 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Cross-view Matching for Unsupervised Person Re-identification
Aug 27, 2019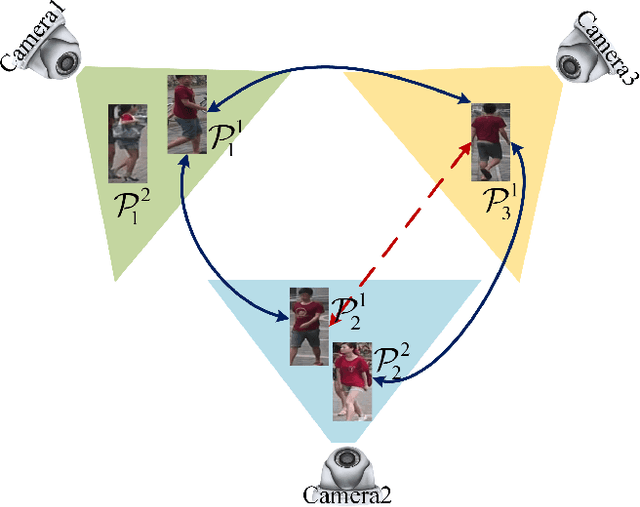
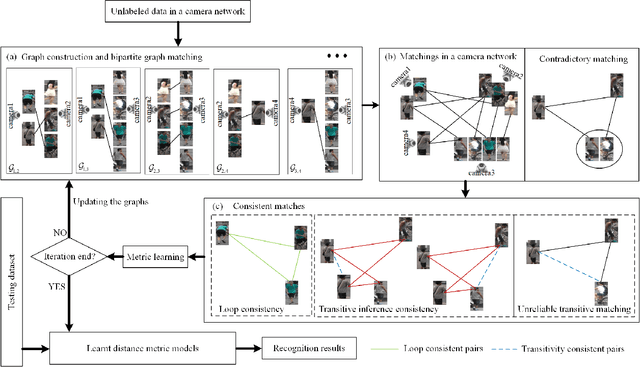
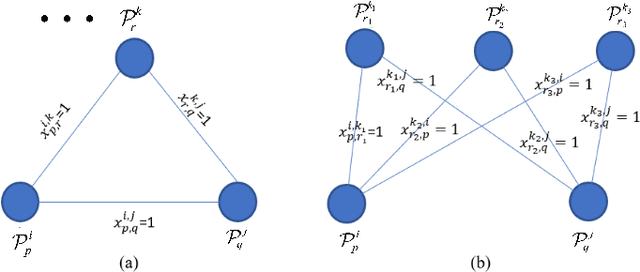
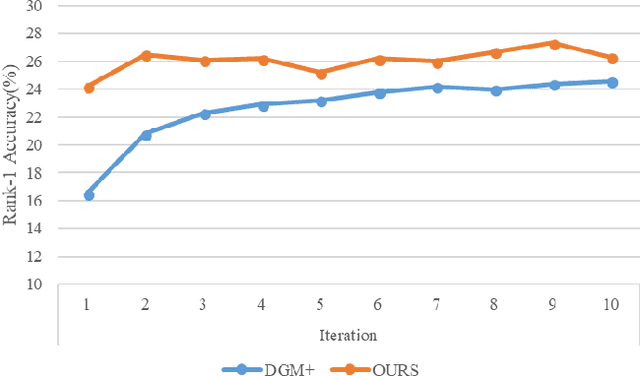
Most existing unsupervised person re-identificationmethods focus on learning an identity discriminative feature em-bedding for efficiently representing images of different persons.However, higher-order relationships across the entire cameranetwork are often ignored leading to contradictory outputs whenthe results of different camera pairs are combined. In this paper,we address this problem by proposing a consistent cross-viewmatching framework for unsupervised person re-identificationby exploiting more reliable positive image pairs in a cameranetwork. Specifically, we first construct a bipartite graph foreach pair of cameras, in which each node denotes a person, andthen graph matching is used to obtain optimal global matchesacross camera pairs. Thereafter, loop consistent and transitiveinference consistent constraints are introduced into the cross-view matches, which consider similarity relationshipsacross theentire camera networkto increase confidence in the matched/non-matched pairs. We then train distance metric models for eachcamera pair using the reliably matched image pairs. Finally,we embed the cross-view matching method into an iterativeupdating framework that iterates between the consistent cross-view matching and the cross-view distance metric learning. Wedemonstrate the superiority of the proposed method over thestate-of-the-art unsupervised person re-identification methodson three benchmark datasets such as Market1501, MARS andDukeMTMC-VideoReID datasets
W-TALC: Weakly-supervised Temporal Activity Localization and Classification
Aug 14, 2018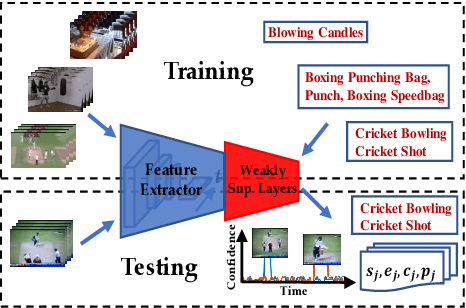
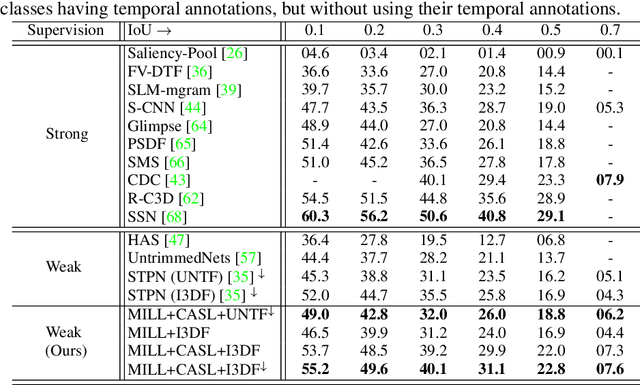
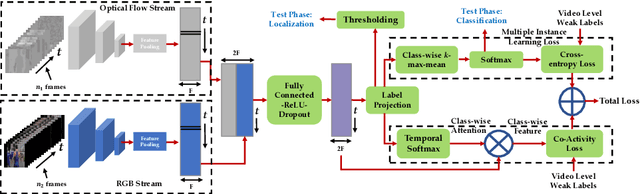

Most activity localization methods in the literature suffer from the burden of frame-wise annotation requirement. Learning from weak labels may be a potential solution towards reducing such manual labeling effort. Recent years have witnessed a substantial influx of tagged videos on the Internet, which can serve as a rich source of weakly-supervised training data. Specifically, the correlations between videos with similar tags can be utilized to temporally localize the activities. Towards this goal, we present W-TALC, a Weakly-supervised Temporal Activity Localization and Classification framework using only video-level labels. The proposed network can be divided into two sub-networks, namely the Two-Stream based feature extractor network and a weakly-supervised module, which we learn by optimizing two complimentary loss functions. Qualitative and quantitative results on two challenging datasets - Thumos14 and ActivityNet1.2, demonstrate that the proposed method is able to detect activities at a fine granularity and achieve better performance than current state-of-the-art methods.