 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Source Code with Structural and Functional Properties
Paper and Code

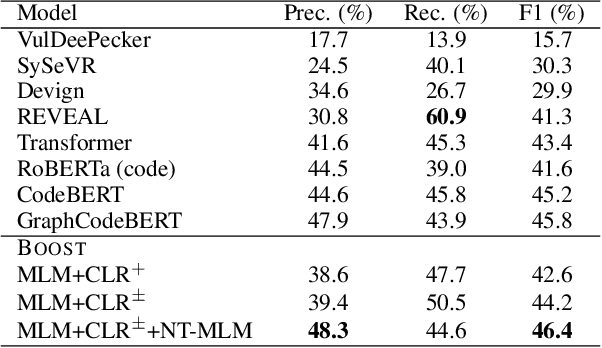
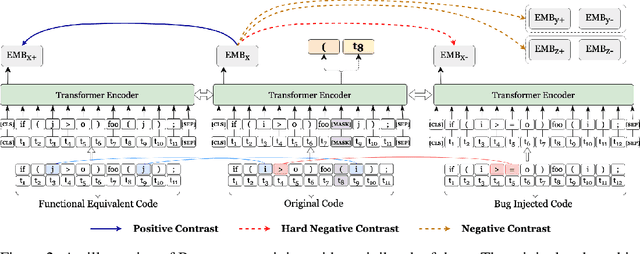

Pre-trained transformer models have recently shown promises for understanding the source code. Most existing works expect to understand code from the textual features and limited structural knowledge of code. However, the program functionalities sometimes cannot be fully revealed by the code sequence, even with structure information. Programs can contain very different tokens and structures while sharing the same functionality, but changing only one or a few code tokens can introduce unexpected or malicious program behaviors while preserving the syntax and most tokens. In this work, we present BOOST, a novel self-supervised model to focus pre-training based on the characteristics of source code. We first employ automated, structure-guided code transformation algorithms that generate (i.) functionally equivalent code that looks drastically different from the original one, and (ii.) textually and syntactically very similar code that is functionally distinct from the original. We train our model in a way that brings the functionally equivalent code closer and distinct code further through a contrastive learning objective. To encode the structure information, we introduce a new node-type masked language model objective that helps the model learn about structural context. We pre-train BOOST with a much smaller dataset than the state-of-the-art models, but our small models can still match or outperform these large models in code understanding and generation tasks.