 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Potential of Explainable Artificial Intelligence (XAI) for Fairness Along the AI Lifecycle
Apr 30, 2024


The widespread use of artificial intelligence (AI) systems across various domains is increasingly highlighting issues related to algorithmic fairness, especially in high-stakes scenarios. Thus, critical considerations of how fairness in AI systems might be improved, and what measures are available to aid this process, are overdue. Many researchers and policymakers see explainable AI (XAI) as a promising way to increase fairness in AI systems. However, there is a wide variety of XAI methods and fairness conceptions expressing different desiderata, and the precise connections between XAI and fairness remain largely nebulous. Besides, different measures to increase algorithmic fairness might be applicable at different points throughout an AI system's lifecycle. Yet, there currently is no coherent mapping of fairness desiderata along the AI lifecycle. In this paper, we set out to bridge both these gaps: We distill eight fairness desiderata, map them along the AI lifecycle, and discuss how XAI could help address each of them. We hope to provide orientation for practical applications and to inspire XAI research specifically focused on these fairness desiderata.
Utilizing Active Machine Learning for Quality Assurance: A Case Study of Virtual Car Renderings in the Automotive Industry
Oct 18, 2021
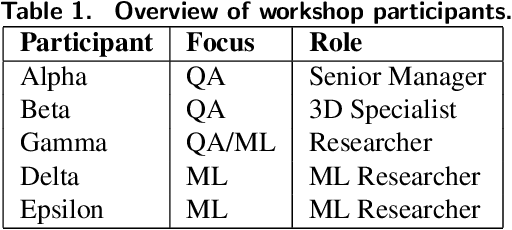
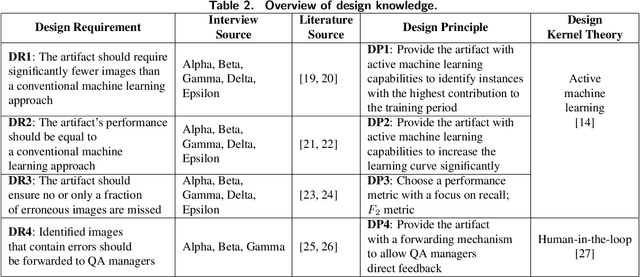
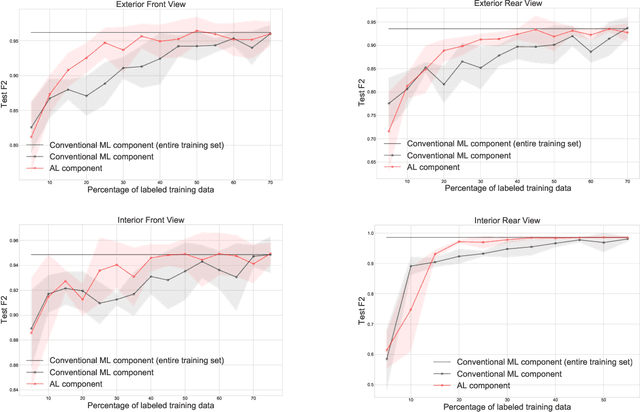
Computer-generated imagery of car models has become an indispensable part of car manufacturers' advertisement concepts. They are for instance used in car configurators to offer customers the possibility to configure their car online according to their personal preferences. However, human-led quality assurance faces the challenge to keep up with high-volume visual inspections due to the car models' increasing complexity. Even though the application of machine learning to many visual inspection tasks has demonstrated great success, its need for large labeled data sets remains a central barrier to using such systems in practice. In this paper, we propose an active machine learning-based quality assurance system that requires significantly fewer labeled instances to identify defective virtual car renderings without compromising performance. By employing our system at a German automotive manufacturer, start-up difficulties can be overcome, the inspection process efficiency can be increased, and thus economic advantages can be realized.
Detecting Concept Drift With Neural Network Model Uncertainty
Jul 05, 2021
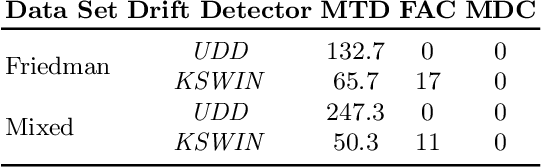


Deployed machine learning models are confronted with the problem of changing data over time, a phenomenon also called concept drift. While existing approaches of concept drift detection already show convincing results, they require true labels as a prerequisite for successful drift detection. Especially in many real-world application scenarios-like the ones covered in this work-true labels are scarce, and their acquisition is expensive. Therefore, we introduce a new algorithm for drift detection, Uncertainty Drift Detection (UDD), which is able to detect drifts without access to true labels. Our approach is based on the uncertainty estimates provided by a deep neural network in combination with Monte Carlo Dropout. Structural changes over time are detected by applying the ADWIN technique on the uncertainty estimates, and detected drifts trigger a retraining of the prediction model. In contrast to input data-based drift detection, our approach considers the effects of the current input data on the properties of the prediction model rather than detecting change on the input data only (which can lead to unnecessary retrainings). We show that UDD outperforms other state-of-the-art strategies on two synthetic as well as ten real-world data sets for both regression and classification tasks.
Utilizing Concept Drift for Measuring the Effectiveness of Policy Interventions: The Case of the COVID-19 Pandemic
Dec 04, 2020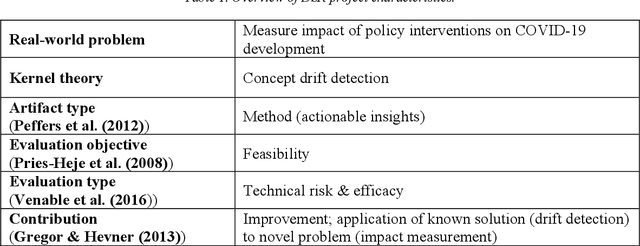
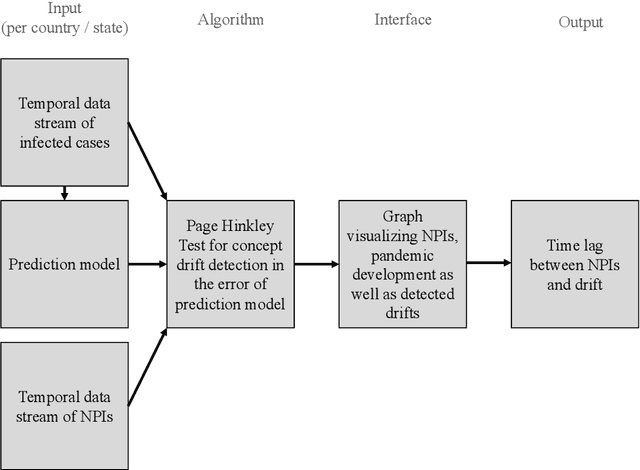
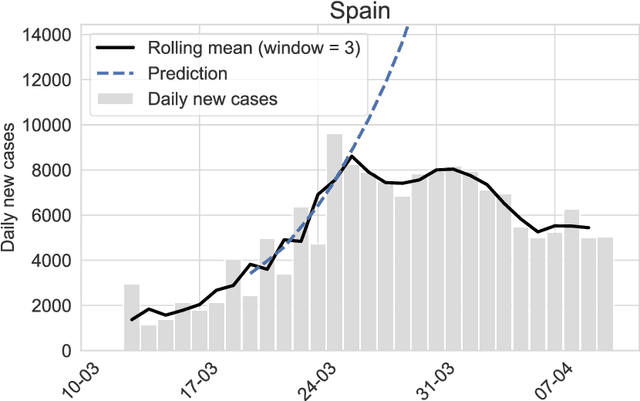
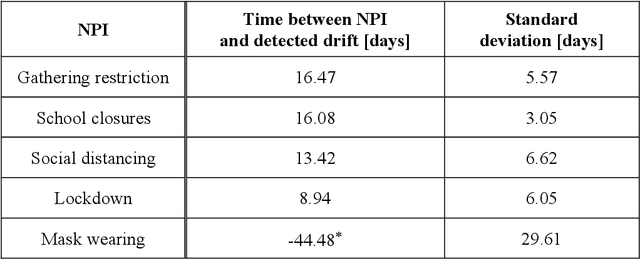
As a reaction to the high infectiousness and lethality of the COVID-19 virus, countries around the world have adopted drastic policy measures to contain the pandemic. However, it remains unclear which effect these measures, so-called non-pharmaceutical interventions (NPIs), have on the spread of the virus. In this article, we use machine learning and apply drift detection methods in a novel way to measure the effectiveness of policy interventions: We analyze the effect of NPIs on the development of daily case numbers of COVID-19 across 9 European countries and 28 US states. Our analysis shows that it takes more than two weeks on average until NPIs show a significant effect on the number of new cases. We then analyze how characteristics of each country or state, e.g., decisiveness regarding NPIs, climate or population density, influence the time lag until NPIs show their effectiveness. In our analysis, especially the timing of school closures reveals a significant effect on the development of the pandemic. This information is crucial for policy makers confronted with difficult decisions to trade off strict containment of the virus with NPI relief.
DEAL: Deep Evidential Active Learning for Image Classification
Jul 22, 2020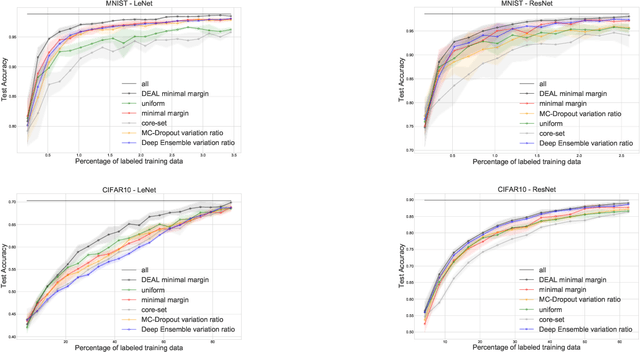
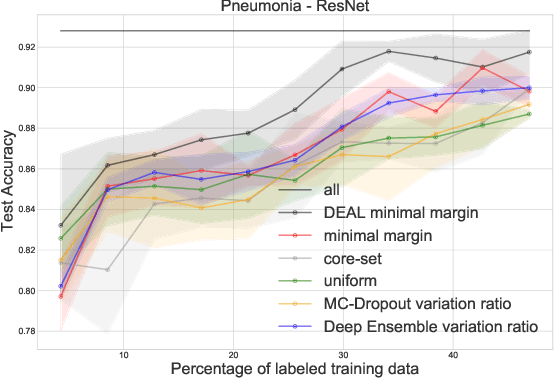

Convolutional Neural Networks (CNNs) have proven to be state-of-the-art models for supervised computer vision tasks, such as image classification. However, large labeled data sets are generally needed for the training and validation of such models. In many domains, unlabeled data is available but labeling is expensive, for instance when specific expert knowledge is required. Active Learning (AL) is one approach to mitigate the problem of limited labeled data. Through selecting the most informative and representative data instances for labeling, AL can contribute to more efficient learning of the model. Recent AL methods for CNNs propose different solutions for the selection of instances to be labeled. However, they do not perform consistently well and are often computationally expensive. In this paper, we propose a novel AL algorithm that efficiently learns from unlabeled data by capturing high prediction uncertainty. By replacing the softmax standard output of a CNN with the parameters of a Dirichlet density, the model learns to identify data instances that contribute efficiently to improving model performance during training. We demonstrate in several experiments with publicly available data that our method consistently outperforms other state-of-the-art AL approaches. It can be easily implemented and does not require extensive computational resources for training. Additionally, we are able to show the benefits of the approach on a real-world medical use case in the field of automated detection of visual signals for pneumonia on chest radiographs.