 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Inter-organizational Analytics in Business Networks Through Meta Machine Learning
Mar 28, 2023



Successful analytics solutions that provide valuable insights often hinge on the connection of various data sources. While it is often feasible to generate larger data pools within organizations, the application of analytics within (inter-organizational) business networks is still severely constrained. As data is distributed across several legal units, potentially even across countries, the fear of disclosing sensitive information as well as the sheer volume of the data that would need to be exchanged are key inhibitors for the creation of effective system-wide solutions -- all while still reaching superior prediction performance. In this work, we propose a meta machine learning method that deals with these obstacles to enable comprehensive analyses within a business network. We follow a design science research approach and evaluate our method with respect to feasibility and performance in an industrial use case. First, we show that it is feasible to perform network-wide analyses that preserve data confidentiality as well as limit data transfer volume. Second, we demonstrate that our method outperforms a conventional isolated analysis and even gets close to a (hypothetical) scenario where all data could be shared within the network. Thus, we provide a fundamental contribution for making business networks more effective, as we remove a key obstacle to tap the huge potential of learning from data that is scattered throughout the network.
How to Learn from Others: Transfer Machine Learning with Additive Regression Models to Improve Sales Forecasting
May 15, 2020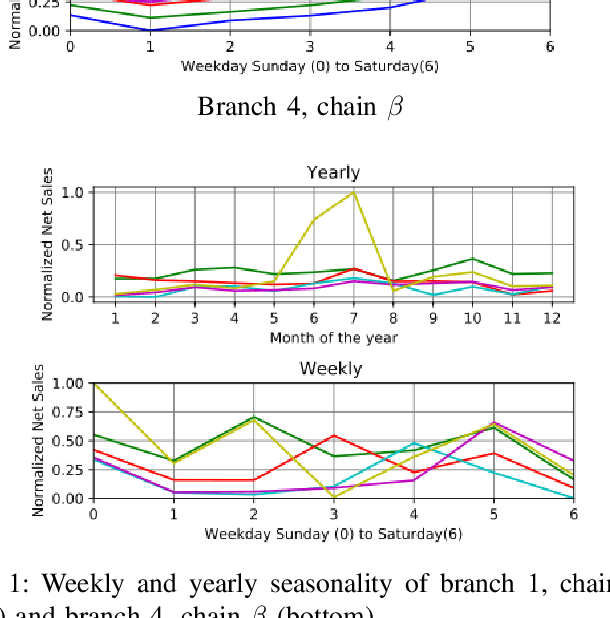
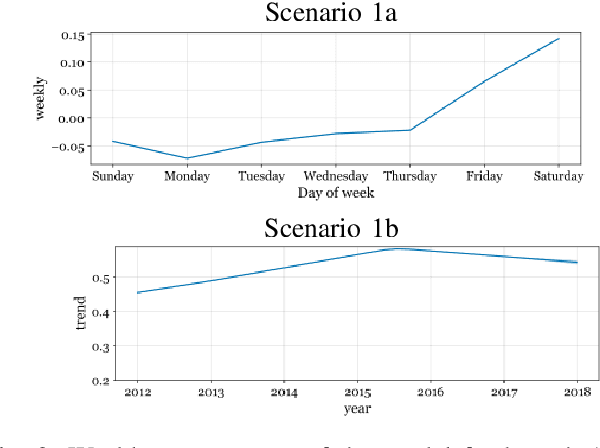
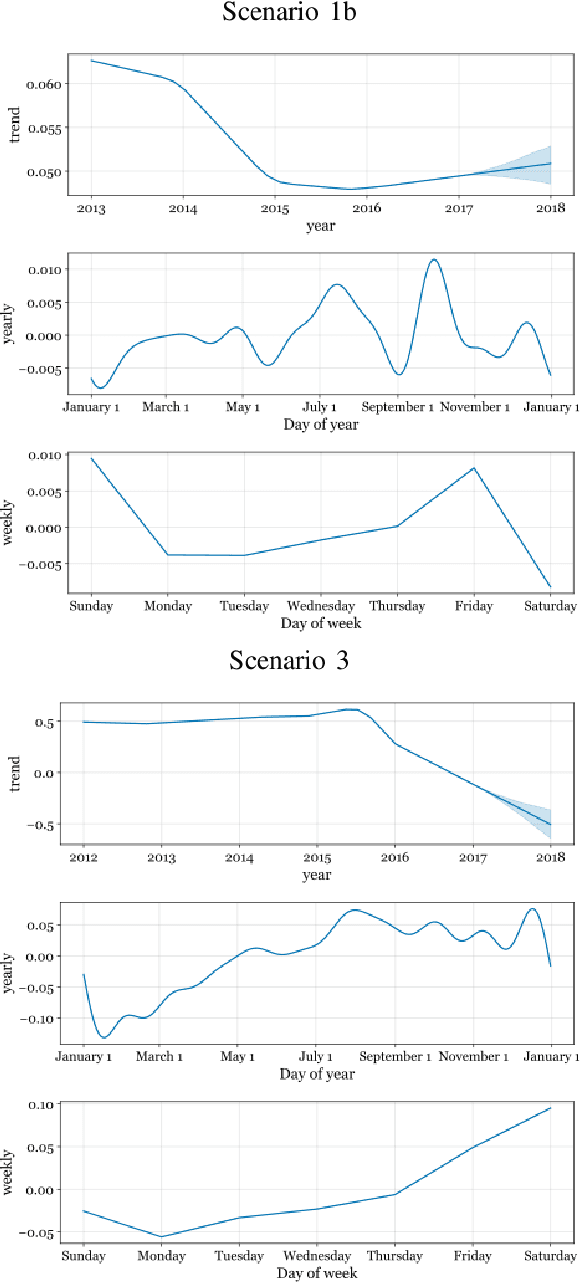
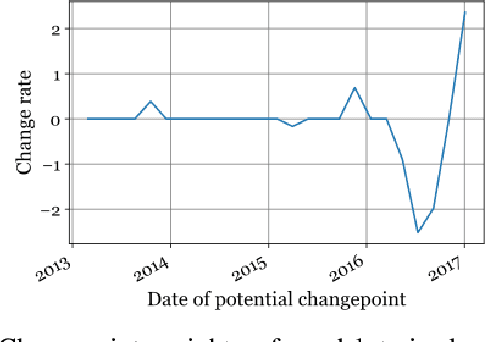
In a variety of business situations, the introduction or improvement of machine learning approaches is impaired as these cannot draw on existing analytical models. However, in many cases similar problems may have already been solved elsewhere-but the accumulated analytical knowledge cannot be tapped to solve a new problem, e.g., because of privacy barriers. For the particular purpose of sales forecasting for similar entities, we propose a transfer machine learning approach based on additive regression models that lets new entities benefit from models of existing entities. We evaluate the approach on a rich, multi-year dataset of multiple restaurant branches. We differentiate the options to simply transfer models from one branch to another ("zero shot") or to transfer and adapt them. We analyze feasibility and performance against several forecasting benchmarks. The results show the potential of the approach to exploit the collectively available analytical knowledge. Thus, we contribute an approach that is generalizable beyond sales forecasting and the specific use case in particular. In addition, we demonstrate its feasibility for a typical use case as well as the potential for improving forecasting quality. These results should inform academia, as they help to leverage knowledge across various entities, and have immediate practical application in industry.
A network-based transfer learning approach to improve sales forecasting of new products
May 13, 2020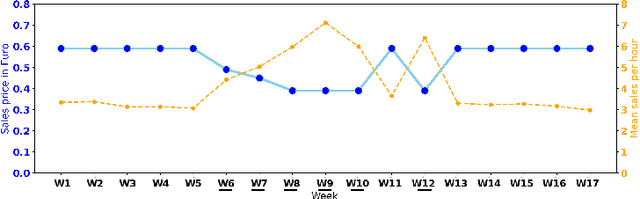

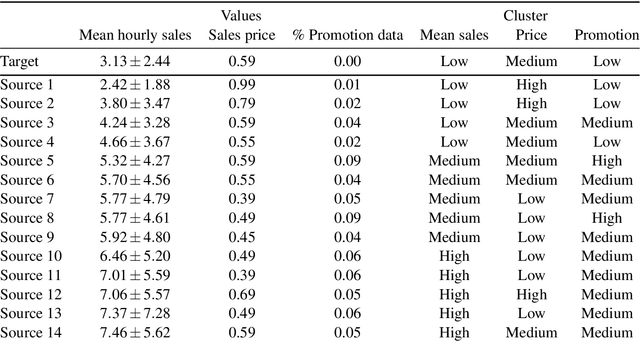
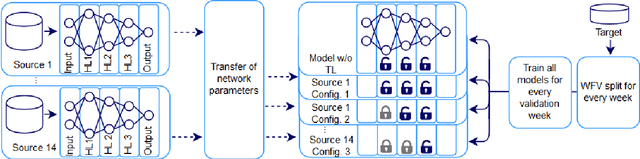
Data-driven methods -- such as machine learning and time series forecasting -- are widely used for sales forecasting in the food retail domain. However, for newly introduced products insufficient training data is available to train accurate models. In this case, human expert systems are implemented to improve prediction performance. Human experts rely on their implicit and explicit domain knowledge and transfer knowledge about historical sales of similar products to forecast new product sales. By applying the concept of Transfer Learning, we propose an analytical approach to transfer knowledge between listed stock products and new products. A network-based Transfer Learning approach for deep neural networks is designed to investigate the efficiency of Transfer Learning in the domain of food sales forecasting. Furthermore, we examine how knowledge can be shared across different products and how to identify the products most suitable for transfer. To test the proposed approach, we conduct a comprehensive case study for a newly introduced product, based on data of an Austrian food retailing company. The experimental results show, that the prediction accuracy of deep neural networks for food sales forecasting can be effectively increased using the proposed approach.
Half-empty or half-full? A Hybrid Approach to Predict Recycling Behavior of Consumers to Increase Reverse Vending Machine Uptime
Mar 30, 2020
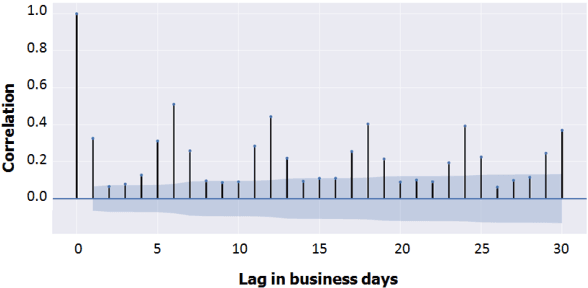
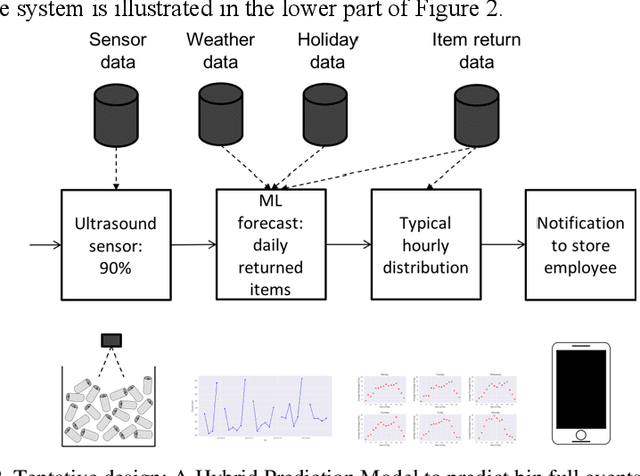
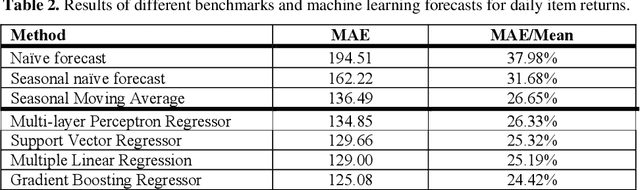
Reverse Vending Machines (RVMs) are a proven instrument for facilitating closed-loop plastic packaging recycling. A good customer experience at the RVM is crucial for a further proliferation of this technology. Bin full events are the major reason for Reverse Vending Machine (RVM) downtime at the world leader in the RVM market. The paper at hand develops and evaluates an approach based on machine learning and statistical approximation to foresee bin full events and, thus increase uptime of RVMs. Our approach relies on forecasting the hourly time series of returned beverage containers at a given RVM. We contribute by developing and evaluating an approach for hourly forecasts in a retail setting - this combination of application domain and forecast granularity is novel. A trace-driven simulation confirms that the forecasting-based approach leads to less downtime and costs than naive emptying strategies.
Sequential Transfer Machine Learning in Networks: Measuring the Impact of Data and Neural Net Similarity on Transferability
Mar 29, 2020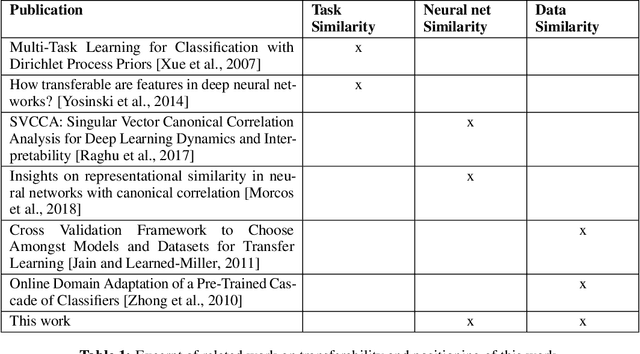


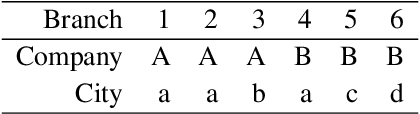
In networks of independent entities that face similar predictive tasks, transfer machine learning enables to re-use and improve neural nets using distributed data sets without the exposure of raw data. As the number of data sets in business networks grows and not every neural net transfer is successful, indicators are needed for its impact on the target performance-its transferability. We perform an empirical study on a unique real-world use case comprised of sales data from six different restaurants. We train and transfer neural nets across these restaurant sales data and measure their transferability. Moreover, we calculate potential indicators for transferability based on divergences of data, data projections and a novel metric for neural net similarity. We obtain significant negative correlations between the transferability and the tested indicators. Our findings allow to choose the transfer path based on these indicators, which improves model performance whilst simultaneously requiring fewer model transfers.
Machine Learning in Artificial Intelligence: Towards a Common Understanding
Mar 27, 2020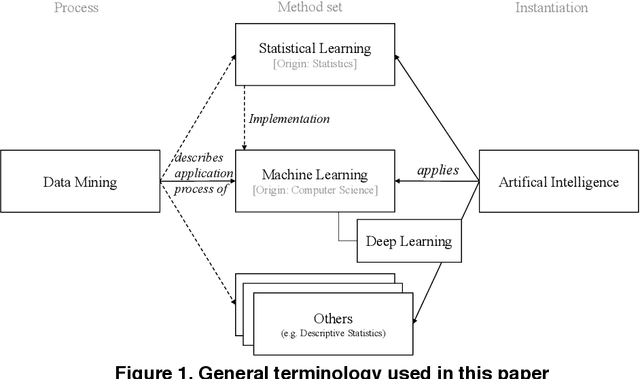

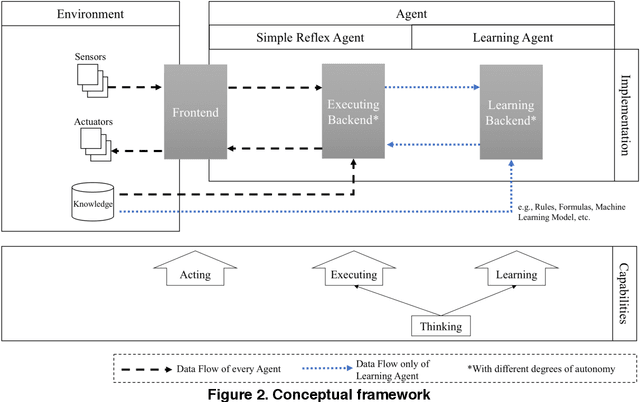
The application of "machine learning" and "artificial intelligence" has become popular within the last decade. Both terms are frequently used in science and media, sometimes interchangeably, sometimes with different meanings. In this work, we aim to clarify the relationship between these terms and, in particular, to specify the contribution of machine learning to artificial intelligence. We review relevant literature and present a conceptual framework which clarifies the role of machine learning to build (artificial) intelligent agents. Hence, we seek to provide more terminological clarity and a starting point for (interdisciplinary) discussions and future research.