 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Alternative Ways of Performing a Task
Apr 03, 2024A common way of learning to perform a task is to observe how it is carried out by experts. However, it is well known that for most tasks there is no unique way to perform them. This is especially noticeable the more complex the task is because factors such as the skill or the know-how of the expert may well affect the way she solves the task. In addition, learning from experts also suffers of having a small set of training examples generally coming from several experts (since experts are usually a limited and expensive resource), being all of them positive examples (i.e. examples that represent successful executions of the task). Traditional machine learning techniques are not useful in such scenarios, as they require extensive training data. Starting from very few executions of the task presented as activity sequences, we introduce a novel inductive approach for learning multiple models, with each one representing an alternative strategy of performing a task. By an iterative process based on generalisation and specialisation, we learn the underlying patterns that capture the different styles of performing a task exhibited by the examples. We illustrate our approach on two common activity recognition tasks: a surgical skills training task and a cooking domain. We evaluate the inferred models with respect to two metrics that measure how well the models represent the examples and capture the different forms of executing a task showed by the examples. We compare our results with the traditional process mining approach and show that a small set of meaningful examples is enough to obtain patterns that capture the different strategies that are followed to solve the tasks.
* 32 pages, Github repository, published paper, authors' version
General-purpose Declarative Inductive Programming with Domain-Specific Background Knowledge for Data Wrangling Automation
Sep 26, 2018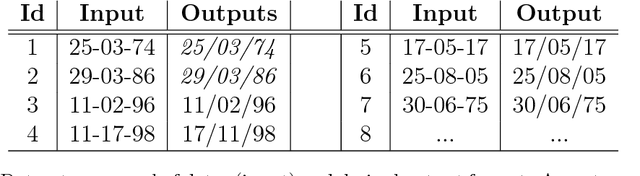

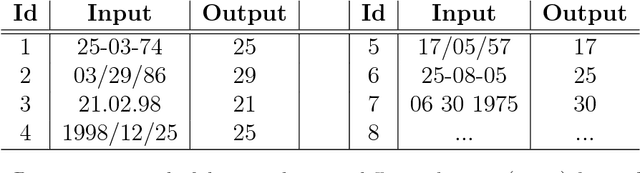
Given one or two examples, humans are good at understanding how to solve a problem independently of its domain, because they are able to detect what the problem is and to choose the appropriate background knowledge according to the context. For instance, presented with the string "8/17/2017" to be transformed to "17th of August of 2017", humans will process this in two steps: (1) they recognise that it is a date and (2) they map the date to the 17th of August of 2017. Inductive Programming (IP) aims at learning declarative (functional or logic) programs from examples. Two key advantages of IP are the use of background knowledge and the ability to synthesise programs from a few input/output examples (as humans do). In this paper we propose to use IP as a means for automating repetitive data manipulation tasks, frequently presented during the process of {\em data wrangling} in many data manipulation problems. Here we show that with the use of general-purpose declarative (programming) languages jointly with generic IP systems and the definition of domain-specific knowledge, many specific data wrangling problems from different application domains can be automatically solved from very few examples. We also propose an integrated benchmark for data wrangling, which we share publicly for the community.
Forgetting and consolidation for incremental and cumulative knowledge acquisition systems
Feb 19, 2015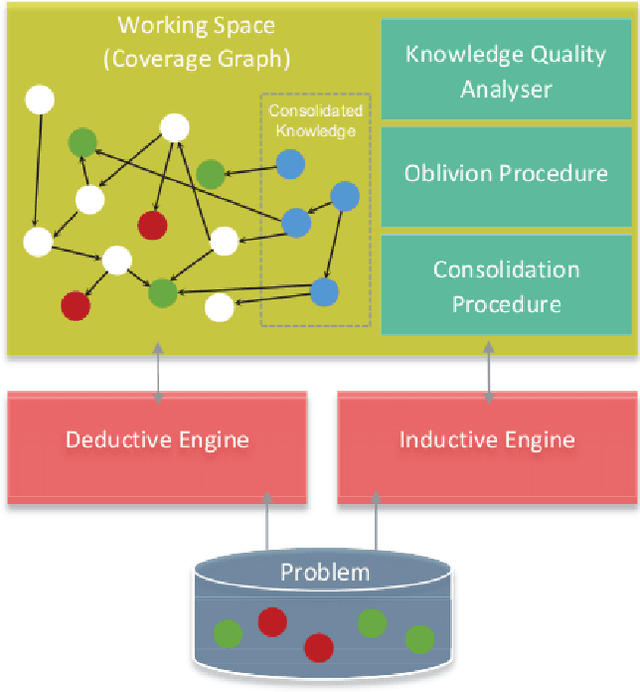
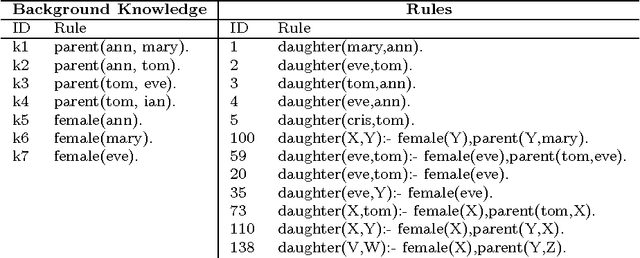
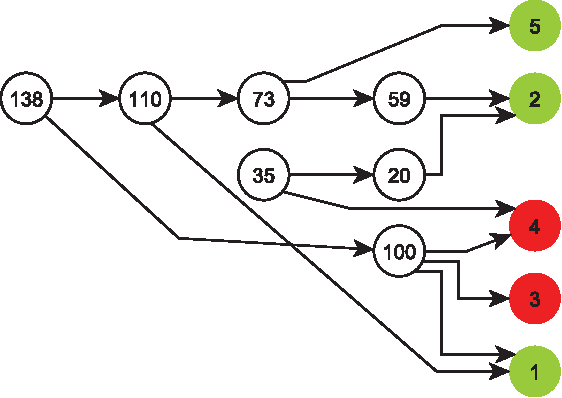

The application of cognitive mechanisms to support knowledge acquisition is, from our point of view, crucial for making the resulting models coherent, efficient, credible, easy to use and understandable. In particular, there are two characteristic features of intelligence that are essential for knowledge development: forgetting and consolidation. Both plays an important role in knowledge bases and learning systems to avoid possible information overflow and redundancy, and in order to preserve and strengthen important or frequently used rules and remove (or forget) useless ones. We present an incremental, long-life view of knowledge acquisition which tries to improve task after task by determining what to keep, what to consolidate and what to forget, overcoming The Stability-Plasticity dilemma. In order to do that, we rate rules by introducing several metrics through the first adaptation, to our knowledge, of the Minimum Message Length (MML) principle to a coverage graph, a hierarchical assessment structure which treats evidence and rules in a unified way. The metrics are not only used to forget some of the worst rules, but also to set a consolidation process to promote those selected rules to the knowledge base, which is also mirrored by a demotion system. We evaluate the framework with a series of tasks in a chess rule learning domain.