 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Program as Image: Evaluating Visual Representation of Source Code
Paper and Code

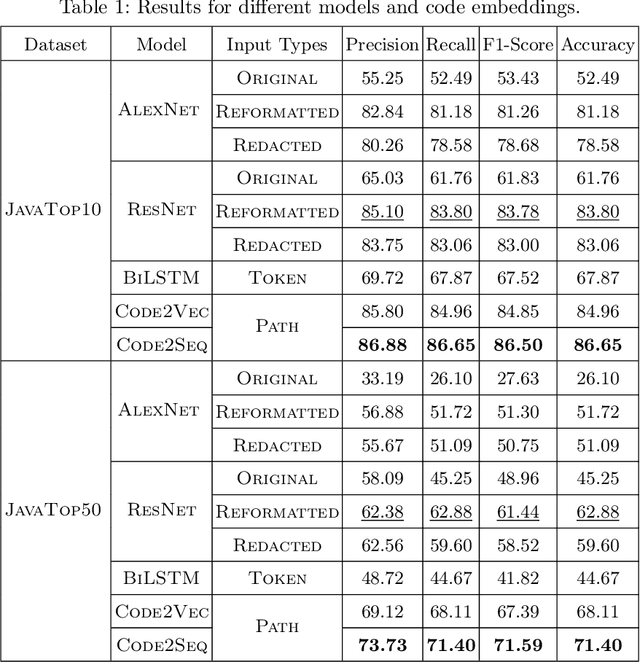

There are several approaches to encode source code in the input vectors of neural models. These approaches attempt to include various syntactic and semantic features of input programs in their encoding. In this paper, we investigate Code2Snapshot, a novel representation of the source code that is based on the snapshots of input programs. We evaluate several variations of this representation and compare its performance with state-of-the-art representations that utilize the rich syntactic and semantic features of input programs. Our preliminary study on the utility of Code2Snapshot in the code summarization task suggests that simple snapshots of input programs have comparable performance to the state-of-the-art representations. Interestingly, obscuring the input programs have insignificant impacts on the Code2Snapshot performance, suggesting that, for some tasks, neural models may provide high performance by relying merely on the structure of input programs.