 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Large Language Models as Prompt Optimizers: An Analogical Analysis with Gradient-based Model Optimizers
Paper and Code

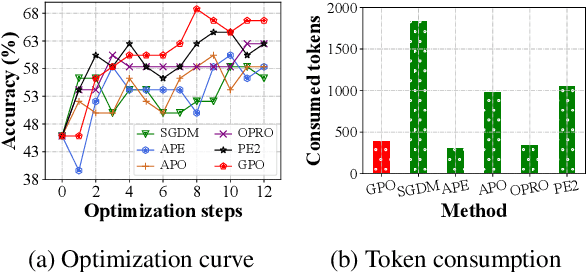

Automatic prompt optimization is an important approach to improving the performance of large language models (LLMs). Recent research demonstrates the potential of using LLMs as prompt optimizers, which can generate improved task prompts via iterative refinement. In this paper, we propose a novel perspective to investigate the design of LLM-based prompt optimizers, by drawing an analogy with gradient-based model optimizers. To connect these two approaches, we identify two pivotal factors in model parameter learning: update direction and update method. Focused on the two aspects, we borrow the theoretical framework and learning methods from gradient-based optimization to design improved strategies for LLM-based prompt optimizers. By systematically analyzing a rich set of improvement strategies, we further develop a capable Gradient-inspired LLM-based Prompt Optimizer called GPO. At each step, it first retrieves relevant prompts from the optimization trajectory as the update direction. Then, it utilizes the generation-based refinement strategy to perform the update, while controlling the edit distance through a cosine-based decay strategy. Extensive experiments demonstrate the effectiveness and efficiency of GPO. In particular, GPO brings an additional improvement of up to 56.8% on Big-Bench Hard and 55.3% on MMLU compared to baseline methods.