 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Path Stable Soft Prompt Generation for Domain Generalization
May 24, 2025Domain generalization (DG) aims to learn a model using data from one or multiple related but distinct source domains that can generalize well to unseen out-of-distribution target domains. Inspired by the success of large pre-trained vision-language models (VLMs), prompt tuning has emerged as an effective generalization strategy. However, it often struggles to capture domain-specific features due to its reliance on manually or fixed prompt inputs. Recently, some prompt generation methods have addressed this limitation by dynamically generating instance-specific and domain-specific prompts for each input, enriching domain information and demonstrating potential for enhanced generalization. Through further investigation, we identify a notable issue in existing prompt generation methods: the same input often yields significantly different and suboptimal prompts across different random seeds, a phenomenon we term Prompt Variability. To address this, we introduce negative learning into the prompt generation process and propose Dual-Path Stable Soft Prompt Generation (DPSPG), a transformer-based framework designed to improve both the stability and generalization of prompts. Specifically, DPSPG incorporates a complementary prompt generator to produce negative prompts, thereby reducing the risk of introducing misleading information. Both theoretical and empirical analyses demonstrate that negative learning leads to more robust and effective prompts by increasing the effective margin and reducing the upper bound of the gradient norm. Extensive experiments on five DG benchmark datasets show that DPSPG consistently outperforms state-of-the-art methods while maintaining prompt stability.
Soft Prompt Generation for Domain Generalization
Apr 30, 2024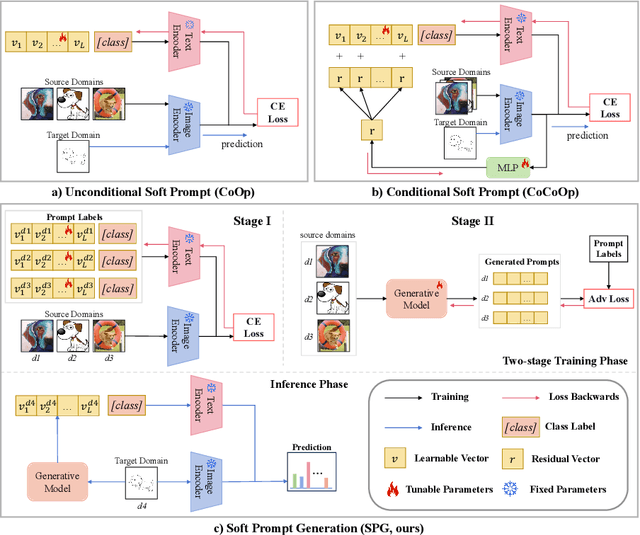
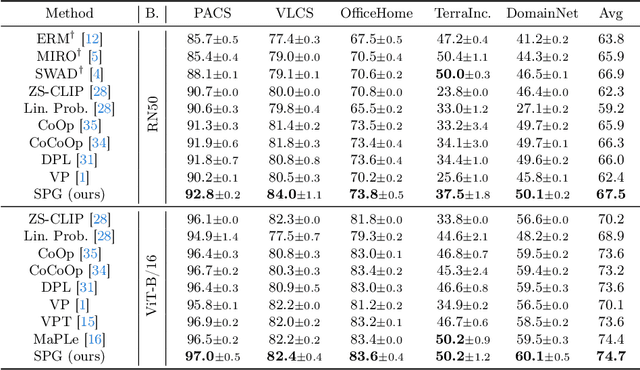
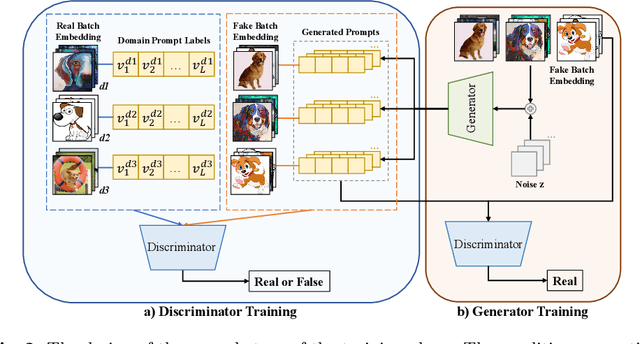
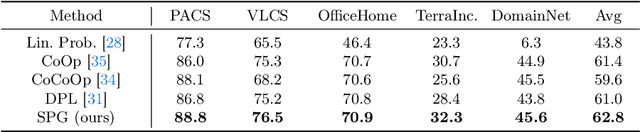
Large pre-trained vision language models (VLMs) have shown impressive zero-shot ability on downstream tasks with manually designed prompt, which are not optimal for specific domains. To further adapt VLMs to downstream tasks, soft prompt is proposed to replace manually designed prompt, which acts as a learning vector that undergoes fine-tuning based on specific domain data. Prior prompt learning methods primarily learn a fixed prompt and residuled prompt from training samples. However, the learned prompts lack diversity and ignore information about unseen domains, potentially compromising the transferability of the prompts. In this paper, we reframe the prompt learning framework from a generative perspective and propose a simple yet efficient method for the Domain Generalization (DG) task, namely \textbf{S}oft \textbf{P}rompt \textbf{G}eneration (SPG). To the best of our knowledge, we are the first to introduce the generative model into prompt learning in VLMs and explore its potential for producing soft prompts by relying solely on the generative model, ensuring the diversity of prompts. Specifically, SPG consists of a two-stage training phase and an inference phase. During the training phase, we introduce soft prompt labels for each domain, aiming to incorporate the generative model domain knowledge. During the inference phase, the generator of the generative model is employed to obtain instance-specific soft prompts for the unseen target domain. Extensive experiments on five domain generalization benchmarks of three DG tasks demonstrate that our proposed SPG achieves state-of-the-art performance. The code will be available soon.
Hierarchical Large Language Models in Cloud Edge End Architecture for Heterogeneous Robot Cluster Control
Feb 16, 2024


Despite their powerful semantic understanding and code generation capabilities, Large Language Models (LLMs) still face challenges when dealing with complex tasks. Multi agent strategy generation and motion control are highly complex domains that inherently require experts from multiple fields to collaborate. To enhance multi agent strategy generation and motion control, we propose an innovative architecture that employs the concept of a cloud edge end hierarchical structure. By leveraging multiple large language models with distinct areas of expertise, we can efficiently generate strategies and perform task decomposition. Introducing the cosine similarity approach,aligning task decomposition instructions with robot task sequences at the vector level, we can identify subtasks with incomplete task decomposition and iterate on them multiple times to ultimately generate executable machine task sequences.The robot is guided through these task sequences to complete tasks of higher complexity. With this architecture, we implement the process of natural language control of robots to perform complex tasks, and successfully address the challenge of multi agent execution of open tasks in open scenarios and the problem of task decomposition.
Automatic Robotic Development through Collaborative Framework by Large Language Models
Feb 16, 2024



Despite the remarkable code generation abilities of large language models LLMs, they still face challenges in complex task handling. Robot development, a highly intricate field, inherently demands human involvement in task allocation and collaborative teamwork . To enhance robot development, we propose an innovative automated collaboration framework inspired by real-world robot developers. This framework employs multiple LLMs in distinct roles analysts, programmers, and testers. Analysts delve deep into user requirements, enabling programmers to produce precise code, while testers fine-tune the parameters based on user feedback for practical robot application. Each LLM tackles diverse, critical tasks within the development process. Clear collaboration rules emulate real world teamwork among LLMs. Analysts, programmers, and testers form a cohesive team overseeing strategy, code, and parameter adjustments . Through this framework, we achieve complex robot development without requiring specialized knowledge, relying solely on non experts participation.
Prompt-based Distribution Alignment for Unsupervised Domain Adaptation
Dec 15, 2023Recently, despite the unprecedented success of large pre-trained visual-language models (VLMs) on a wide range of downstream tasks, the real-world unsupervised domain adaptation (UDA) problem is still not well explored. Therefore, in this paper, we first experimentally demonstrate that the unsupervised-trained VLMs can significantly reduce the distribution discrepancy between source and target domains, thereby improving the performance of UDA. However, a major challenge for directly deploying such models on downstream UDA tasks is prompt engineering, which requires aligning the domain knowledge of source and target domains, since the performance of UDA is severely influenced by a good domain-invariant representation. We further propose a Prompt-based Distribution Alignment (PDA) method to incorporate the domain knowledge into prompt learning. Specifically, PDA employs a two-branch prompt-tuning paradigm, namely base branch and alignment branch. The base branch focuses on integrating class-related representation into prompts, ensuring discrimination among different classes. To further minimize domain discrepancy, for the alignment branch, we construct feature banks for both the source and target domains and propose image-guided feature tuning (IFT) to make the input attend to feature banks, which effectively integrates self-enhanced and cross-domain features into the model. In this way, these two branches can be mutually promoted to enhance the adaptation of VLMs for UDA. We conduct extensive experiments on three benchmarks to demonstrate that our proposed PDA achieves state-of-the-art performance. The code is available at https://github.com/BaiShuanghao/Prompt-based-Distribution-Alignment.
Improving Cross-domain Few-shot Classification with Multilayer Perceptron
Dec 15, 2023Cross-domain few-shot classification (CDFSC) is a challenging and tough task due to the significant distribution discrepancies across different domains. To address this challenge, many approaches aim to learn transferable representations. Multilayer perceptron (MLP) has shown its capability to learn transferable representations in various downstream tasks, such as unsupervised image classification and supervised concept generalization. However, its potential in the few-shot settings has yet to be comprehensively explored. In this study, we investigate the potential of MLP to assist in addressing the challenges of CDFSC. Specifically, we introduce three distinct frameworks incorporating MLP in accordance with three types of few-shot classification methods to verify the effectiveness of MLP. We reveal that MLP can significantly enhance discriminative capabilities and alleviate distribution shifts, which can be supported by our expensive experiments involving 10 baseline models and 12 benchmark datasets. Furthermore, our method even compares favorably against other state-of-the-art CDFSC algorithms.