 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-Term Spatial-Temporal Graphs for Active Speaker Detection
Jul 19, 2022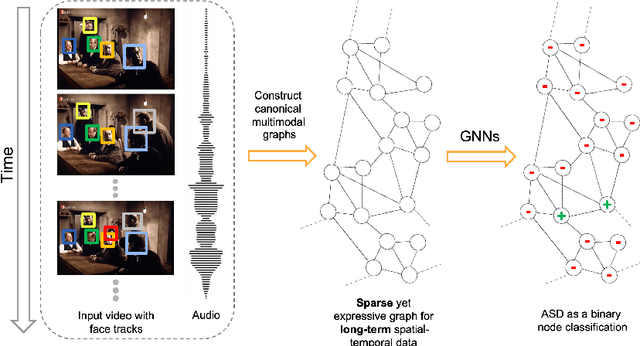

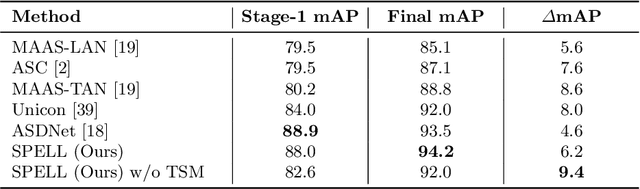
Active speaker detection (ASD) in videos with multiple speakers is a challenging task as it requires learning effective audiovisual features and spatial-temporal correlations over long temporal windows. In this paper, we present SPELL, a novel spatial-temporal graph learning framework that can solve complex tasks such as ASD. To this end, each person in a video frame is first encoded in a unique node for that frame. Nodes corresponding to a single person across frames are connected to encode their temporal dynamics. Nodes within a frame are also connected to encode inter-person relationships. Thus, SPELL reduces ASD to a node classification task. Importantly, SPELL is able to reason over long temporal contexts for all nodes without relying on computationally expensive fully connected graph neural networks. Through extensive experiments on the AVA-ActiveSpeaker dataset, we demonstrate that learning graph-based representations can significantly improve the active speaker detection performance owing to its explicit spatial and temporal structure. SPELL outperforms all previous state-of-the-art approaches while requiring significantly lower memory and computational resources. Our code is publicly available at https://github.com/SRA2/SPELL
Learning Spatial-Temporal Graphs for Active Speaker Detection
Dec 03, 2021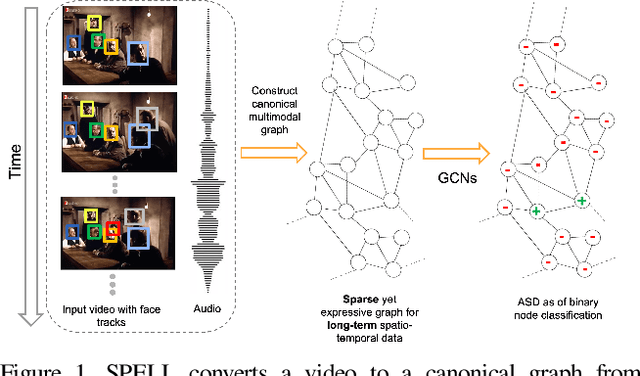
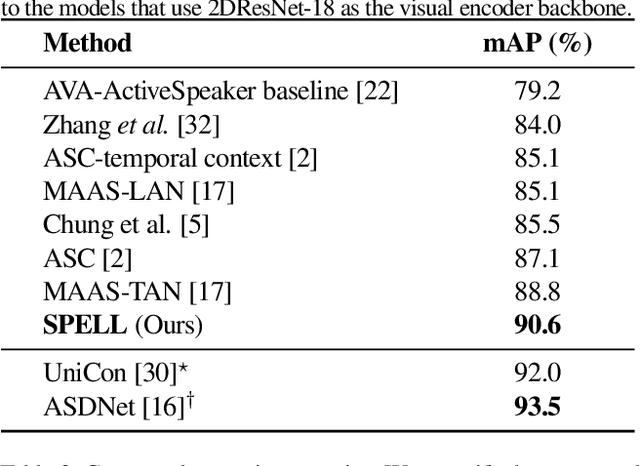
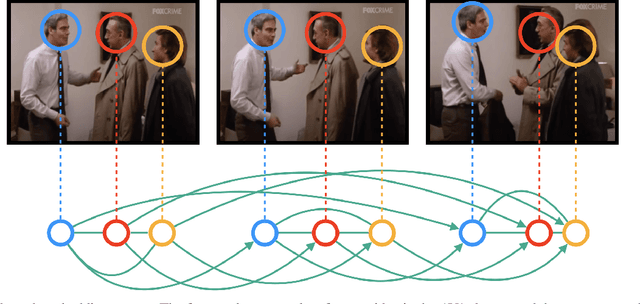
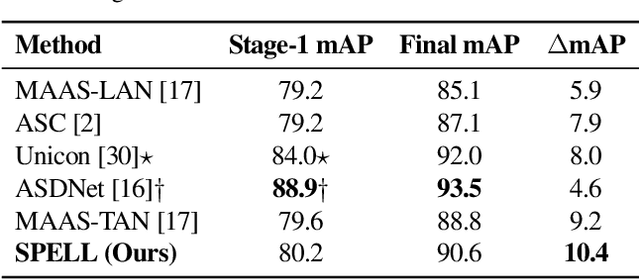
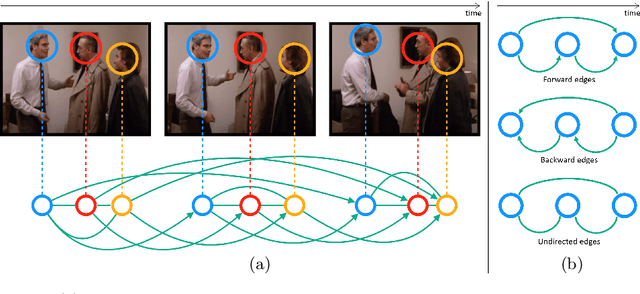
We address the problem of active speaker detection through a new framework, called SPELL, that learns long-range multimodal graphs to encode the inter-modal relationship between audio and visual data. We cast active speaker detection as a node classification task that is aware of longer-term dependencies. We first construct a graph from a video so that each node corresponds to one person. Nodes representing the same identity share edges between them within a defined temporal window. Nodes within the same video frame are also connected to encode inter-person interactions. Through extensive experiments on the Ava-ActiveSpeaker dataset, we demonstrate that learning graph-based representation, owing to its explicit spatial and temporal structure, significantly improves the overall performance. SPELL outperforms several relevant baselines and performs at par with state of the art models while requiring an order of magnitude lower computation cost.
Incorporating Scalability in Unsupervised Spatio-Temporal Feature Learning
Aug 15, 2018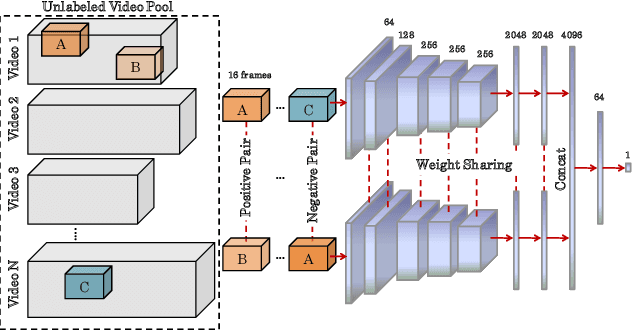
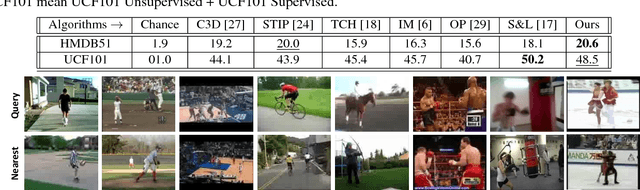


Deep neural networks are efficient learning machines which leverage upon a large amount of manually labeled data for learning discriminative features. However, acquiring substantial amount of supervised data, especially for videos can be a tedious job across various computer vision tasks. This necessitates learning of visual features from videos in an unsupervised setting. In this paper, we propose a computationally simple, yet effective, framework to learn spatio-temporal feature embedding from unlabeled videos. We train a Convolutional 3D Siamese network using positive and negative pairs mined from videos under certain probabilistic assumptions. Experimental results on three datasets demonstrate that our proposed framework is able to learn weights which can be used for same as well as cross dataset and tasks.
W-TALC: Weakly-supervised Temporal Activity Localization and Classification
Aug 14, 2018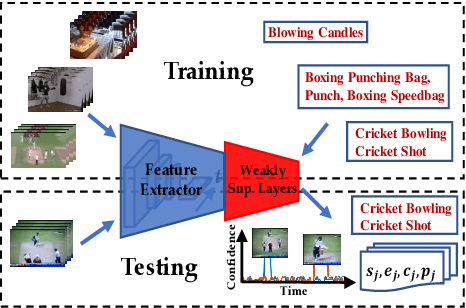
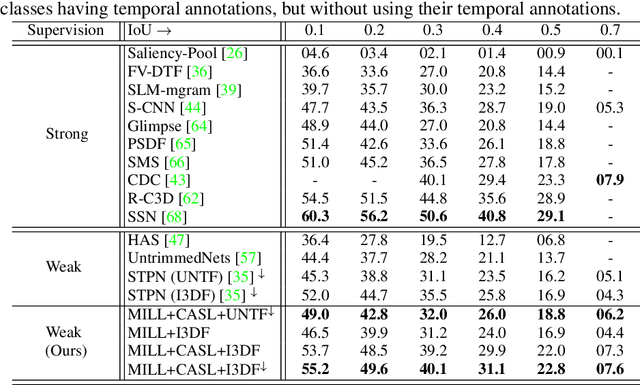
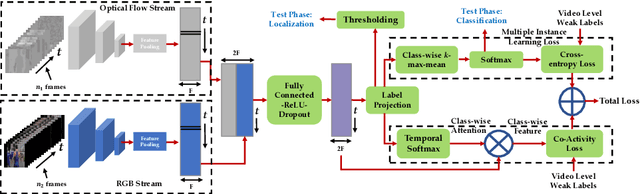

Most activity localization methods in the literature suffer from the burden of frame-wise annotation requirement. Learning from weak labels may be a potential solution towards reducing such manual labeling effort. Recent years have witnessed a substantial influx of tagged videos on the Internet, which can serve as a rich source of weakly-supervised training data. Specifically, the correlations between videos with similar tags can be utilized to temporally localize the activities. Towards this goal, we present W-TALC, a Weakly-supervised Temporal Activity Localization and Classification framework using only video-level labels. The proposed network can be divided into two sub-networks, namely the Two-Stream based feature extractor network and a weakly-supervised module, which we learn by optimizing two complimentary loss functions. Qualitative and quantitative results on two challenging datasets - Thumos14 and ActivityNet1.2, demonstrate that the proposed method is able to detect activities at a fine granularity and achieve better performance than current state-of-the-art methods.
WEPSAM: Weakly Pre-Learnt Saliency Model
May 03, 2016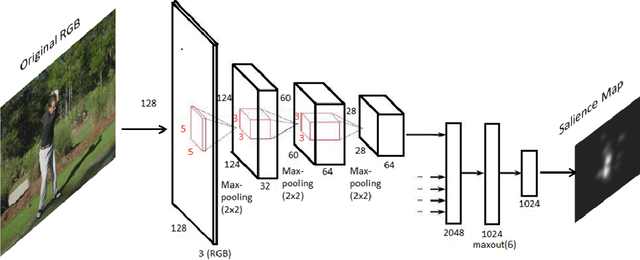
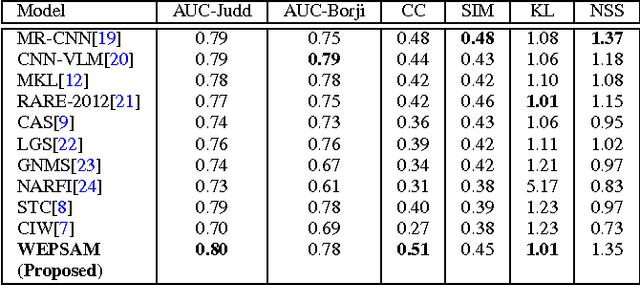
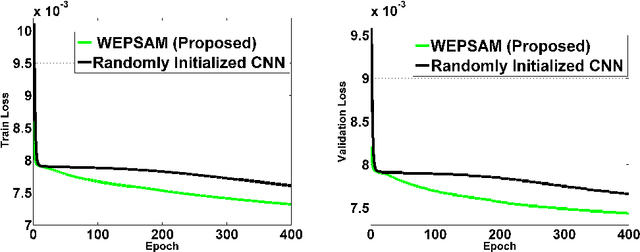
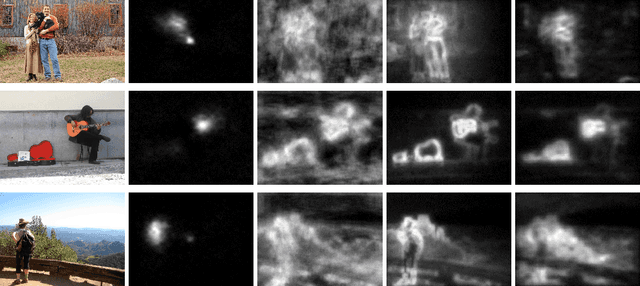
Visual saliency detection tries to mimic human vision psychology which concentrates on sparse, important areas in natural image. Saliency prediction research has been traditionally based on low level features such as contrast, edge, etc. Recent thrust in saliency prediction research is to learn high level semantics using ground truth eye fixation datasets. In this paper we present, WEPSAM : Weakly Pre-Learnt Saliency Model as a pioneering effort of using domain specific pre-learing on ImageNet for saliency prediction using a light weight CNN architecture. The paper proposes a two step hierarchical learning, in which the first step is to develop a framework for weakly pre-training on a large scale dataset such as ImageNet which is void of human eye fixation maps. The second step refines the pre-trained model on a limited set of ground truth fixations. Analysis of loss on iSUN and SALICON datasets reveal that pre-trained network converges much faster compared to randomly initialized network. WEPSAM also outperforms some recent state-of-the-art saliency prediction models on the challenging MIT300 dataset.
Visual saliency detection: a Kalman filter based approach
Apr 17, 2016

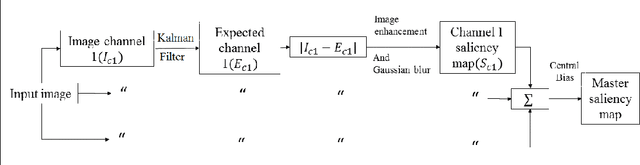
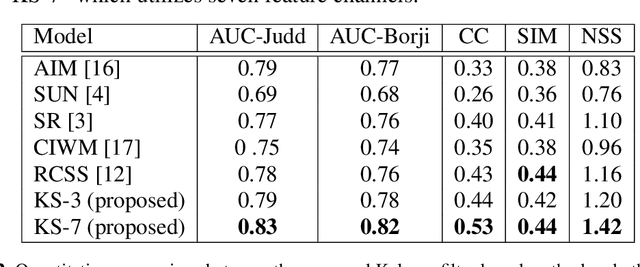
In this paper we propose a Kalman filter aided saliency detection model which is based on the conjecture that salient regions are considerably different from our "visual expectation" or they are "visually surprising" in nature. In this work, we have structured our model with an immediate objective to predict saliency in static images. However, the proposed model can be easily extended for space-time saliency prediction. Our approach was evaluated using two publicly available benchmark data sets and results have been compared with other existing saliency models. The results clearly illustrate the superior performance of the proposed model over other approaches.