 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient VLMs for Gastrointestinal Endoscopy: Medical Image Generation and Clinical Visual Question Answering
May 24, 2026The major limitations of gastrointestinal (GI) endoscopy AI systems arise from a shortage of annotated data, strict privacy policies, and significant bottlenecks in conventional model fine-tuning. Such limitations impede the successful application of sophisticated AI models in clinical practice, particularly affecting the reliability and scalability of diagnosis. In this paper, we present a dual-pipeline PEFT model that addresses two fundamental problems: medical Visual Question Answering (VQA) and the generation of privacy-preserving synthetic data. For clinical VQA, we adopt the Florence-2 vision-language model. Leveraging PEFT enhances model interpretability while substantially reducing the computational cost of training. Simultaneously, we employ Low-Rank Adaptation (LoRA) with Stable Diffusion 2.1 to generate high-quality GI images that enhance training databases without violating patient privacy. This research utilized the Kvasir-VQA dataset. Our Florence-2 VQA model achieved ROUGE-1 of 0.92, ROUGE-L of 0.91, and BLEU score improvements from 0.08 to 0.24. Fine-tuning on private datasets consistently showed better results than fine-tuning on public datasets. The rank-4 LoRA synthesis achieved optimal performance with a fidelity score of 0.290, an agreement score of 0.730, and a Frechet BiomedCLIP Distance (FBD) of 1450, reducing computational costs by almost 90 percent. This framework improves the clinical potential of AI in GI endoscopy. Compared to FLUX, MSDM, and Kandinsky 2.2, our model demonstrates superior FBD and strong semantic alignment. While other models lead in Fidelity or Agreement, our lower FBD indicates better image-text coherence. These results establish our approach as a robust solution for enhancing VQA and synthetic data generation in clinical AI.
Synthetic Data-Driven Multi-Architecture Framework for Automated Polyp Segmentation Through Integrated Detection and Mask Generation
Aug 08, 2025Colonoscopy is a vital tool for the early diagnosis of colorectal cancer, which is one of the main causes of cancer-related mortality globally; hence, it is deemed an essential technique for the prevention and early detection of colorectal cancer. The research introduces a unique multidirectional architectural framework to automate polyp detection within colonoscopy images while helping resolve limited healthcare dataset sizes and annotation complexities. The research implements a comprehensive system that delivers synthetic data generation through Stable Diffusion enhancements together with detection and segmentation algorithms. This detection approach combines Faster R-CNN for initial object localization while the Segment Anything Model (SAM) refines the segmentation masks. The faster R-CNN detection algorithm achieved a recall of 93.08% combined with a precision of 88.97% and an F1 score of 90.98%.SAM is then used to generate the image mask. The research evaluated five state-of-the-art segmentation models that included U-Net, PSPNet, FPN, LinkNet, and MANet using ResNet34 as a base model. The results demonstrate the superior performance of FPN with the highest scores of PSNR (7.205893) and SSIM (0.492381), while UNet excels in recall (84.85%) and LinkNet shows balanced performance in IoU (64.20%) and Dice score (77.53%).
Advancing AI-Powered Medical Image Synthesis: Insights from MedVQA-GI Challenge Using CLIP, Fine-Tuned Stable Diffusion, and Dream-Booth + LoRA
Feb 28, 2025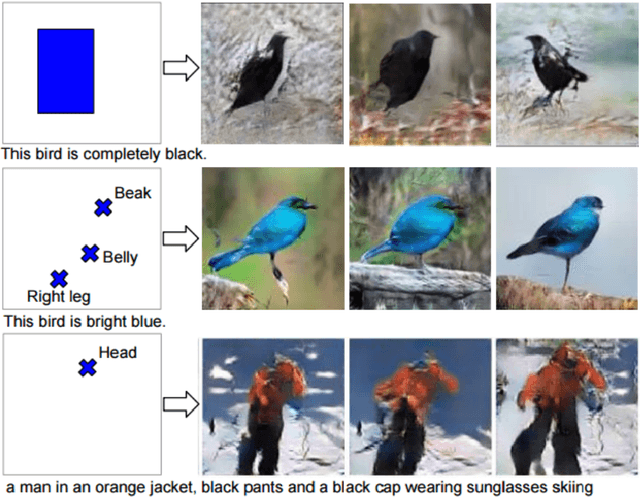

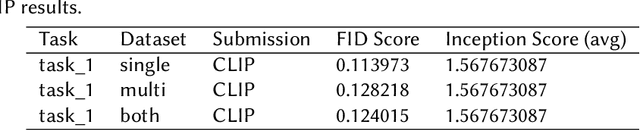
The MEDVQA-GI challenge addresses the integration of AI-driven text-to-image generative models in medical diagnostics, aiming to enhance diagnostic capabilities through synthetic image generation. Existing methods primarily focus on static image analysis and lack the dynamic generation of medical imagery from textual descriptions. This study intends to partially close this gap by introducing a novel approach based on fine-tuned generative models to generate dynamic, scalable, and precise images from textual descriptions. Particularly, our system integrates fine-tuned Stable Diffusion and DreamBooth models, as well as Low-Rank Adaptation (LORA), to generate high-fidelity medical images. The problem is around two sub-tasks namely: image synthesis (IS) and optimal prompt production (OPG). The former creates medical images via verbal prompts, whereas the latter provides prompts that produce high-quality images in specified categories. The study emphasizes the limitations of traditional medical image generation methods, such as hand sketching, constrained datasets, static procedures, and generic models. Our evaluation measures showed that Stable Diffusion surpasses CLIP and DreamBooth + LORA in terms of producing high-quality, diversified images. Specifically, Stable Diffusion had the lowest Fr\'echet Inception Distance (FID) scores (0.099 for single center, 0.064 for multi-center, and 0.067 for combined), indicating higher image quality. Furthermore, it had the highest average Inception Score (2.327 across all datasets), indicating exceptional diversity and quality. This advances the field of AI-powered medical diagnosis. Future research will concentrate on model refining, dataset augmentation, and ethical considerations for efficiently implementing these advances into clinical practice
Mining Weighted Sequential Patterns in Incremental Uncertain Databases
Mar 31, 2024Due to the rapid development of science and technology, the importance of imprecise, noisy, and uncertain data is increasing at an exponential rate. Thus, mining patterns in uncertain databases have drawn the attention of researchers. Moreover, frequent sequences of items from these databases need to be discovered for meaningful knowledge with great impact. In many real cases, weights of items and patterns are introduced to find interesting sequences as a measure of importance. Hence, a constraint of weight needs to be handled while mining sequential patterns. Besides, due to the dynamic nature of databases, mining important information has become more challenging. Instead of mining patterns from scratch after each increment, incremental mining algorithms utilize previously mined information to update the result immediately. Several algorithms exist to mine frequent patterns and weighted sequences from incremental databases. However, these algorithms are confined to mine the precise ones. Therefore, we have developed an algorithm to mine frequent sequences in an uncertain database in this work. Furthermore, we have proposed two new techniques for mining when the database is incremental. Extensive experiments have been conducted for performance evaluation. The analysis showed the efficiency of our proposed framework.
* Accepted to Information Science journal
Unbiased Pain Assessment through Wearables and EHR Data: Multi-attribute Fairness Loss-based CNN Approach
Jul 03, 2023The combination of diverse health data (IoT, EHR, and clinical surveys) and scalable-adaptable Artificial Intelligence (AI), has enabled the discovery of physical, behavioral, and psycho-social indicators of pain status. Despite the hype and promise to fundamentally alter the healthcare system with technological advancements, much AI adoption in clinical pain evaluation has been hampered by the heterogeneity of the problem itself and other challenges, such as personalization and fairness. Studies have revealed that many AI (i.e., machine learning or deep learning) models display biases and discriminate against specific population segments (such as those based on gender or ethnicity), which breeds skepticism among medical professionals about AI adaptability. In this paper, we propose a Multi-attribute Fairness Loss (MAFL) based CNN model that aims to account for any sensitive attributes included in the data and fairly predict patients' pain status while attempting to minimize the discrepancies between privileged and unprivileged groups. In order to determine whether the trade-off between accuracy and fairness can be satisfied, we compare the proposed model with well-known existing mitigation procedures, and studies reveal that the implemented model performs favorably in contrast to state-of-the-art methods. Utilizing NIH All-Of-US data, where a cohort of 868 distinct individuals with wearables and EHR data gathered over 1500 days has been taken into consideration to analyze our suggested fair pain assessment system.
Augmenting Deep Learning Adaptation for Wearable Sensor Data through Combined Temporal-Frequency Image Encoding
Jul 03, 2023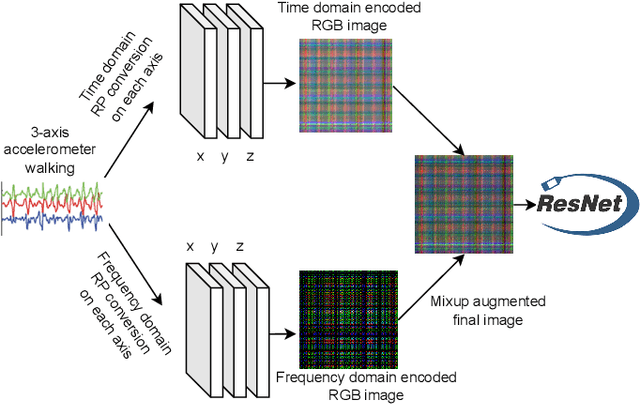
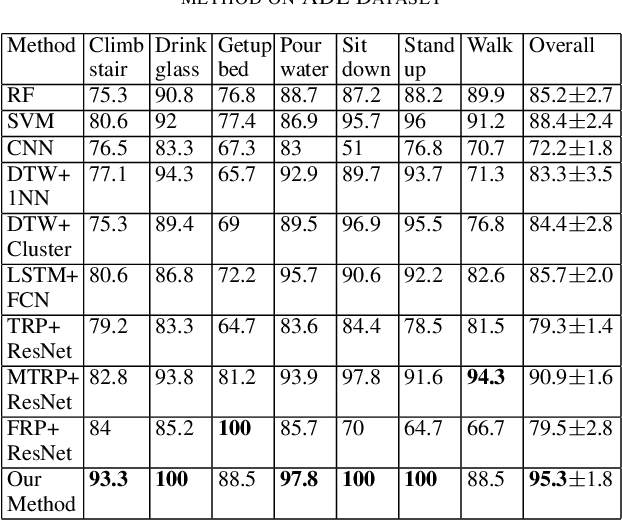
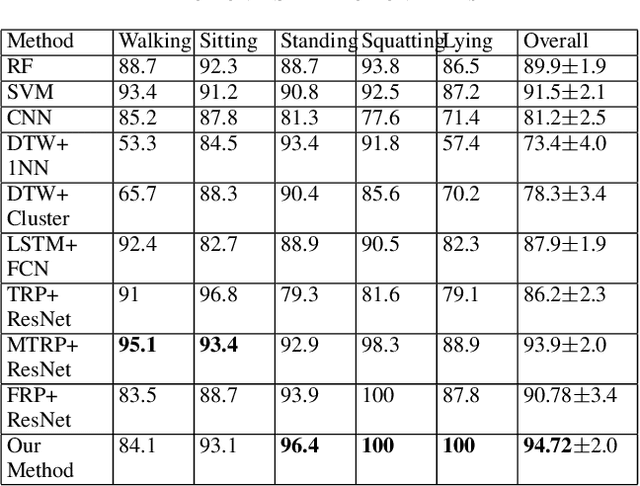
Deep learning advancements have revolutionized scalable classification in many domains including computer vision. However, when it comes to wearable-based classification and domain adaptation, existing computer vision-based deep learning architectures and pretrained models trained on thousands of labeled images for months fall short. This is primarily because wearable sensor data necessitates sensor-specific preprocessing, architectural modification, and extensive data collection. To overcome these challenges, researchers have proposed encoding of wearable temporal sensor data in images using recurrent plots. In this paper, we present a novel modified-recurrent plot-based image representation that seamlessly integrates both temporal and frequency domain information. Our approach incorporates an efficient Fourier transform-based frequency domain angular difference estimation scheme in conjunction with the existing temporal recurrent plot image. Furthermore, we employ mixup image augmentation to enhance the representation. We evaluate the proposed method using accelerometer-based activity recognition data and a pretrained ResNet model, and demonstrate its superior performance compared to existing approaches.
Semi-Supervised Domain Adaptation with Auto-Encoder via Simultaneous Learning
Oct 18, 2022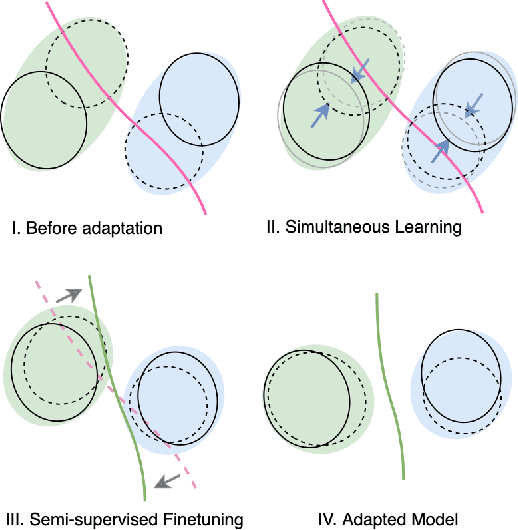
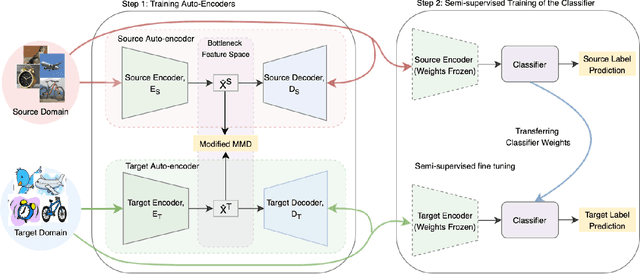
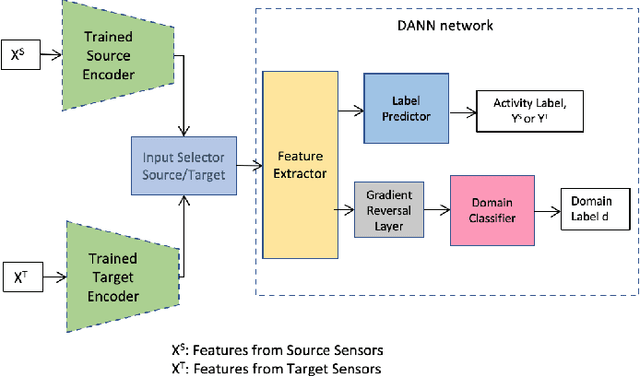
We present a new semi-supervised domain adaptation framework that combines a novel auto-encoder-based domain adaptation model with a simultaneous learning scheme providing stable improvements over state-of-the-art domain adaptation models. Our framework holds strong distribution matching property by training both source and target auto-encoders using a novel simultaneous learning scheme on a single graph with an optimally modified MMD loss objective function. Additionally, we design a semi-supervised classification approach by transferring the aligned domain invariant feature spaces from source domain to the target domain. We evaluate on three datasets and show proof that our framework can effectively solve both fragile convergence (adversarial) and weak distribution matching problems between source and target feature space (discrepancy) with a high `speed' of adaptation requiring a very low number of iterations.
Enabling Heterogeneous Domain Adaptation in Multi-inhabitants Smart Home Activity Learning
Oct 18, 2022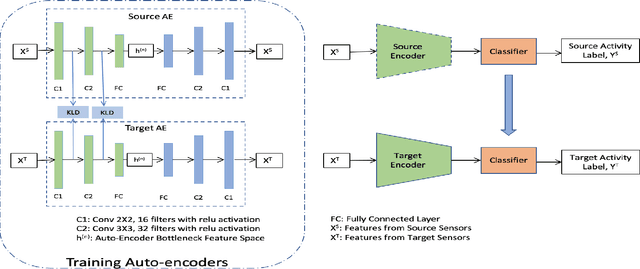
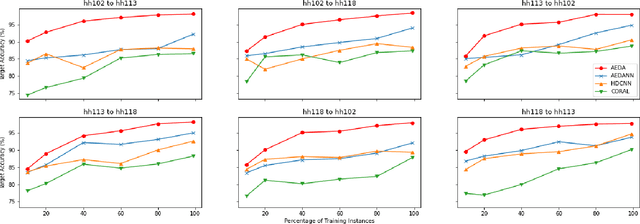
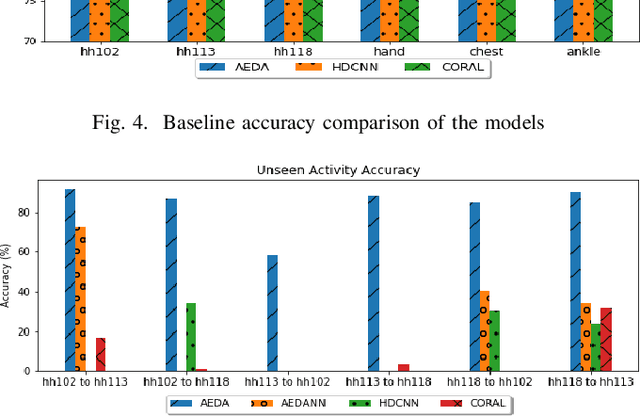
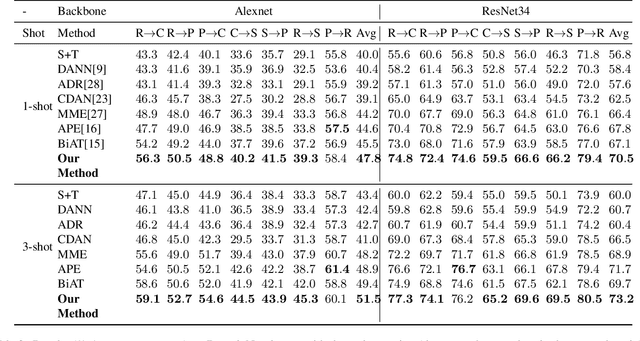
Domain adaptation for sensor-based activity learning is of utmost importance in remote health monitoring research. However, many domain adaptation algorithms suffer with failure to operate adaptation in presence of target domain heterogeneity (which is always present in reality) and presence of multiple inhabitants dramatically hinders their generalizability producing unsatisfactory results for semi-supervised and unseen activity learning tasks. We propose \emph{AEDA}, a novel deep auto-encoder-based model to enable semi-supervised domain adaptation in the existence of target domain heterogeneity and how to incorporate it to empower heterogeneity to any homogeneous deep domain adaptation architecture for cross-domain activity learning. Experimental evaluation on 18 different heterogeneous and multi-inhabitants use-cases of 8 different domains created from 2 publicly available human activity datasets (wearable and ambient smart homes) shows that \emph{AEDA} outperforms (max. 12.8\% and 8.9\% improvements for ambient smart home and wearables) over existing domain adaptation techniques for both seen and unseen activity learning in a heterogeneous setting.
Pseudo value-based Deep Neural Networks for Multi-state Survival Analysis
Jul 12, 2022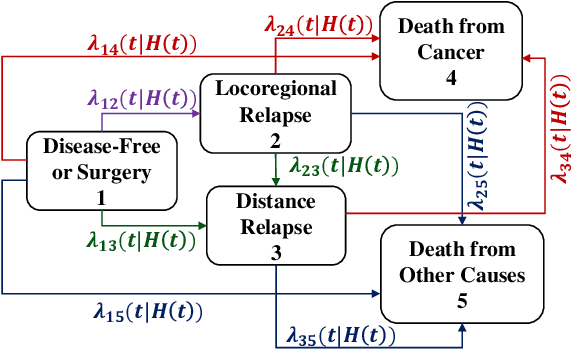
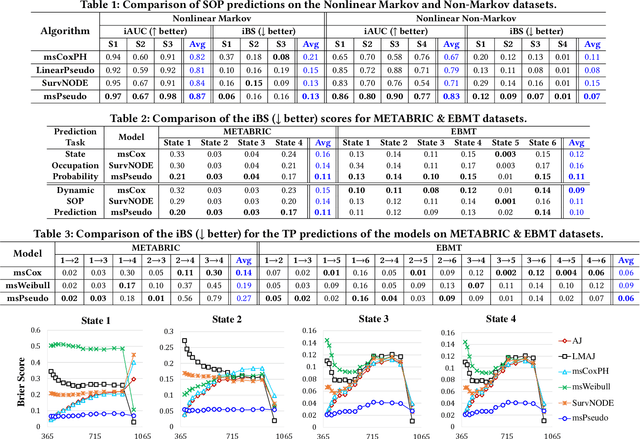
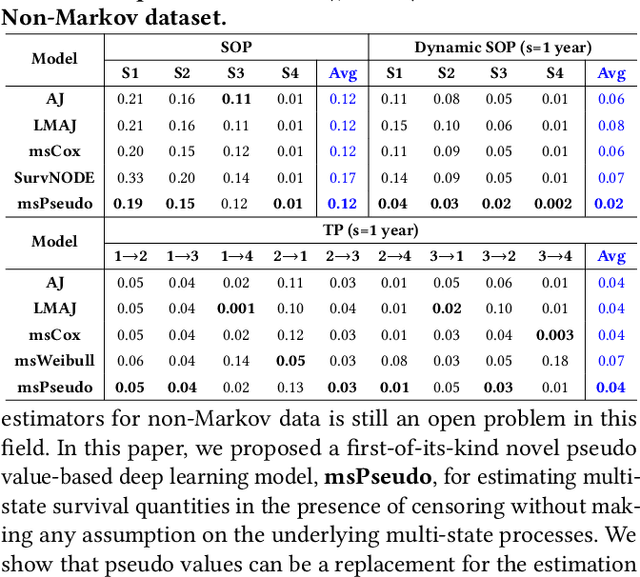
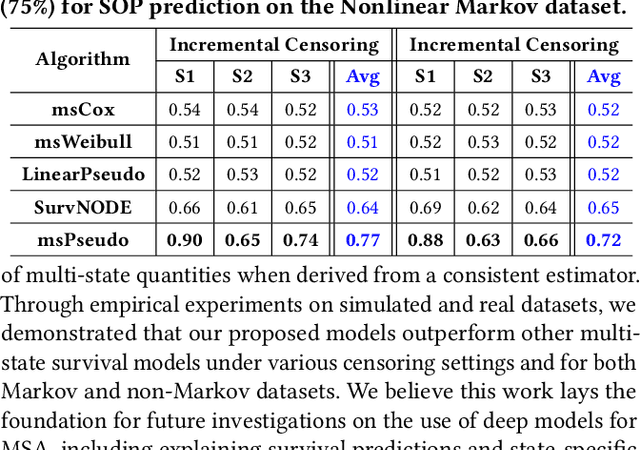
Multi-state survival analysis (MSA) uses multi-state models for the analysis of time-to-event data. In medical applications, MSA can provide insights about the complex disease progression in patients. A key challenge in MSA is the accurate subject-specific prediction of multi-state model quantities such as transition probability and state occupation probability in the presence of censoring. Traditional multi-state methods such as Aalen-Johansen (AJ) estimators and Cox-based methods are respectively limited by Markov and proportional hazards assumptions and are infeasible for making subject-specific predictions. Neural ordinary differential equations for MSA relax these assumptions but are computationally expensive and do not directly model the transition probabilities. To address these limitations, we propose a new class of pseudo-value-based deep learning models for multi-state survival analysis, where we show that pseudo values - designed to handle censoring - can be a natural replacement for estimating the multi-state model quantities when derived from a consistent estimator. In particular, we provide an algorithm to derive pseudo values from consistent estimators to directly predict the multi-state survival quantities from the subject's covariates. Empirical results on synthetic and real-world datasets show that our proposed models achieve state-of-the-art results under various censoring settings.
FedPseudo: Pseudo value-based Deep Learning Models for Federated Survival Analysis
Jul 12, 2022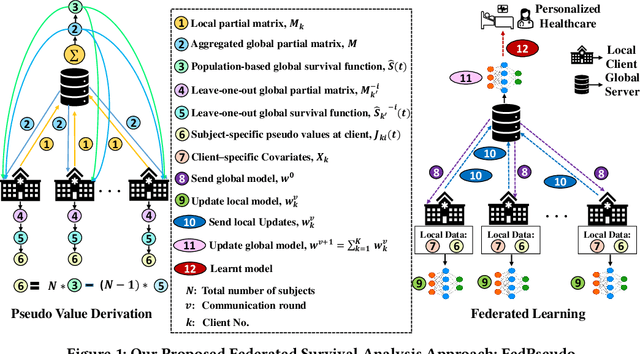
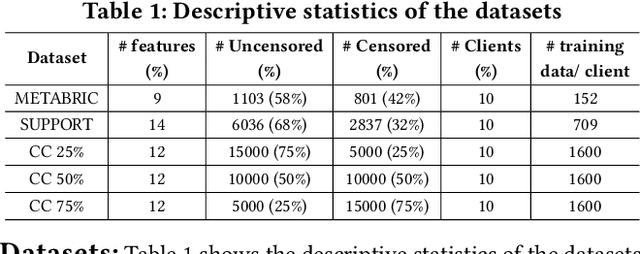
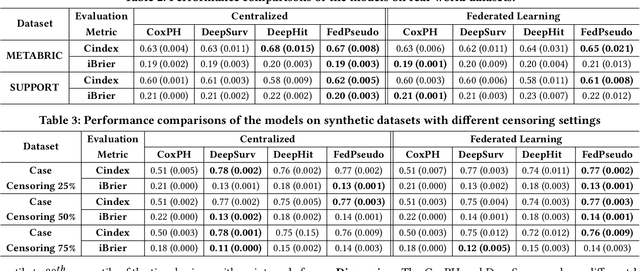
Survival analysis, time-to-event analysis, is an important problem in healthcare since it has a wide-ranging impact on patients and palliative care. Many survival analysis methods have assumed that the survival data is centrally available either from one medical center or by data sharing from multi-centers. However, the sensitivity of the patient attributes and the strict privacy laws have increasingly forbidden sharing of healthcare data. To address this challenge, the research community has looked at the solution of decentralized training and sharing of model parameters using the Federated Learning (FL) paradigm. In this paper, we study the utilization of FL for performing survival analysis on distributed healthcare datasets. Recently, the popular Cox proportional hazard (CPH) models have been adapted for FL settings; however, due to its linearity and proportional hazards assumptions, CPH models result in suboptimal performance, especially for non-linear, non-iid, and heavily censored survival datasets. To overcome the challenges of existing federated survival analysis methods, we leverage the predictive accuracy of the deep learning models and the power of pseudo values to propose a first-of-its-kind, pseudo value-based deep learning model for federated survival analysis (FSA) called FedPseudo. Furthermore, we introduce a novel approach of deriving pseudo values for survival probability in the FL settings that speeds up the computation of pseudo values. Extensive experiments on synthetic and real-world datasets show that our pseudo valued-based FL framework achieves similar performance as the best centrally trained deep survival analysis model. Moreover, our proposed FL approach obtains the best results for various censoring settings.