 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding (Non-)Robust Feature Disentanglement and the Relationship Between Low- and High-Dimensional Adversarial Attacks
Apr 04, 2020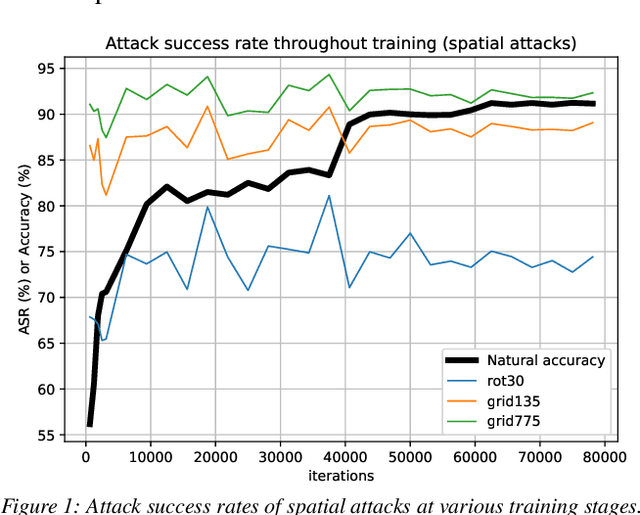
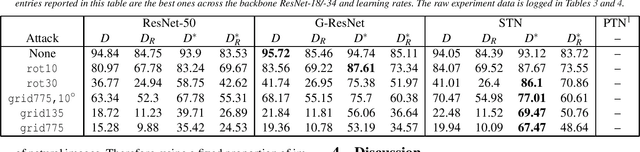
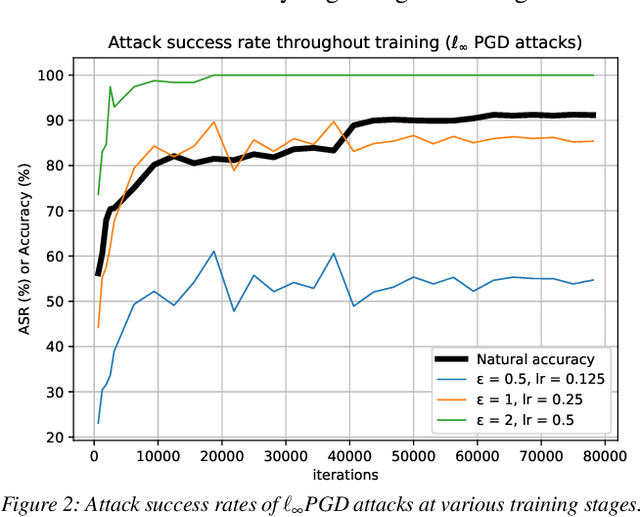

Recent work has put forth the hypothesis that adversarial vulnerabilities in neural networks are due to them overusing "non-robust features" inherent in the training data. We show empirically that for PGD-attacks, there is a training stage where neural networks start heavily relying on non-robust features to boost natural accuracy. We also propose a mechanism reducing vulnerability to PGD-style attacks consisting of mixing in a certain amount of images contain-ing mostly "robust features" into each training batch, and then show that robust accuracy is improved, while natural accuracy is not substantially hurt. We show that training on "robust features" provides boosts in robust accuracy across various architectures and for different attacks. Finally, we demonstrate empirically that these "robust features" do not induce spatial invariance.