 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate FSA System Using ELBERT: An Efficient and Lightweight BERT
Dec 06, 2022With the development of deep learning and Transformer-based pre-trained models like BERT, the accuracy of many NLP tasks has been dramatically improved. However, the large number of parameters and computations also pose challenges for their deployment. For instance, using BERT can improve the predictions in the financial sentiment analysis (FSA) task but slow it down, where speed and accuracy are equally important in terms of profits. To address these issues, we first propose an efficient and lightweight BERT (ELBERT) along with a novel confidence-window-based (CWB) early exit mechanism. Based on ELBERT, an innovative method to accelerate text processing on the GPU platform is developed, solving the difficult problem of making the early exit mechanism work more effectively with a large input batch size. Afterward, a fast and high-accuracy FSA system is built. Experimental results show that the proposed CWB early exit mechanism achieves significantly higher accuracy than existing early exit methods on BERT under the same computation cost. By using this acceleration method, our FSA system can boost the processing speed by nearly 40 times to over 1000 texts per second with sufficient accuracy, which is nearly twice as fast as FastBERT, thus providing a more powerful text processing capability for modern trading systems.
Elbert: Fast Albert with Confidence-Window Based Early Exit
Jul 01, 2021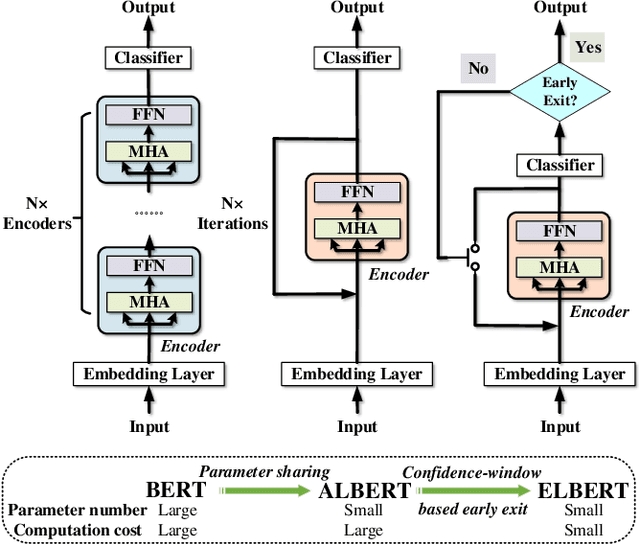
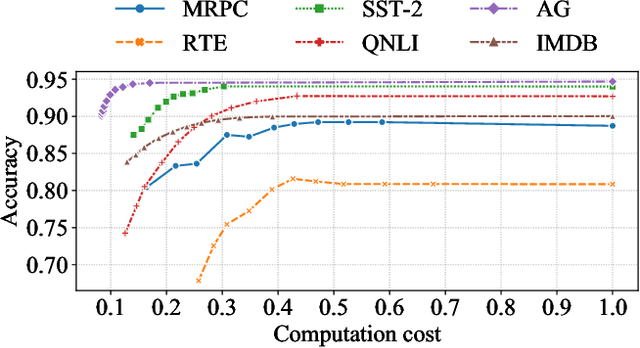
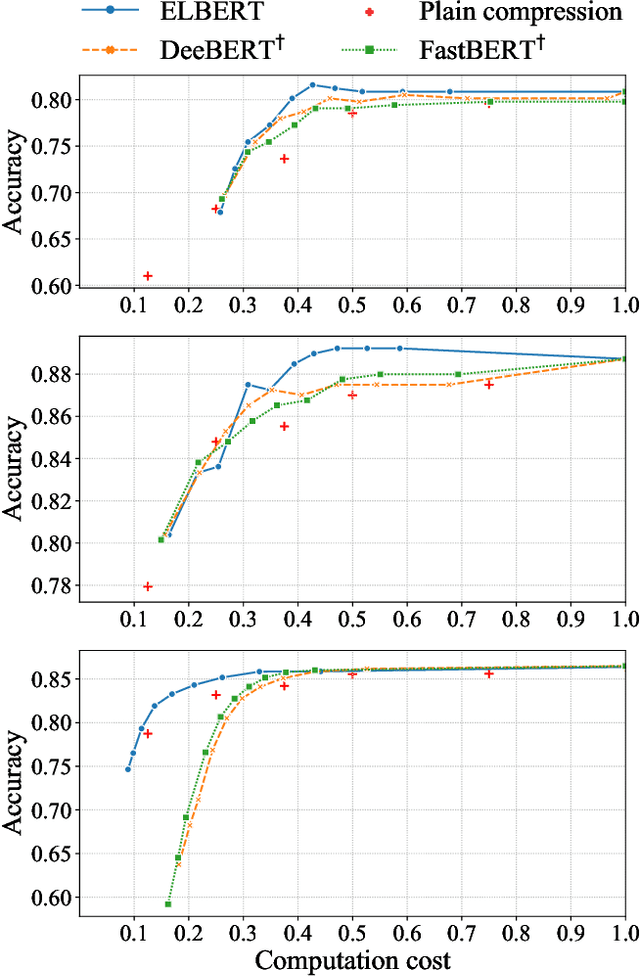
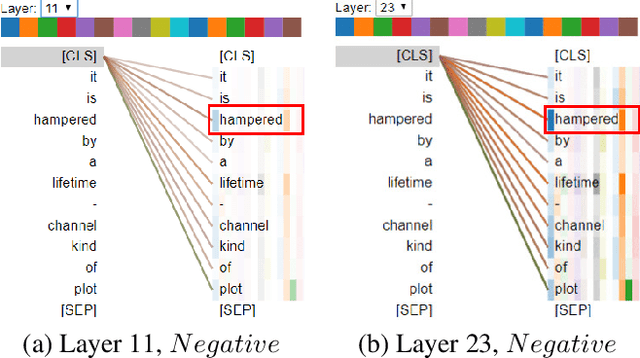
Despite the great success in Natural Language Processing (NLP) area, large pre-trained language models like BERT are not well-suited for resource-constrained or real-time applications owing to the large number of parameters and slow inference speed. Recently, compressing and accelerating BERT have become important topics. By incorporating a parameter-sharing strategy, ALBERT greatly reduces the number of parameters while achieving competitive performance. Nevertheless, ALBERT still suffers from a long inference time. In this work, we propose the ELBERT, which significantly improves the average inference speed compared to ALBERT due to the proposed confidence-window based early exit mechanism, without introducing additional parameters or extra training overhead. Experimental results show that ELBERT achieves an adaptive inference speedup varying from 2$\times$ to 10$\times$ with negligible accuracy degradation compared to ALBERT on various datasets. Besides, ELBERT achieves higher accuracy than existing early exit methods used for accelerating BERT under the same computation cost. Furthermore, to understand the principle of the early exit mechanism, we also visualize the decision-making process of it in ELBERT.