 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding
Jan 30, 2026Open-vocabulary grounding requires accurate vision-language alignment under weak supervision, yet existing methods either rely on global sentence embeddings that lack fine-grained expressiveness or introduce token-level alignment with explicit supervision or heavy cross-attention designs. We propose ExpAlign, a theoretically grounded vision-language alignment framework built on a principled multiple instance learning formulation. ExpAlign introduces an Expectation Alignment Head that performs attention-based soft MIL pooling over token-region similarities, enabling implicit token and instance selection without additional annotations. To further stabilize alignment learning, we develop an energy-based multi-scale consistency regularization scheme, including a Top-K multi-positive contrastive objective and a Geometry-Aware Consistency Objective derived from a Lagrangian-constrained free-energy minimization. Extensive experiments show that ExpAlign consistently improves open-vocabulary detection and zero-shot instance segmentation, particularly on long-tail categories. Most notably, it achieves 36.2 AP$_r$ on the LVIS minival split, outperforming other state-of-the-art methods at comparable model scale, while remaining lightweight and inference-efficient.
Pyramid Sparse Transformer: Enhancing Multi-Scale Feature Fusion with Dynamic Token Selection
May 19, 2025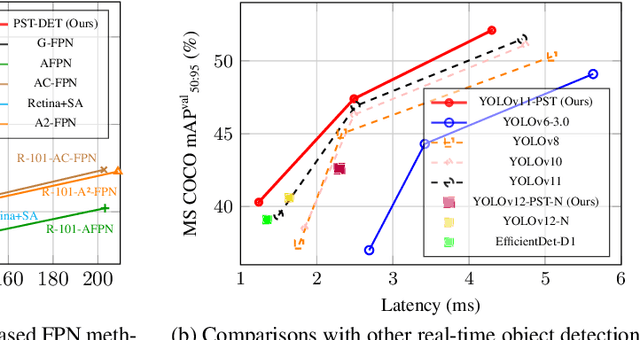
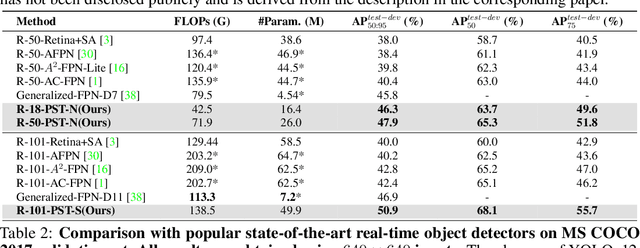
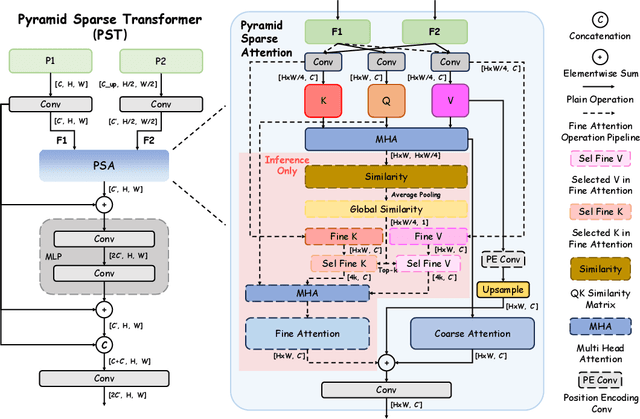
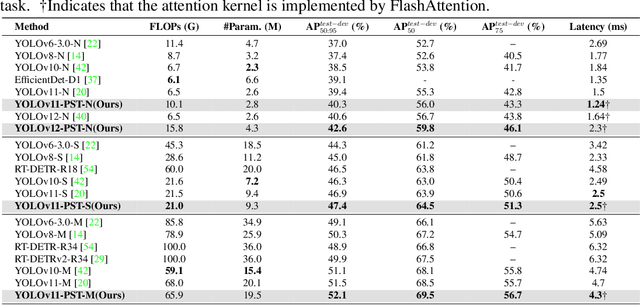
Feature fusion is critical for high-performance vision models but often incurs prohibitive complexity. However, prevailing attention-based fusion methods often involve significant computational complexity and implementation challenges, limiting their efficiency in resource-constrained environments. To address these issues, we introduce the Pyramid Sparse Transformer (PST), a lightweight, plug-and-play module that integrates coarse-to-fine token selection and shared attention parameters to reduce computation while preserving spatial detail. PST can be trained using only coarse attention and seamlessly activated at inference for further accuracy gains without retraining. When added to state-of-the-art real-time detection models, such as YOLOv11-N/S/M, PST yields mAP improvements of 0.9%, 0.5%, and 0.4% on MS COCO with minimal latency impact. Likewise, embedding PST into ResNet-18/50/101 as backbones, boosts ImageNet top-1 accuracy by 6.5%, 1.7%, and 1.0%, respectively. These results demonstrate PST's effectiveness as a simple, hardware-friendly enhancement for both detection and classification tasks.
SayAnything: Audio-Driven Lip Synchronization with Conditional Video Diffusion
Feb 17, 2025
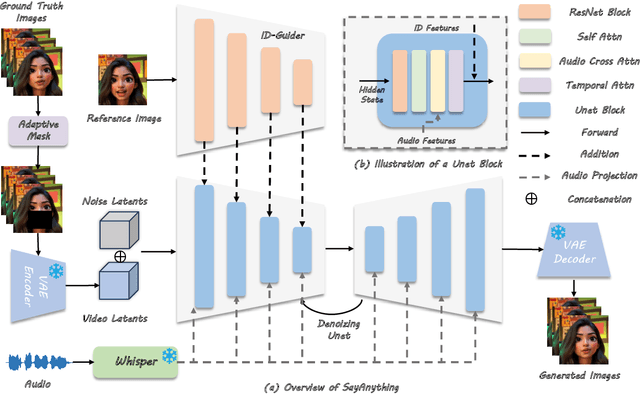
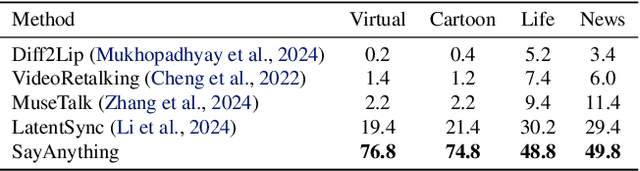
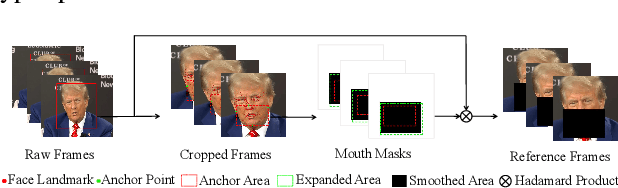
Recent advances in diffusion models have led to significant progress in audio-driven lip synchronization. However, existing methods typically rely on constrained audio-visual alignment priors or multi-stage learning of intermediate representations to force lip motion synthesis. This leads to complex training pipelines and limited motion naturalness. In this paper, we present SayAnything, a conditional video diffusion framework that directly synthesizes lip movements from audio input while preserving speaker identity. Specifically, we propose three specialized modules including identity preservation module, audio guidance module, and editing control module. Our novel design effectively balances different condition signals in the latent space, enabling precise control over appearance, motion, and region-specific generation without requiring additional supervision signals or intermediate representations. Extensive experiments demonstrate that SayAnything generates highly realistic videos with improved lip-teeth coherence, enabling unseen characters to say anything, while effectively generalizing to animated characters.
Intrinsic Evaluation of RAG Systems for Deep-Logic Questions
Oct 03, 2024



We introduce the Overall Performance Index (OPI), an intrinsic metric to evaluate retrieval-augmented generation (RAG) mechanisms for applications involving deep-logic queries. OPI is computed as the harmonic mean of two key metrics: the Logical-Relation Correctness Ratio and the average of BERT embedding similarity scores between ground-truth and generated answers. We apply OPI to assess the performance of LangChain, a popular RAG tool, using a logical relations classifier fine-tuned from GPT-4o on the RAG-Dataset-12000 from Hugging Face. Our findings show a strong correlation between BERT embedding similarity scores and extrinsic evaluation scores. Among the commonly used retrievers, the cosine similarity retriever using BERT-based embeddings outperforms others, while the Euclidean distance-based retriever exhibits the weakest performance. Furthermore, we demonstrate that combining multiple retrievers, either algorithmically or by merging retrieved sentences, yields superior performance compared to using any single retriever alone.
Dynamical Isometry based Rigorous Fair Neural Architecture Search
Jul 06, 2023Recently, the weight-sharing technique has significantly speeded up the training and evaluation procedure of neural architecture search. However, most existing weight-sharing strategies are solely based on experience or observation, which makes the searching results lack interpretability and rationality. In addition, due to the negligence of fairness, current methods are prone to make misjudgments in module evaluation. To address these problems, we propose a novel neural architecture search algorithm based on dynamical isometry. We use the fix point analysis method in the mean field theory to analyze the dynamics behavior in the steady state random neural network, and how dynamic isometry guarantees the fairness of weight-sharing based NAS. Meanwhile, we prove that our module selection strategy is rigorous fair by estimating the generalization error of all modules with well-conditioned Jacobian. Extensive experiments show that, with the same size, the architecture searched by the proposed method can achieve state-of-the-art top-1 validation accuracy on ImageNet classification. In addition, we demonstrate that our method is able to achieve better and more stable training performance without loss of generality.