 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMono3DVG-EnSD: Enhanced Spatial-aware and Dimension-decoupled Text Encoding for Monocular 3D Visual Grounding
Nov 10, 2025Monocular 3D Visual Grounding (Mono3DVG) is an emerging task that locates 3D objects in RGB images using text descriptions with geometric cues. However, existing methods face two key limitations. Firstly, they often over-rely on high-certainty keywords that explicitly identify the target object while neglecting critical spatial descriptions. Secondly, generalized textual features contain both 2D and 3D descriptive information, thereby capturing an additional dimension of details compared to singular 2D or 3D visual features. This characteristic leads to cross-dimensional interference when refining visual features under text guidance. To overcome these challenges, we propose Mono3DVG-EnSD, a novel framework that integrates two key components: the CLIP-Guided Lexical Certainty Adapter (CLIP-LCA) and the Dimension-Decoupled Module (D2M). The CLIP-LCA dynamically masks high-certainty keywords while retaining low-certainty implicit spatial descriptions, thereby forcing the model to develop a deeper understanding of spatial relationships in captions for object localization. Meanwhile, the D2M decouples dimension-specific (2D/3D) textual features from generalized textual features to guide corresponding visual features at same dimension, which mitigates cross-dimensional interference by ensuring dimensionally-consistent cross-modal interactions. Through comprehensive comparisons and ablation studies on the Mono3DRefer dataset, our method achieves state-of-the-art (SOTA) performance across all metrics. Notably, it improves the challenging Far(Acc@0.5) scenario by a significant +13.54%.
A Dual-stage Prompt-driven Privacy-preserving Paradigm for Person Re-Identification
Nov 07, 2025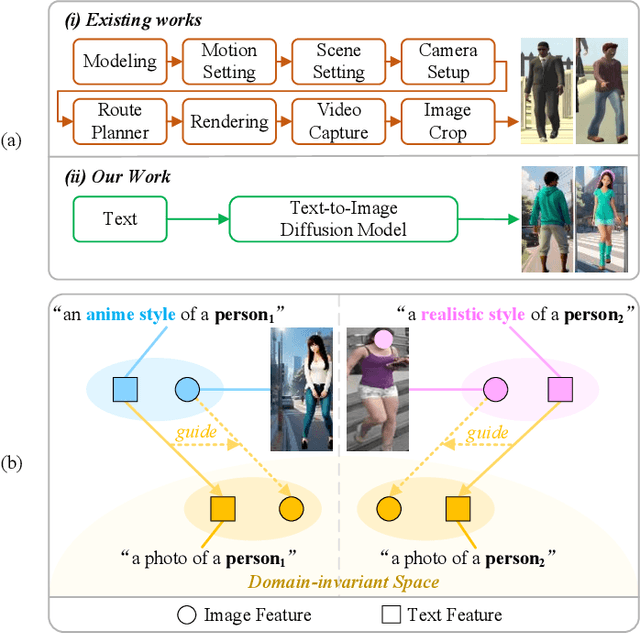
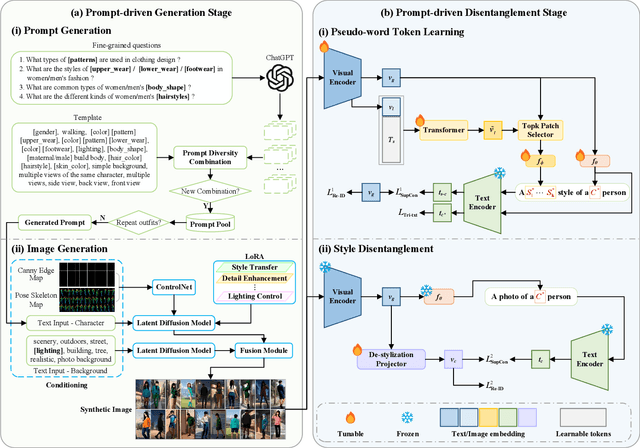
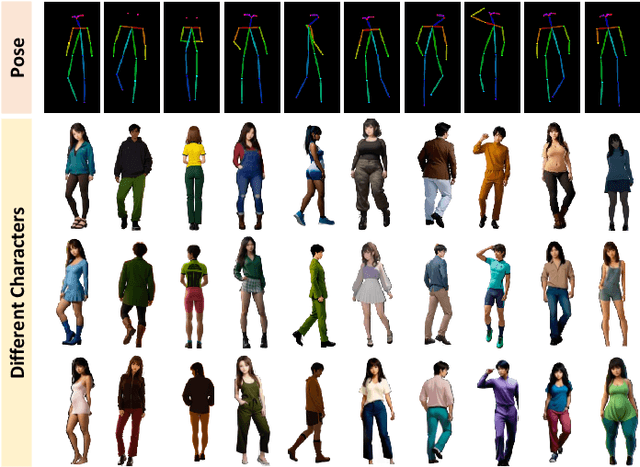

With growing concerns over data privacy, researchers have started using virtual data as an alternative to sensitive real-world images for training person re-identification (Re-ID) models. However, existing virtual datasets produced by game engines still face challenges such as complex construction and poor domain generalization, making them difficult to apply in real scenarios. To address these challenges, we propose a Dual-stage Prompt-driven Privacy-preserving Paradigm (DPPP). In the first stage, we generate rich prompts incorporating multi-dimensional attributes such as pedestrian appearance, illumination, and viewpoint that drive the diffusion model to synthesize diverse data end-to-end, building a large-scale virtual dataset named GenePerson with 130,519 images of 6,641 identities. In the second stage, we propose a Prompt-driven Disentanglement Mechanism (PDM) to learn domain-invariant generalization features. With the aid of contrastive learning, we employ two textual inversion networks to map images into pseudo-words representing style and content, respectively, thereby constructing style-disentangled content prompts to guide the model in learning domain-invariant content features at the image level. Experiments demonstrate that models trained on GenePerson with PDM achieve state-of-the-art generalization performance, surpassing those on popular real and virtual Re-ID datasets.
Dual Enhancement on 3D Vision-Language Perception for Monocular 3D Visual Grounding
Aug 26, 2025Monocular 3D visual grounding is a novel task that aims to locate 3D objects in RGB images using text descriptions with explicit geometry information. Despite the inclusion of geometry details in the text, we observe that the text embeddings are sensitive to the magnitude of numerical values but largely ignore the associated measurement units. For example, simply equidistant mapping the length with unit "meter" to "decimeters" or "centimeters" leads to severe performance degradation, even though the physical length remains equivalent. This observation signifies the weak 3D comprehension of pre-trained language model, which generates misguiding text features to hinder 3D perception. Therefore, we propose to enhance the 3D perception of model on text embeddings and geometry features with two simple and effective methods. Firstly, we introduce a pre-processing method named 3D-text Enhancement (3DTE), which enhances the comprehension of mapping relationships between different units by augmenting the diversity of distance descriptors in text queries. Next, we propose a Text-Guided Geometry Enhancement (TGE) module to further enhance the 3D-text information by projecting the basic text features into geometrically consistent space. These 3D-enhanced text features are then leveraged to precisely guide the attention of geometry features. We evaluate the proposed method through extensive comparisons and ablation studies on the Mono3DRefer dataset. Experimental results demonstrate substantial improvements over previous methods, achieving new state-of-the-art results with a notable accuracy gain of 11.94\% in the "Far" scenario. Our code will be made publicly available.
Prompt-driven Transferable Adversarial Attack on Person Re-Identification with Attribute-aware Textual Inversion
Feb 27, 2025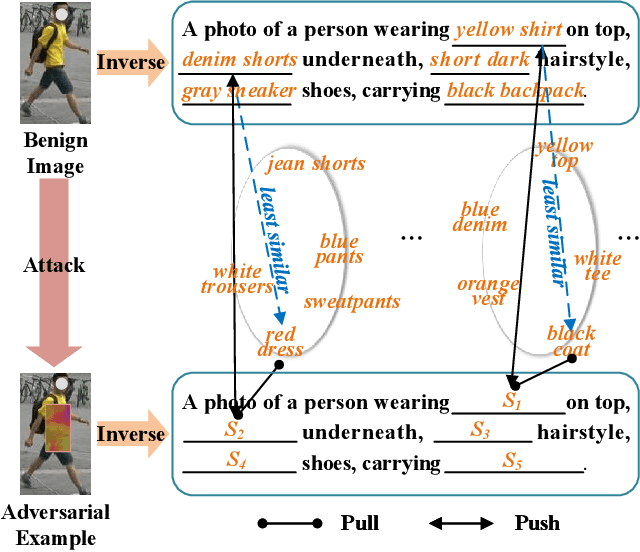
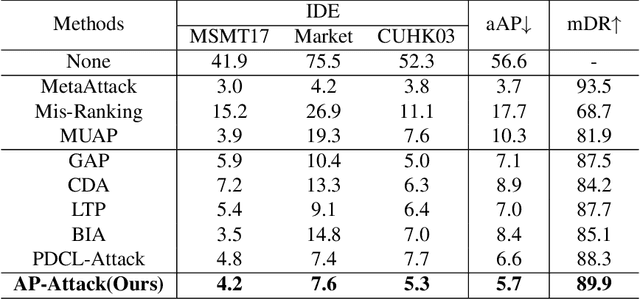
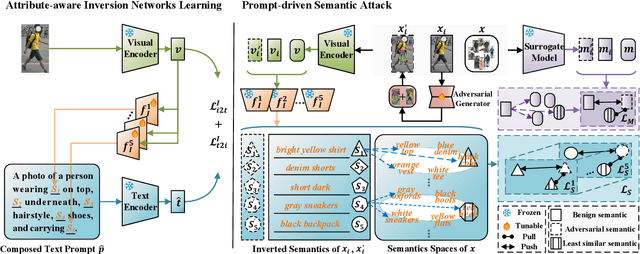
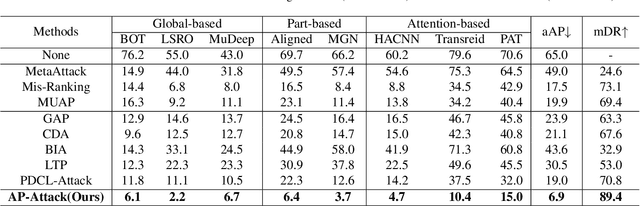
Person re-identification (re-id) models are vital in security surveillance systems, requiring transferable adversarial attacks to explore the vulnerabilities of them. Recently, vision-language models (VLM) based attacks have shown superior transferability by attacking generalized image and textual features of VLM, but they lack comprehensive feature disruption due to the overemphasis on discriminative semantics in integral representation. In this paper, we introduce the Attribute-aware Prompt Attack (AP-Attack), a novel method that leverages VLM's image-text alignment capability to explicitly disrupt fine-grained semantic features of pedestrian images by destroying attribute-specific textual embeddings. To obtain personalized textual descriptions for individual attributes, textual inversion networks are designed to map pedestrian images to pseudo tokens that represent semantic embeddings, trained in the contrastive learning manner with images and a predefined prompt template that explicitly describes the pedestrian attributes. Inverted benign and adversarial fine-grained textual semantics facilitate attacker in effectively conducting thorough disruptions, enhancing the transferability of adversarial examples. Extensive experiments show that AP-Attack achieves state-of-the-art transferability, significantly outperforming previous methods by 22.9% on mean Drop Rate in cross-model&dataset attack scenarios.
Learning to Learn Transferable Generative Attack for Person Re-Identification
Sep 06, 2024



Deep learning-based person re-identification (re-id) models are widely employed in surveillance systems and inevitably inherit the vulnerability of deep networks to adversarial attacks. Existing attacks merely consider cross-dataset and cross-model transferability, ignoring the cross-test capability to perturb models trained in different domains. To powerfully examine the robustness of real-world re-id models, the Meta Transferable Generative Attack (MTGA) method is proposed, which adopts meta-learning optimization to promote the generative attacker producing highly transferable adversarial examples by learning comprehensively simulated transfer-based cross-model\&dataset\&test black-box meta attack tasks. Specifically, cross-model\&dataset black-box attack tasks are first mimicked by selecting different re-id models and datasets for meta-train and meta-test attack processes. As different models may focus on different feature regions, the Perturbation Random Erasing module is further devised to prevent the attacker from learning to only corrupt model-specific features. To boost the attacker learning to possess cross-test transferability, the Normalization Mix strategy is introduced to imitate diverse feature embedding spaces by mixing multi-domain statistics of target models. Extensive experiments show the superiority of MTGA, especially in cross-model\&dataset and cross-model\&dataset\&test attacks, our MTGA outperforms the SOTA methods by 21.5\% and 11.3\% on mean mAP drop rate, respectively. The code of MTGA will be released after the paper is accepted.
Multi-Expert Adversarial Attack Detection in Person Re-identification Using Context Inconsistency
Aug 23, 2021
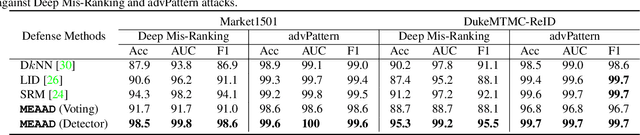
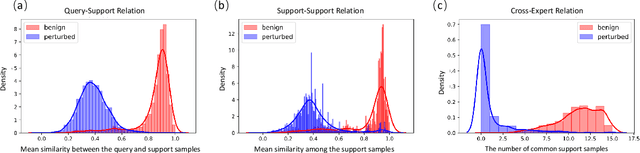

The success of deep neural networks (DNNs) haspromoted the widespread applications of person re-identification (ReID). However, ReID systems inherit thevulnerability of DNNs to malicious attacks of visually in-conspicuous adversarial perturbations. Detection of adver-sarial attacks is, therefore, a fundamental requirement forrobust ReID systems. In this work, we propose a Multi-Expert Adversarial Attack Detection (MEAAD) approach toachieve this goal by checking context inconsistency, whichis suitable for any DNN-based ReID systems. Specifically,three kinds of context inconsistencies caused by adversar-ial attacks are employed to learn a detector for distinguish-ing the perturbed examples, i.e., a) the embedding distancesbetween a perturbed query person image and its top-K re-trievals are generally larger than those between a benignquery image and its top-K retrievals, b) the embedding dis-tances among the top-K retrievals of a perturbed query im-age are larger than those of a benign query image, c) thetop-K retrievals of a benign query image obtained with mul-tiple expert ReID models tend to be consistent, which isnot preserved when attacks are present. Extensive exper-iments on the Market1501 and DukeMTMC-ReID datasetsshow that, as the first adversarial attack detection approachfor ReID,MEAADeffectively detects various adversarial at-tacks and achieves high ROC-AUC (over 97.5%).
Learning Person Re-identification Models from Videos with Weak Supervision
Jul 21, 2020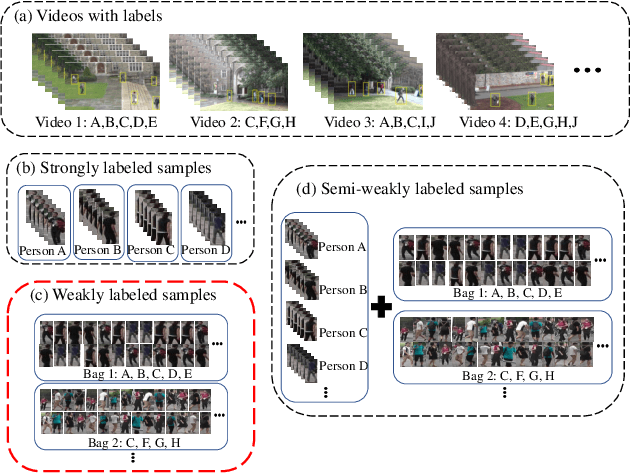
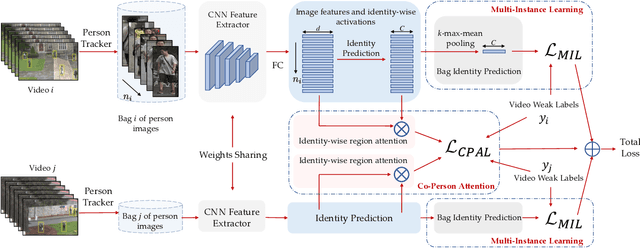
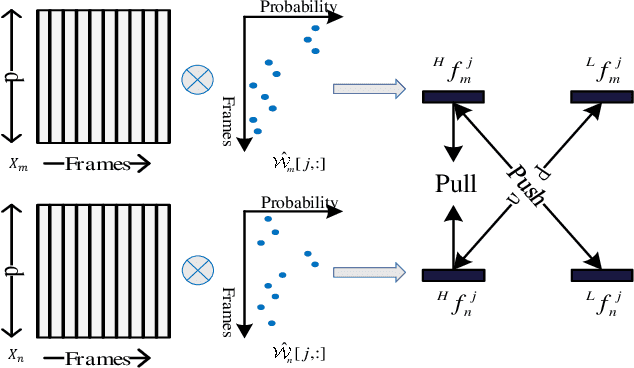
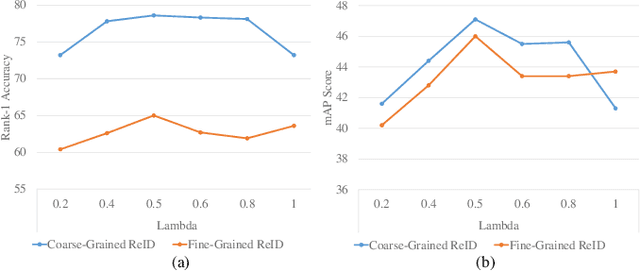
Most person re-identification methods, being supervised techniques, suffer from the burden of massive annotation requirement. Unsupervised methods overcome this need for labeled data, but perform poorly compared to the supervised alternatives. In order to cope with this issue, we introduce the problem of learning person re-identification models from videos with weak supervision. The weak nature of the supervision arises from the requirement of video-level labels, i.e. person identities who appear in the video, in contrast to the more precise framelevel annotations. Towards this goal, we propose a multiple instance attention learning framework for person re-identification using such video-level labels. Specifically, we first cast the video person re-identification task into a multiple instance learning setting, in which person images in a video are collected into a bag. The relations between videos with similar labels can be utilized to identify persons, on top of that, we introduce a co-person attention mechanism which mines the similarity correlations between videos with person identities in common. The attention weights are obtained based on all person images instead of person tracklets in a video, making our learned model less affected by noisy annotations. Extensive experiments demonstrate the superiority of the proposed method over the related methods on two weakly labeled person re-identification datasets.
Consistent Cross-view Matching for Unsupervised Person Re-identification
Aug 27, 2019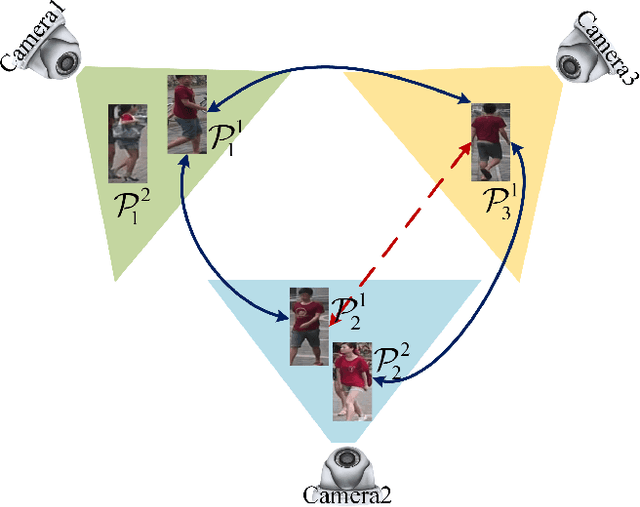
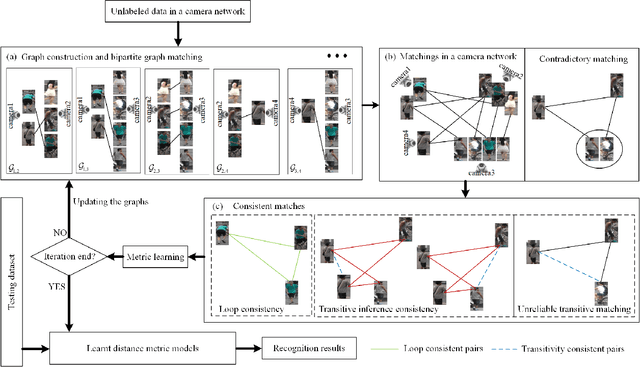
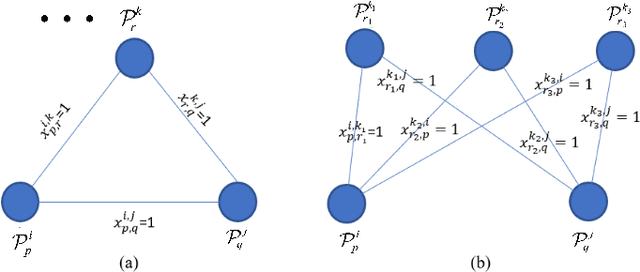
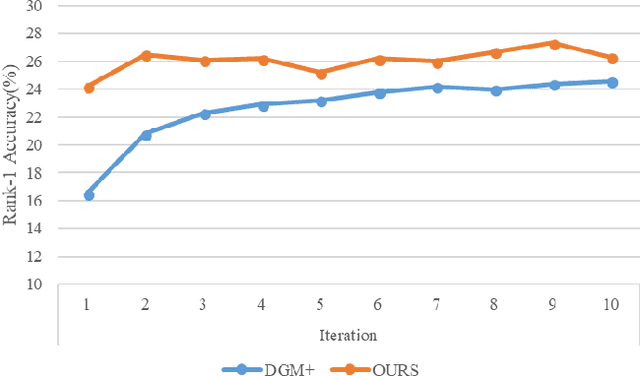
Most existing unsupervised person re-identificationmethods focus on learning an identity discriminative feature em-bedding for efficiently representing images of different persons.However, higher-order relationships across the entire cameranetwork are often ignored leading to contradictory outputs whenthe results of different camera pairs are combined. In this paper,we address this problem by proposing a consistent cross-viewmatching framework for unsupervised person re-identificationby exploiting more reliable positive image pairs in a cameranetwork. Specifically, we first construct a bipartite graph foreach pair of cameras, in which each node denotes a person, andthen graph matching is used to obtain optimal global matchesacross camera pairs. Thereafter, loop consistent and transitiveinference consistent constraints are introduced into the cross-view matches, which consider similarity relationshipsacross theentire camera networkto increase confidence in the matched/non-matched pairs. We then train distance metric models for eachcamera pair using the reliably matched image pairs. Finally,we embed the cross-view matching method into an iterativeupdating framework that iterates between the consistent cross-view matching and the cross-view distance metric learning. Wedemonstrate the superiority of the proposed method over thestate-of-the-art unsupervised person re-identification methodson three benchmark datasets such as Market1501, MARS andDukeMTMC-VideoReID datasets