 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-parallel Emotion Conversion using a Deep-Generative Hybrid Network and an Adversarial Pair Discriminator
Aug 10, 2020


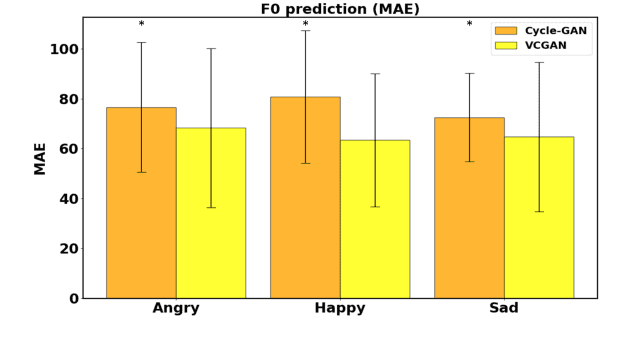
We introduce a novel method for emotion conversion in speech that does not require parallel training data. Our approach loosely relies on a cycle-GAN schema to minimize the reconstruction error from converting back and forth between emotion pairs. However, unlike the conventional cycle-GAN, our discriminator classifies whether a pair of input real and generated samples corresponds to the desired emotion conversion (e.g., A to B) or to its inverse (B to A). We will show that this setup, which we refer to as a variational cycle-GAN (VC-GAN), is equivalent to minimizing the empirical KL divergence between the source features and their cyclic counterpart. In addition, our generator combines a trainable deep network with a fixed generative block to implement a smooth and invertible transformation on the input features, in our case, the fundamental frequency (F0) contour. This hybrid architecture regularizes our adversarial training procedure. We use crowd sourcing to evaluate both the emotional saliency and the quality of synthesized speech. Finally, we show that our model generalizes to new speakers by modifying speech produced by Wavenet.