 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Average Relative Entropy and Transpilation Depth determines the noise robustness in Variational Quantum Classifiers
Mar 22, 2026Variational Quantum Algorithms (VQAs) have been extensively researched for applications in Quantum Machine Learning (QML), Optimization, and Molecular simulations. Although designed for Noisy Intermediate-Scale Quantum (NISQ) devices, VQAs are predominantly evaluated classically due to uncertain results on noisy devices and limited resource availability. Raising concern over the reproducibility of simulated VQAs on noisy hardware. While prior studies indicate that VQAs may exhibit noise resilience in specific parameterized shallow quantum circuits, there are no definitive measures to establish what defines a shallow circuit or the optimal circuit depth for VQAs on a noisy platform. These challenges extend naturally to Variational Quantum Classification (VQC) algorithms, a subclass of VQAs for supervised learning. In this article, we propose a relative entropy-based metric to verify whether a VQC model would perform similarly on a noisy device as it does on simulations. We establish a strong correlation between the average relative entropy difference in classes, transpilation circuit depth, and their performance difference on a noisy quantum device. Our results further indicate that circuit depth alone is insufficient to characterize shallow circuits. We present empirical evidence to support these assertions across a diverse array of techniques for implementing VQC, datasets, and multiple noisy quantum devices.
Performance Estimation in Binary Classification Using Calibrated Confidence
May 08, 2025Model monitoring is a critical component of the machine learning lifecycle, safeguarding against undetected drops in the model's performance after deployment. Traditionally, performance monitoring has required access to ground truth labels, which are not always readily available. This can result in unacceptable latency or render performance monitoring altogether impossible. Recently, methods designed to estimate the accuracy of classifier models without access to labels have shown promising results. However, there are various other metrics that might be more suitable for assessing model performance in many cases. Until now, none of these important metrics has received similar interest from the scientific community. In this work, we address this gap by presenting CBPE, a novel method that can estimate any binary classification metric defined using the confusion matrix. In particular, we choose four metrics from this large family: accuracy, precision, recall, and F$_1$, to demonstrate our method. CBPE treats the elements of the confusion matrix as random variables and leverages calibrated confidence scores of the model to estimate their distributions. The desired metric is then also treated as a random variable, whose full probability distribution can be derived from the estimated confusion matrix. CBPE is shown to produce estimates that come with strong theoretical guarantees and valid confidence intervals.
How Large Language Models Are Changing MOOC Essay Answers: A Comparison of Pre- and Post-LLM Responses
Apr 17, 2025The release of ChatGPT in late 2022 caused a flurry of activity and concern in the academic and educational communities. Some see the tool's ability to generate human-like text that passes at least cursory inspections for factual accuracy ``often enough'' a golden age of information retrieval and computer-assisted learning. Some, on the other hand, worry the tool may lead to unprecedented levels of academic dishonesty and cheating. In this work, we quantify some of the effects of the emergence of Large Language Models (LLMs) on online education by analyzing a multi-year dataset of student essay responses from a free university-level MOOC on AI ethics. Our dataset includes essays submitted both before and after ChatGPT's release. We find that the launch of ChatGPT coincided with significant changes in both the length and style of student essays, mirroring observations in other contexts such as academic publishing. We also observe -- as expected based on related public discourse -- changes in prevalence of key content words related to AI and LLMs, but not necessarily the general themes or topics discussed in the student essays as identified through (dynamic) topic modeling.
Confidence-based Estimators for Predictive Performance in Model Monitoring
Jul 11, 2024After a machine learning model has been deployed into production, its predictive performance needs to be monitored. Ideally, such monitoring can be carried out by comparing the model's predictions against ground truth labels. For this to be possible, the ground truth labels must be available relatively soon after inference. However, there are many use cases where ground truth labels are available only after a significant delay, or in the worst case, not at all. In such cases, directly monitoring the model's predictive performance is impossible. Recently, novel methods for estimating the predictive performance of a model when ground truth is unavailable have been developed. Many of these methods leverage model confidence or other uncertainty estimates and are experimentally compared against a naive baseline method, namely Average Confidence (AC), which estimates model accuracy as the average of confidence scores for a given set of predictions. However, until now the theoretical properties of the AC method have not been properly explored. In this paper, we try to fill this gap by reviewing the AC method and show that under certain general assumptions, it is an unbiased and consistent estimator of model accuracy with many desirable properties. We also compare this baseline estimator against some more complex estimators empirically and show that in many cases the AC method is able to beat the others, although the comparative quality of the different estimators is heavily case-dependent.
Testing the Robustness of AutoML Systems
May 06, 2020
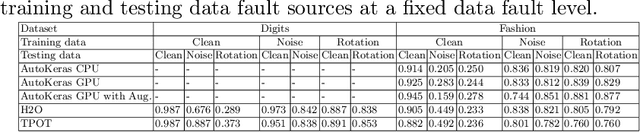
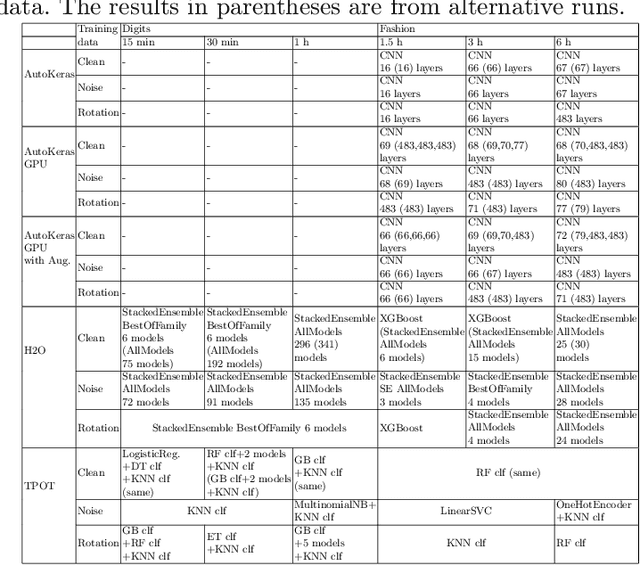
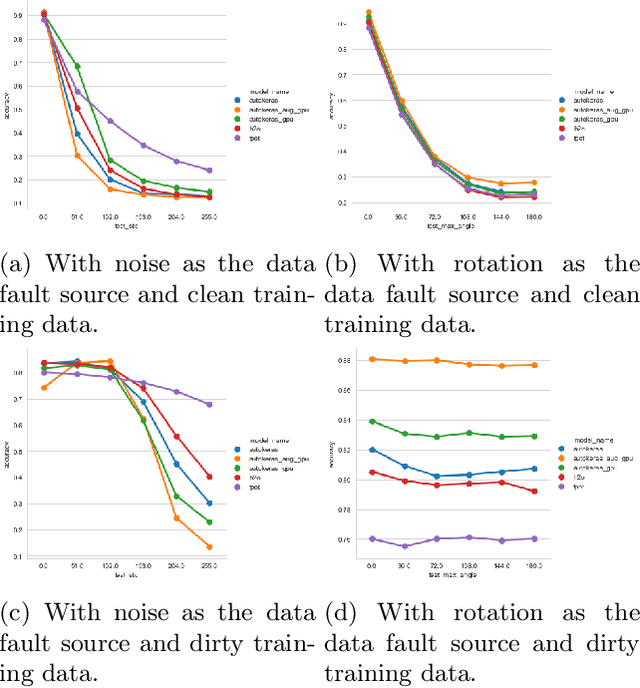
Automated machine learning (AutoML) systems aim at finding the best machine learning (ML) pipeline that automatically matches the task and data at hand. We investigate the robustness of machine learning pipelines generated with three AutoML systems, TPOT, H2O, and AutoKeras. In particular, we study the influence of dirty data on the accuracy, and consider how using dirty training data may help to create more robust solutions. Furthermore, we also analyze how the structure of the generated pipelines differs in different cases.