 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAIMED -- the open source framework for building coarse-grained operators for accelerated discovery in science
Jul 12, 2023



In modern data-driven science, reproducibility and reusability are key challenges. Scientists are well skilled in the process from data to publication. Although some publication channels require source code and data to be made accessible, rerunning and verifying experiments is usually hard due to a lack of standards. Therefore, reusing existing scientific data processing code from state-of-the-art research is hard as well. This is why we introduce CLAIMED, which has a proven track record in scientific research for addressing the repeatability and reusability issues in modern data-driven science. CLAIMED is a framework to build reusable operators and scalable scientific workflows by supporting the scientist to draw from previous work by re-composing workflows from existing libraries of coarse-grained scientific operators. Although various implementations exist, CLAIMED is programming language, scientific library, and execution environment agnostic.
CLAIMED, a visual and scalable component library for Trusted AI
Mar 04, 2021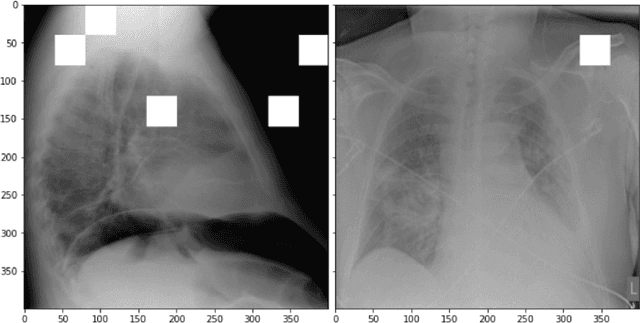
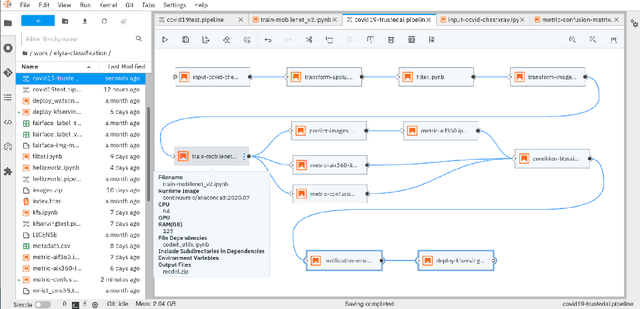
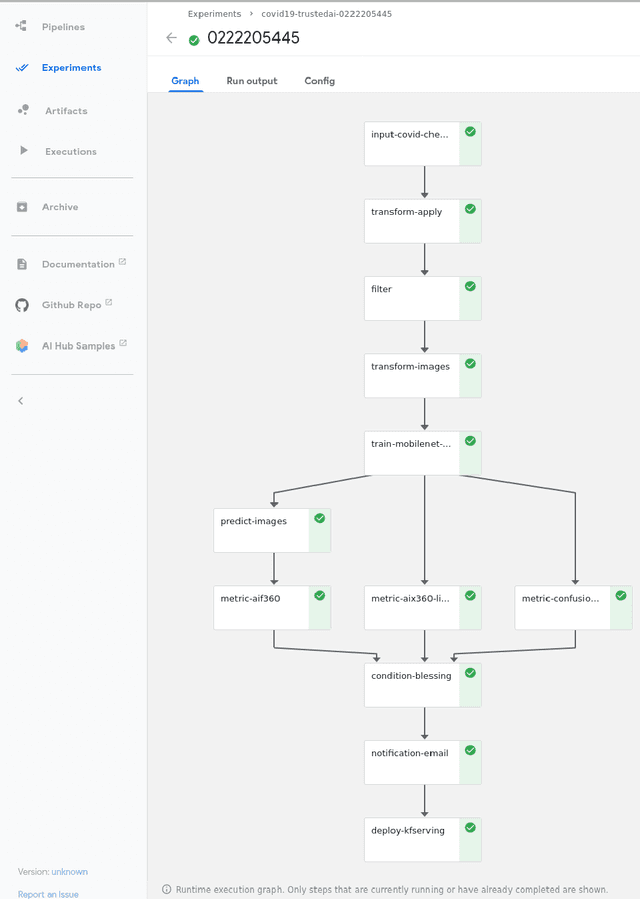
Deep Learning models are getting more and more popular but constraints on explainability, adversarial robustness and fairness are often major concerns for production deployment. Although the open source ecosystem is abundant on addressing those concerns, fully integrated, end to end systems are lacking in open source. Therefore we provide an entirely open source, reusable component framework, visual editor and execution engine for production grade machine learning on top of Kubernetes, a joint effort between IBM and the University Hospital Basel. It uses Kubeflow Pipelines, the AI Explainability360 toolkit, the AI Fairness360 toolkit and the Adversarial Robustness Toolkit on top of ElyraAI, Kubeflow, Kubernetes and JupyterLab. Using the Elyra pipeline editor, AI pipelines can be developed visually with a set of jupyter notebooks.