 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report on Reinforcement Learning Control on the Lucas-Nülle Inverted Pendulum
Dec 03, 2024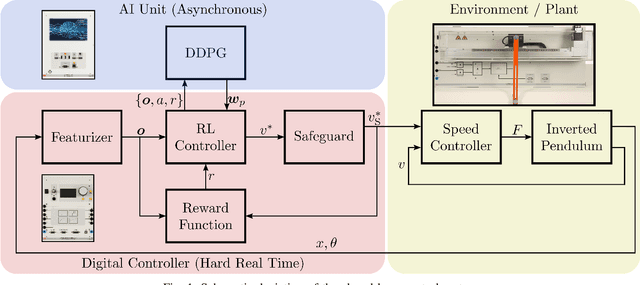


The discipline of automatic control is making increased use of concepts that originate from the domain of machine learning. Herein, reinforcement learning (RL) takes an elevated role, as it is inherently designed for sequential decision making, and can be applied to optimal control problems without the need for a plant system model. To advance education of control engineers and operators in this field, this contribution targets an RL framework that can be applied to educational hardware provided by the Lucas-N\"ulle company. Specifically, the goal of inverted pendulum control is pursued by means of RL, including both, swing-up and stabilization within a single holistic design approach. Herein, the actual learning is enabled by separating corresponding computations from the real-time control computer and outsourcing them to a different hardware. This distributed architecture, however, necessitates communication of the involved components, which is realized via CAN bus. The experimental proof of concept is presented with an applied safeguarding algorithm that prevents the plant from being operated harmfully during the trial-and-error training phase.
Steady-State Error Compensation in Reference Tracking and Disturbance Rejection Problems for Reinforcement Learning-Based Control
Jan 31, 2022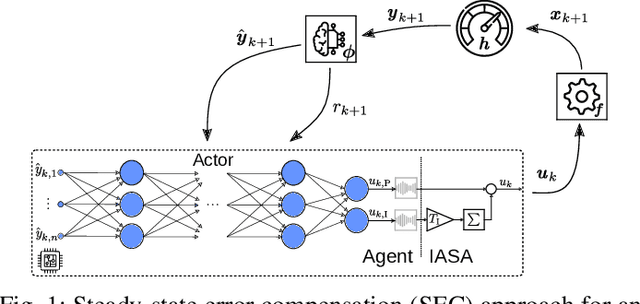
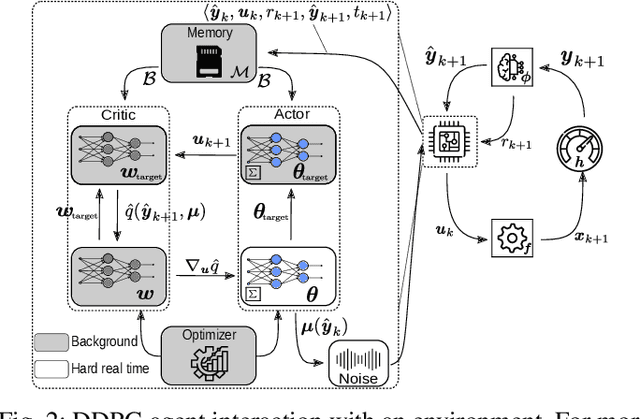

Reinforcement learning (RL) is a promising, upcoming topic in automatic control applications. Where classical control approaches require a priori system knowledge, data-driven control approaches like RL allow a model-free controller design procedure, rendering them emergent techniques for systems with changing plant structures and varying parameters. While it was already shown in various applications that the transient control behavior for complex systems can be sufficiently handled by RL, the challenge of non-vanishing steady-state control errors remains, which arises from the usage of control policy approximations and finite training times. To overcome this issue, an integral action state augmentation (IASA) for actor-critic-based RL controllers is introduced that mimics an integrating feedback, which is inspired by the delta-input formulation within model predictive control. This augmentation does not require any expert knowledge, leaving the approach model free. As a result, the RL controller learns how to suppress steady-state control deviations much more effectively. Two exemplary applications from the domain of electrical energy engineering validate the benefit of the developed method both for reference tracking and disturbance rejection. In comparison to a standard deep deterministic policy gradient (DDPG) setup, the suggested IASA extension allows to reduce the steady-state error by up to 52 $\%$ within the considered validation scenarios.
Improved Exploring Starts by Kernel Density Estimation-Based State-Space Coverage Acceleration in Reinforcement Learning
May 19, 2021


Reinforcement learning (RL) is currently a popular research topic in control engineering and has the potential to make its way to industrial and commercial applications. Corresponding RL controllers are trained in direct interaction with the controlled system, rendering them data-driven and performance-oriented solutions. The best practice of exploring starts (ES) is used by default to support the learning process via randomly picked initial states. However, this method might deliver strongly biased results if the system's dynamic and constraints lead to unfavorable sample distributions in the state space (e.g., condensed sample accumulation in certain state-space areas). To overcome this issue, a kernel density estimation-based state-space coverage acceleration (DESSCA) is proposed, which improves the ES concept by prioritizing infrequently visited states for a more balanced coverage of the state space during training. Considered test scenarios are mountain car, cartpole and electric motor control environments. Using DQN and DDPG as exemplary RL algorithms, it can be shown that DESSCA is a simple yet effective algorithmic extension to the established ES approach.