 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTReGen: Context-driven Tree-structured Retrieval for Open-domain Long-form Text Generation
Oct 20, 2024



Open-domain long-form text generation requires generating coherent, comprehensive responses that address complex queries with both breadth and depth. This task is challenging due to the need to accurately capture diverse facets of input queries. Existing iterative retrieval-augmented generation (RAG) approaches often struggle to delve deeply into each facet of complex queries and integrate knowledge from various sources effectively. This paper introduces ConTReGen, a novel framework that employs a context-driven, tree-structured retrieval approach to enhance the depth and relevance of retrieved content. ConTReGen integrates a hierarchical, top-down in-depth exploration of query facets with a systematic bottom-up synthesis, ensuring comprehensive coverage and coherent integration of multifaceted information. Extensive experiments on multiple datasets, including LFQA and ODSUM, alongside a newly introduced dataset, ODSUM-WikiHow, demonstrate that ConTReGen outperforms existing state-of-the-art RAG models.
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Apr 10, 2024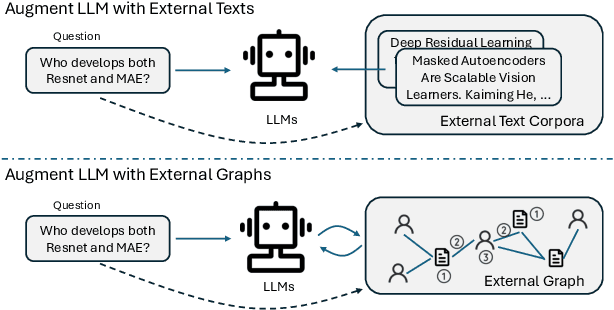
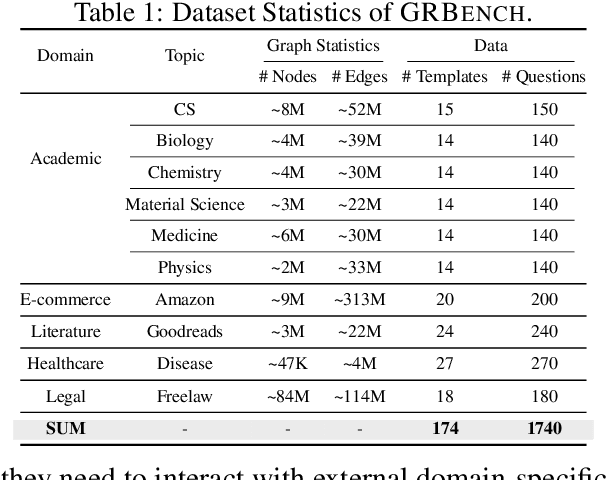
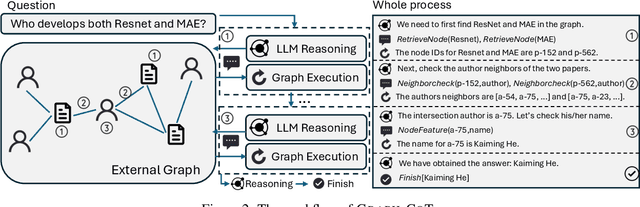
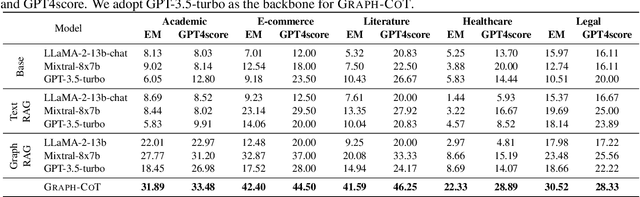
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
Mining Weighted Sequential Patterns in Incremental Uncertain Databases
Mar 31, 2024Due to the rapid development of science and technology, the importance of imprecise, noisy, and uncertain data is increasing at an exponential rate. Thus, mining patterns in uncertain databases have drawn the attention of researchers. Moreover, frequent sequences of items from these databases need to be discovered for meaningful knowledge with great impact. In many real cases, weights of items and patterns are introduced to find interesting sequences as a measure of importance. Hence, a constraint of weight needs to be handled while mining sequential patterns. Besides, due to the dynamic nature of databases, mining important information has become more challenging. Instead of mining patterns from scratch after each increment, incremental mining algorithms utilize previously mined information to update the result immediately. Several algorithms exist to mine frequent patterns and weighted sequences from incremental databases. However, these algorithms are confined to mine the precise ones. Therefore, we have developed an algorithm to mine frequent sequences in an uncertain database in this work. Furthermore, we have proposed two new techniques for mining when the database is incremental. Extensive experiments have been conducted for performance evaluation. The analysis showed the efficiency of our proposed framework.
* Accepted to Information Science journal
Long-form Question Answering: An Iterative Planning-Retrieval-Generation Approach
Nov 15, 2023Long-form question answering (LFQA) poses a challenge as it involves generating detailed answers in the form of paragraphs, which go beyond simple yes/no responses or short factual answers. While existing QA models excel in questions with concise answers, LFQA requires handling multiple topics and their intricate relationships, demanding comprehensive explanations. Previous attempts at LFQA focused on generating long-form answers by utilizing relevant contexts from a corpus, relying solely on the question itself. However, they overlooked the possibility that the question alone might not provide sufficient information to identify the relevant contexts. Additionally, generating detailed long-form answers often entails aggregating knowledge from diverse sources. To address these limitations, we propose an LFQA model with iterative Planning, Retrieval, and Generation. This iterative process continues until a complete answer is generated for the given question. From an extensive experiment on both an open domain and a technical domain QA dataset, we find that our model outperforms the state-of-the-art models on various textual and factual metrics for the LFQA task.
Unified Spatio-Temporal Modeling for Traffic Forecasting using Graph Neural Network
Apr 28, 2021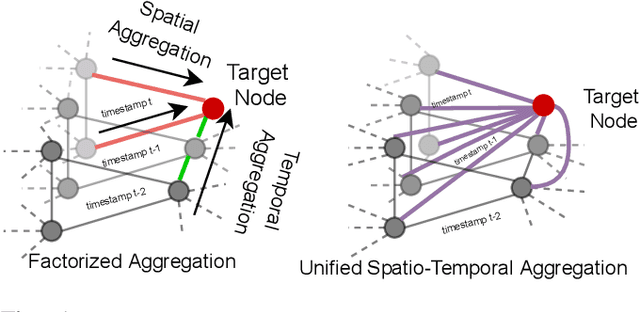
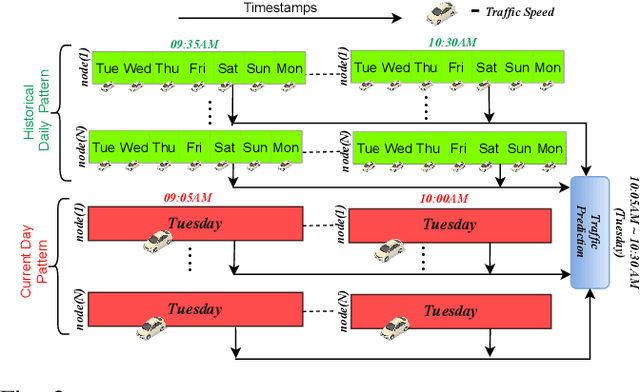
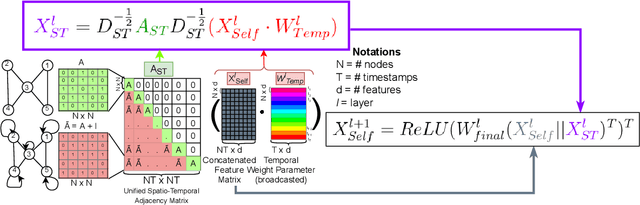

Research in deep learning models to forecast traffic intensities has gained great attention in recent years due to their capability to capture the complex spatio-temporal relationships within the traffic data. However, most state-of-the-art approaches have designed spatial-only (e.g. Graph Neural Networks) and temporal-only (e.g. Recurrent Neural Networks) modules to separately extract spatial and temporal features. However, we argue that it is less effective to extract the complex spatio-temporal relationship with such factorized modules. Besides, most existing works predict the traffic intensity of a particular time interval only based on the traffic data of the previous one hour of that day. And thereby ignores the repetitive daily/weekly pattern that may exist in the last hour of data. Therefore, we propose a Unified Spatio-Temporal Graph Convolution Network (USTGCN) for traffic forecasting that performs both spatial and temporal aggregation through direct information propagation across different timestamp nodes with the help of spectral graph convolution on a spatio-temporal graph. Furthermore, it captures historical daily patterns in previous days and current-day patterns in current-day traffic data. Finally, we validate our work's effectiveness through experimental analysis, which shows that our model USTGCN can outperform state-of-the-art performances in three popular benchmark datasets from the Performance Measurement System (PeMS). Moreover, the training time is reduced significantly with our proposed USTGCN model.
Node Embedding using Mutual Information and Self-Supervision based Bi-level Aggregation
Apr 27, 2021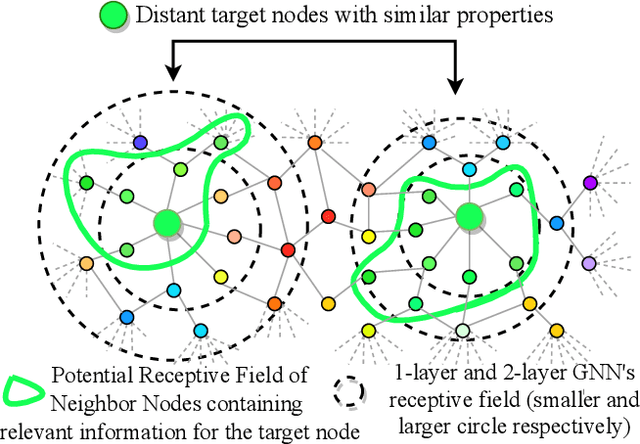
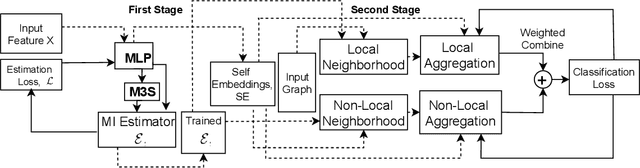

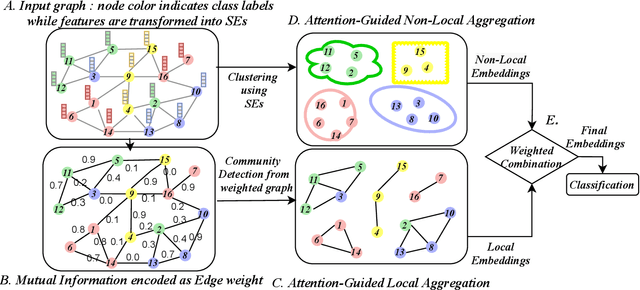
Graph Neural Networks (GNNs) learn low dimensional representations of nodes by aggregating information from their neighborhood in graphs. However, traditional GNNs suffer from two fundamental shortcomings due to their local ($l$-hop neighborhood) aggregation scheme. First, not all nodes in the neighborhood carry relevant information for the target node. Since GNNs do not exclude noisy nodes in their neighborhood, irrelevant information gets aggregated, which reduces the quality of the representation. Second, traditional GNNs also fail to capture long-range non-local dependencies between nodes. To address these limitations, we exploit mutual information (MI) to define two types of neighborhood, 1) \textit{Local Neighborhood} where nodes are densely connected within a community and each node would share higher MI with its neighbors, and 2) \textit{Non-Local Neighborhood} where MI-based node clustering is introduced to assemble informative but graphically distant nodes in the same cluster. To generate node presentations, we combine the embeddings generated by bi-level aggregation - local aggregation to aggregate features from local neighborhoods to avoid noisy information and non-local aggregation to aggregate features from non-local neighborhoods. Furthermore, we leverage self-supervision learning to estimate MI with few labeled data. Finally, we show that our model significantly outperforms the state-of-the-art methods in a wide range of assortative and disassortative graphs.
Structure-Aware Hierarchical Graph Pooling using Information Bottleneck
Apr 27, 2021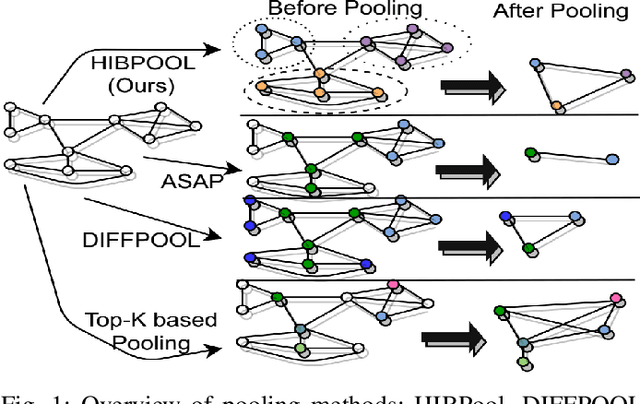

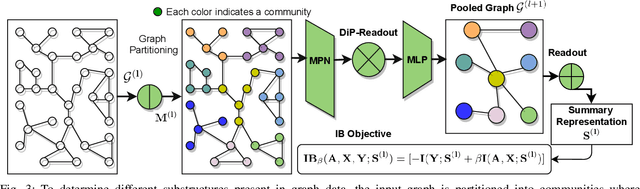
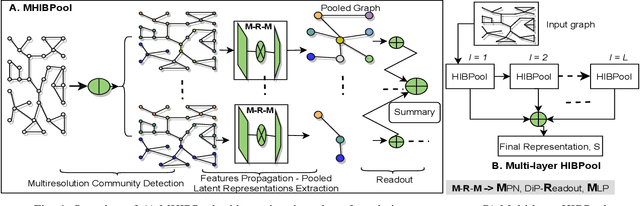
Graph pooling is an essential ingredient of Graph Neural Networks (GNNs) in graph classification and regression tasks. For these tasks, different pooling strategies have been proposed to generate a graph-level representation by downsampling and summarizing nodes' features in a graph. However, most existing pooling methods are unable to capture distinguishable structural information effectively. Besides, they are prone to adversarial attacks. In this work, we propose a novel pooling method named as {HIBPool} where we leverage the Information Bottleneck (IB) principle that optimally balances the expressiveness and robustness of a model to learn representations of input data. Furthermore, we introduce a novel structure-aware Discriminative Pooling Readout ({DiP-Readout}) function to capture the informative local subgraph structures in the graph. Finally, our experimental results show that our model significantly outperforms other state-of-art methods on several graph classification benchmarks and more resilient to feature-perturbation attack than existing pooling methods.
SST-GNN: Simplified Spatio-temporal Traffic forecasting model using Graph Neural Network
Mar 31, 2021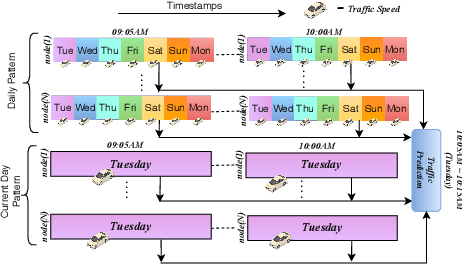
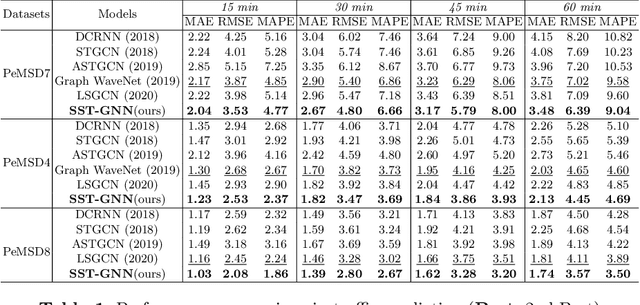
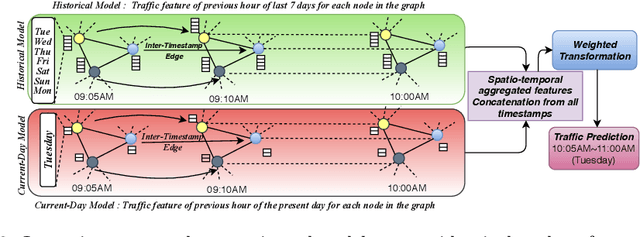

To capture spatial relationships and temporal dynamics in traffic data, spatio-temporal models for traffic forecasting have drawn significant attention in recent years. Most of the recent works employed graph neural networks(GNN) with multiple layers to capture the spatial dependency. However, road junctions with different hop-distance can carry distinct traffic information which should be exploited separately but existing multi-layer GNNs are incompetent to discriminate between their impact. Again, to capture the temporal interrelationship, recurrent neural networks are common in state-of-the-art approaches that often fail to capture long-range dependencies. Furthermore, traffic data shows repeated patterns in a daily or weekly period which should be addressed explicitly. To address these limitations, we have designed a Simplified Spatio-temporal Traffic forecasting GNN(SST-GNN) that effectively encodes the spatial dependency by separately aggregating different neighborhood representations rather than with multiple layers and capture the temporal dependency with a simple yet effective weighted spatio-temporal aggregation mechanism. We capture the periodic traffic patterns by using a novel position encoding scheme with historical and current data in two different models. With extensive experimental analysis, we have shown that our model has significantly outperformed the state-of-the-art models on three real-world traffic datasets from the Performance Measurement System (PeMS).