 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Concept Drift With Neural Network Model Uncertainty
Jul 05, 2021
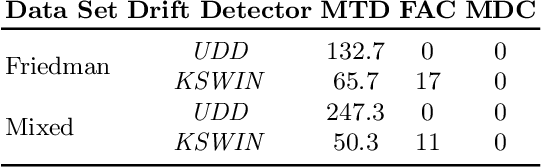


Deployed machine learning models are confronted with the problem of changing data over time, a phenomenon also called concept drift. While existing approaches of concept drift detection already show convincing results, they require true labels as a prerequisite for successful drift detection. Especially in many real-world application scenarios-like the ones covered in this work-true labels are scarce, and their acquisition is expensive. Therefore, we introduce a new algorithm for drift detection, Uncertainty Drift Detection (UDD), which is able to detect drifts without access to true labels. Our approach is based on the uncertainty estimates provided by a deep neural network in combination with Monte Carlo Dropout. Structural changes over time are detected by applying the ADWIN technique on the uncertainty estimates, and detected drifts trigger a retraining of the prediction model. In contrast to input data-based drift detection, our approach considers the effects of the current input data on the properties of the prediction model rather than detecting change on the input data only (which can lead to unnecessary retrainings). We show that UDD outperforms other state-of-the-art strategies on two synthetic as well as ten real-world data sets for both regression and classification tasks.
Utilizing Concept Drift for Measuring the Effectiveness of Policy Interventions: The Case of the COVID-19 Pandemic
Dec 04, 2020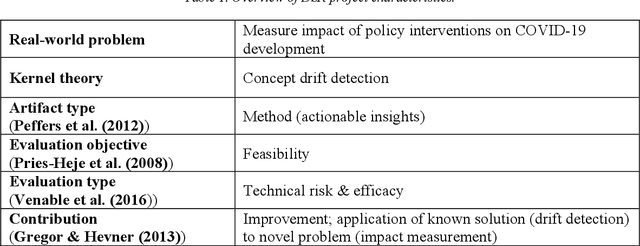
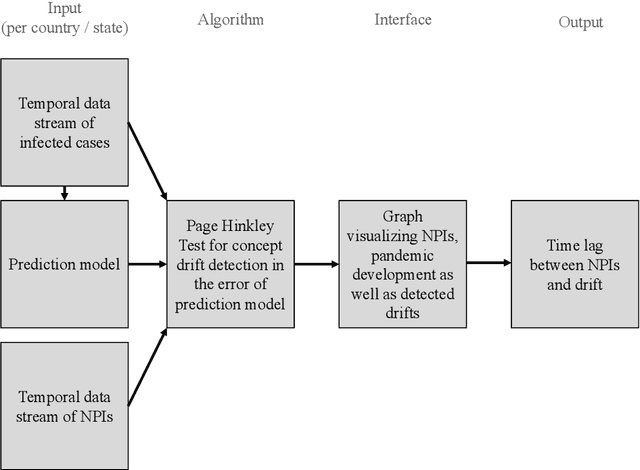
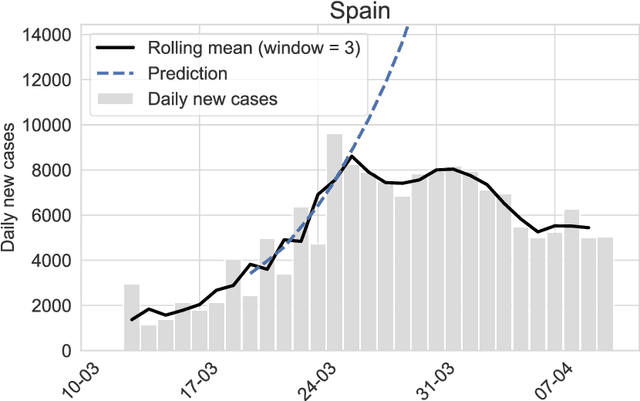
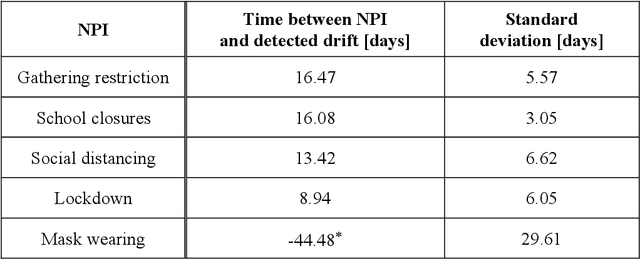
As a reaction to the high infectiousness and lethality of the COVID-19 virus, countries around the world have adopted drastic policy measures to contain the pandemic. However, it remains unclear which effect these measures, so-called non-pharmaceutical interventions (NPIs), have on the spread of the virus. In this article, we use machine learning and apply drift detection methods in a novel way to measure the effectiveness of policy interventions: We analyze the effect of NPIs on the development of daily case numbers of COVID-19 across 9 European countries and 28 US states. Our analysis shows that it takes more than two weeks on average until NPIs show a significant effect on the number of new cases. We then analyze how characteristics of each country or state, e.g., decisiveness regarding NPIs, climate or population density, influence the time lag until NPIs show their effectiveness. In our analysis, especially the timing of school closures reveals a significant effect on the development of the pandemic. This information is crucial for policy makers confronted with difficult decisions to trade off strict containment of the virus with NPI relief.
Human vs. supervised machine learning: Who learns patterns faster?
Nov 30, 2020
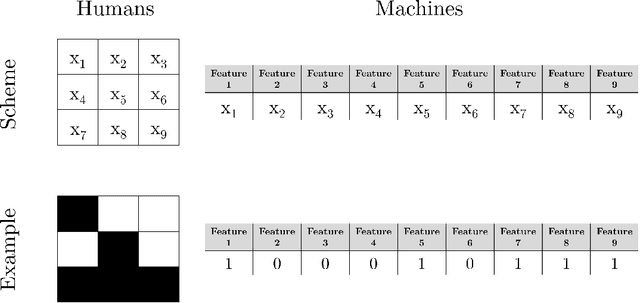
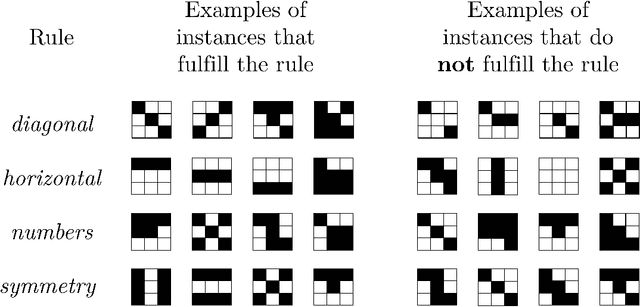
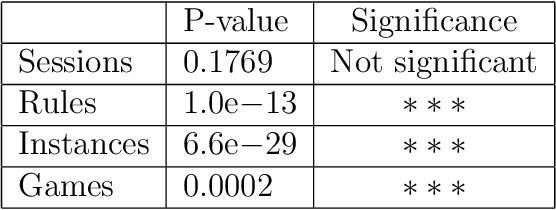
The capabilities of supervised machine learning (SML), especially compared to human abilities, are being discussed in scientific research and in the usage of SML. This study provides an answer to how learning performance differs between humans and machines when there is limited training data. We have designed an experiment in which 44 humans and three different machine learning algorithms identify patterns in labeled training data and have to label instances according to the patterns they find. The results show a high dependency between performance and the underlying patterns of the task. Whereas humans perform relatively similarly across all patterns, machines show large performance differences for the various patterns in our experiment. After seeing 20 instances in the experiment, human performance does not improve anymore, which we relate to theories of cognitive overload. Machines learn slower but can reach the same level or may even outperform humans in 2 of the 4 of used patterns. However, machines need more instances compared to humans for the same results. The performance of machines is comparably lower for the other 2 patterns due to the difficulty of combining input features.
Switching Scheme: A Novel Approach for Handling Incremental Concept Drift in Real-World Data Sets
Nov 05, 2020
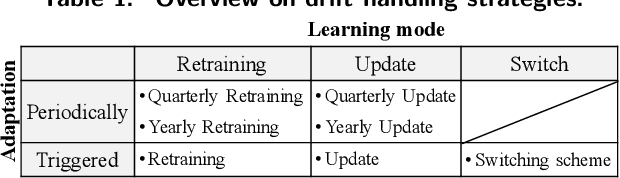
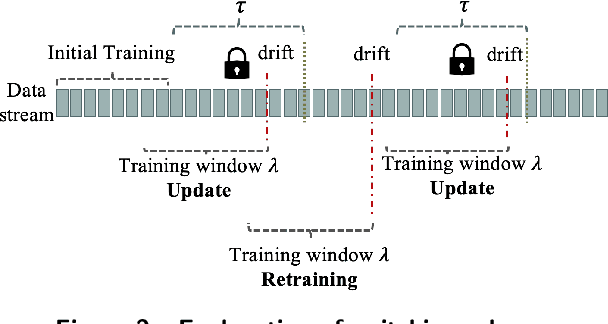

Machine learning models nowadays play a crucial role for many applications in business and industry. However, models only start adding value as soon as they are deployed into production. One challenge of deployed models is the effect of changing data over time, which is often described with the term concept drift. Due to their nature, concept drifts can severely affect the prediction performance of a machine learning system. In this work, we analyze the effects of concept drift in the context of a real-world data set. For efficient concept drift handling, we introduce the switching scheme which combines the two principles of retraining and updating of a machine learning model. Furthermore, we systematically analyze existing regular adaptation as well as triggered adaptation strategies. The switching scheme is instantiated on New York City taxi data, which is heavily influenced by changing demand patterns over time. We can show that the switching scheme outperforms all other baselines and delivers promising prediction results.
Handling Concept Drift for Predictions in Business Process Mining
May 18, 2020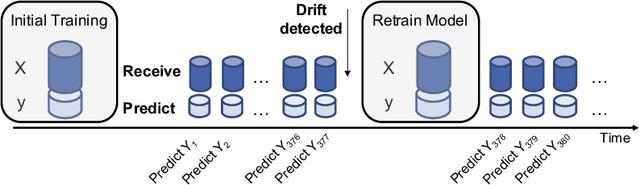

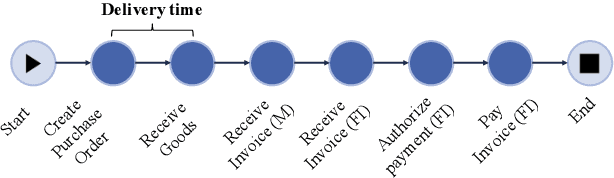
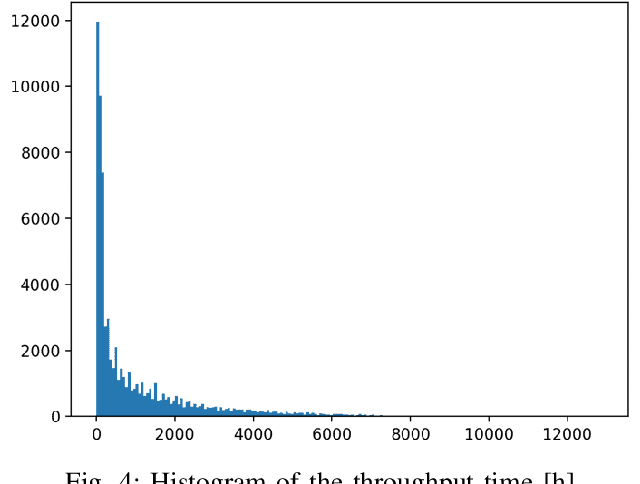
Predictive services nowadays play an important role across all business sectors. However, deployed machine learning models are challenged by changing data streams over time which is described as concept drift. Prediction quality of models can be largely influenced by this phenomenon. Therefore, concept drift is usually handled by retraining of the model. However, current research lacks a recommendation which data should be selected for the retraining of the machine learning model. Therefore, we systematically analyze different data selection strategies in this work. Subsequently, we instantiate our findings on a use case in process mining which is strongly affected by concept drift. We can show that we can improve accuracy from 0.5400 to 0.7010 with concept drift handling. Furthermore, we depict the effects of the different data selection strategies.
Handling Concept Drifts in Regression Problems -- the Error Intersection Approach
Apr 01, 2020



Machine learning models are omnipresent for predictions on big data. One challenge of deployed models is the change of the data over time, a phenomenon called concept drift. If not handled correctly, a concept drift can lead to significant mispredictions. We explore a novel approach for concept drift handling, which depicts a strategy to switch between the application of simple and complex machine learning models for regression tasks. We assume that the approach plays out the individual strengths of each model, switching to the simpler model if a drift occurs and switching back to the complex model for typical situations. We instantiate the approach on a real-world data set of taxi demand in New York City, which is prone to multiple drifts, e.g. the weather phenomena of blizzards, resulting in a sudden decrease of taxi demand. We are able to show that our suggested approach outperforms all regarded baselines significantly.