 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Attributing, Interpreting, Mitigating Data Unfairness
Paper and Code
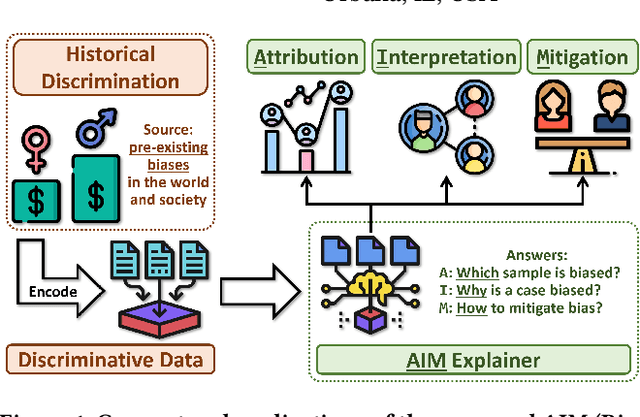
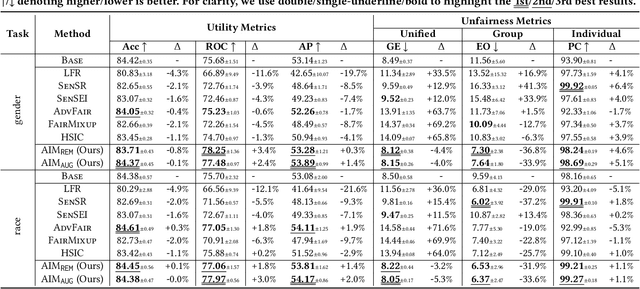
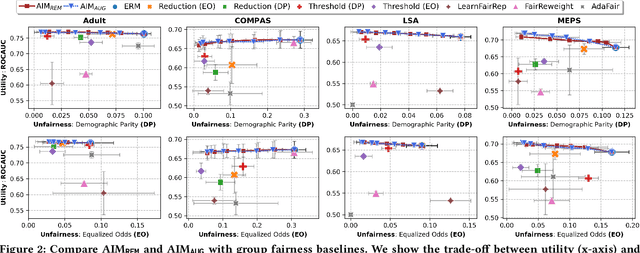
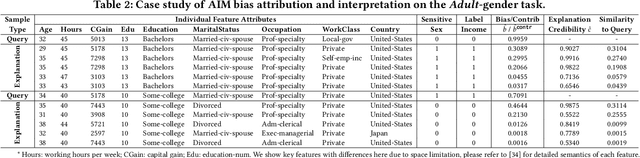
Data collected in the real world often encapsulates historical discrimination against disadvantaged groups and individuals. Existing fair machine learning (FairML) research has predominantly focused on mitigating discriminative bias in the model prediction, with far less effort dedicated towards exploring how to trace biases present in the data, despite its importance for the transparency and interpretability of FairML. To fill this gap, we investigate a novel research problem: discovering samples that reflect biases/prejudices from the training data. Grounding on the existing fairness notions, we lay out a sample bias criterion and propose practical algorithms for measuring and countering sample bias. The derived bias score provides intuitive sample-level attribution and explanation of historical bias in data. On this basis, we further design two FairML strategies via sample-bias-informed minimal data editing. They can mitigate both group and individual unfairness at the cost of minimal or zero predictive utility loss. Extensive experiments and analyses on multiple real-world datasets demonstrate the effectiveness of our methods in explaining and mitigating unfairness. Code is available at https://github.com/ZhiningLiu1998/AIM.