualize design principles and features informed by deep learning research. Finally, we instantiate and evaluate the gained design knowledge in the form of actionable guidelines and strategies based on an industrial surface defect detection use case. This article, therefore, contributes to academia as well as practice by (1) systematically identifying challenges for the industrial application of deep learning-based surface defect detection, (2) strategies to overcome these, and (3) an experimental case study assessing the strategies' applicability and usefulness.
Human vs. supervised machine learning: Who learns patterns faster?
Nov 30, 2020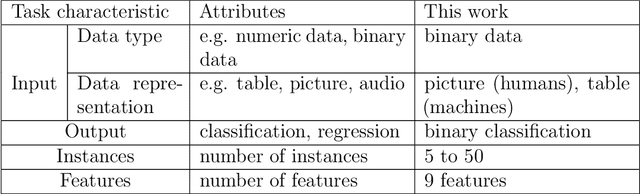
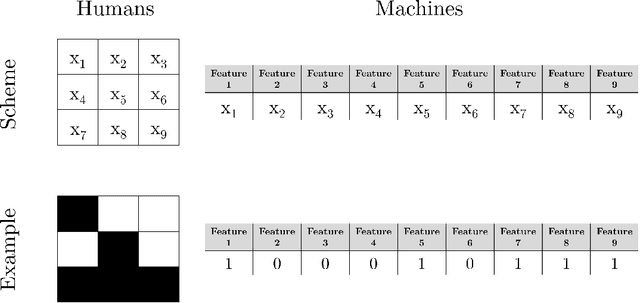
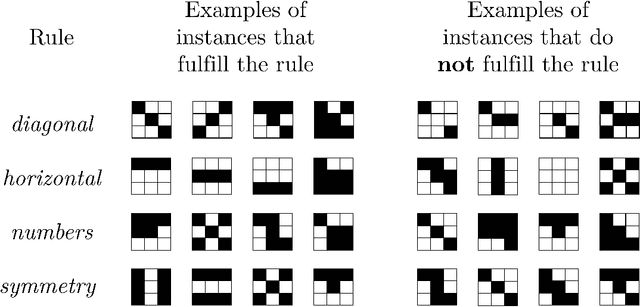
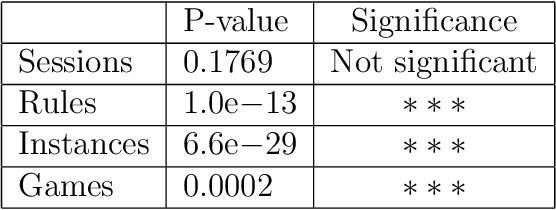
The capabilities of supervised machine learning (SML), especially compared to human abilities, are being discussed in scientific research and in the usage of SML. This study provides an answer to how learning performance differs between humans and machines when there is limited training data. We have designed an experiment in which 44 humans and three different machine learning algorithms identify patterns in labeled training data and have to label instances according to the patterns they find. The results show a high dependency between performance and the underlying patterns of the task. Whereas humans perform relatively similarly across all patterns, machines show large performance differences for the various patterns in our experiment. After seeing 20 instances in the experiment, human performance does not improve anymore, which we relate to theories of cognitive overload. Machines learn slower but can reach the same level or may even outperform humans in 2 of the 4 of used patterns. However, machines need more instances compared to humans for the same results. The performance of machines is comparably lower for the other 2 patterns due to the difficulty of combining input features.
A New Metric for Lumpy and Intermittent Demand Forecasts: Stock-keeping-oriented Prediction Error Costs
Apr 22, 2020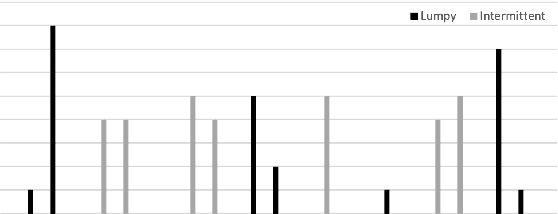

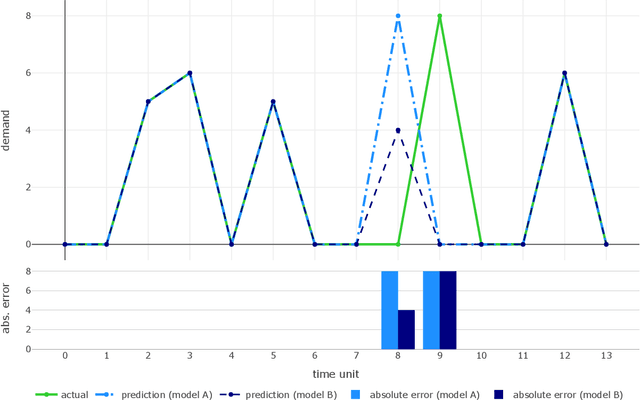
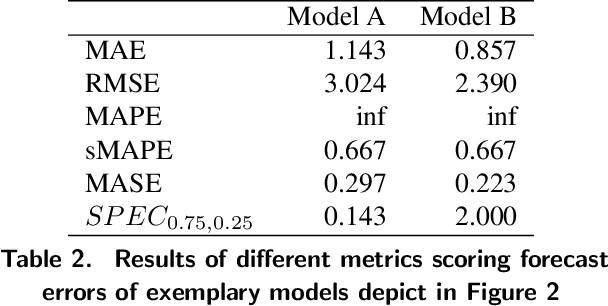
Forecasts of product demand are essential for short- and long-term optimization of logistics and production. Thus, the most accurate prediction possible is desirable. In order to optimally train predictive models, the deviation of the forecast compared to the actual demand needs to be assessed by a proper metric. However, if a metric does not represent the actual prediction error, predictive models are insufficiently optimized and, consequently, will yield inaccurate predictions. The most common metrics such as MAPE or RMSE, however, are not suitable for the evaluation of forecasting errors, especially for lumpy and intermittent demand patterns, as they do not sufficiently account for, e.g., temporal shifts (prediction before or after actual demand) or cost-related aspects. Therefore, we propose a novel metric that, in addition to statistical considerations, also addresses business aspects. Additionally, we evaluate the metric based on simulated and real demand time series from the automotive aftermarket.