 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSayAnything: Audio-Driven Lip Synchronization with Conditional Video Diffusion
Paper and Code
Feb 17, 2025
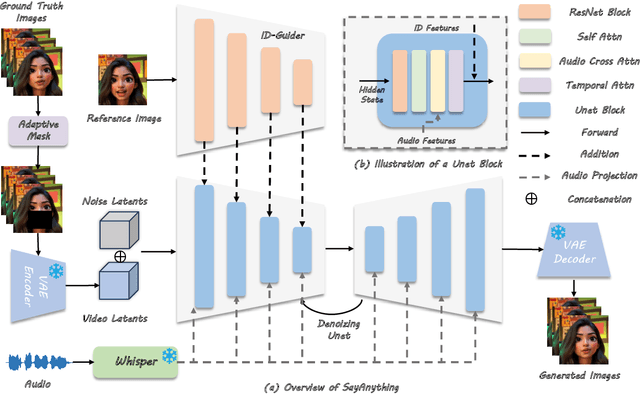
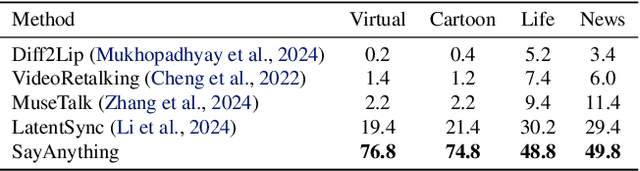
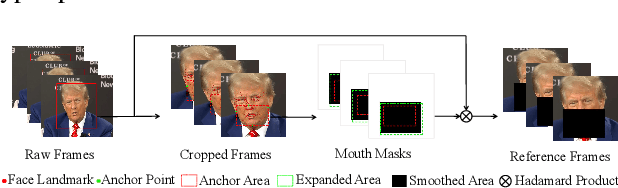
Recent advances in diffusion models have led to significant progress in audio-driven lip synchronization. However, existing methods typically rely on constrained audio-visual alignment priors or multi-stage learning of intermediate representations to force lip motion synthesis. This leads to complex training pipelines and limited motion naturalness. In this paper, we present SayAnything, a conditional video diffusion framework that directly synthesizes lip movements from audio input while preserving speaker identity. Specifically, we propose three specialized modules including identity preservation module, audio guidance module, and editing control module. Our novel design effectively balances different condition signals in the latent space, enabling precise control over appearance, motion, and region-specific generation without requiring additional supervision signals or intermediate representations. Extensive experiments demonstrate that SayAnything generates highly realistic videos with improved lip-teeth coherence, enabling unseen characters to say anything, while effectively generalizing to animated characters.