 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Path Stable Soft Prompt Generation for Domain Generalization
May 24, 2025Domain generalization (DG) aims to learn a model using data from one or multiple related but distinct source domains that can generalize well to unseen out-of-distribution target domains. Inspired by the success of large pre-trained vision-language models (VLMs), prompt tuning has emerged as an effective generalization strategy. However, it often struggles to capture domain-specific features due to its reliance on manually or fixed prompt inputs. Recently, some prompt generation methods have addressed this limitation by dynamically generating instance-specific and domain-specific prompts for each input, enriching domain information and demonstrating potential for enhanced generalization. Through further investigation, we identify a notable issue in existing prompt generation methods: the same input often yields significantly different and suboptimal prompts across different random seeds, a phenomenon we term Prompt Variability. To address this, we introduce negative learning into the prompt generation process and propose Dual-Path Stable Soft Prompt Generation (DPSPG), a transformer-based framework designed to improve both the stability and generalization of prompts. Specifically, DPSPG incorporates a complementary prompt generator to produce negative prompts, thereby reducing the risk of introducing misleading information. Both theoretical and empirical analyses demonstrate that negative learning leads to more robust and effective prompts by increasing the effective margin and reducing the upper bound of the gradient norm. Extensive experiments on five DG benchmark datasets show that DPSPG consistently outperforms state-of-the-art methods while maintaining prompt stability.
Soft Prompt Generation for Domain Generalization
Apr 30, 2024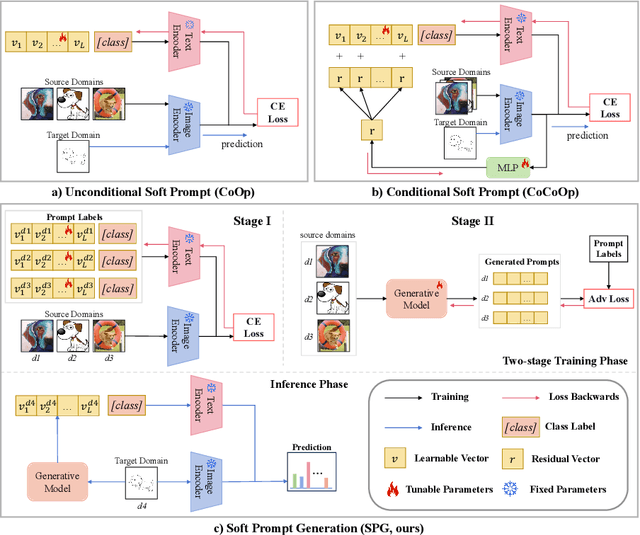
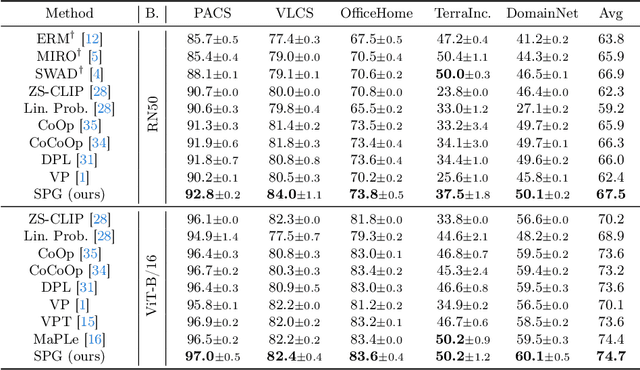
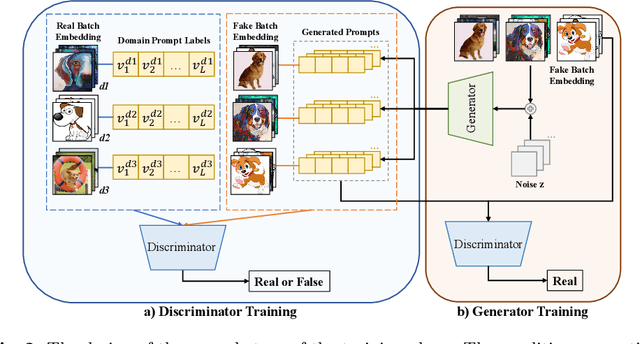
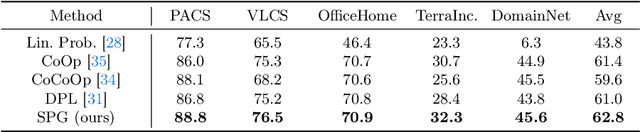
Large pre-trained vision language models (VLMs) have shown impressive zero-shot ability on downstream tasks with manually designed prompt, which are not optimal for specific domains. To further adapt VLMs to downstream tasks, soft prompt is proposed to replace manually designed prompt, which acts as a learning vector that undergoes fine-tuning based on specific domain data. Prior prompt learning methods primarily learn a fixed prompt and residuled prompt from training samples. However, the learned prompts lack diversity and ignore information about unseen domains, potentially compromising the transferability of the prompts. In this paper, we reframe the prompt learning framework from a generative perspective and propose a simple yet efficient method for the Domain Generalization (DG) task, namely \textbf{S}oft \textbf{P}rompt \textbf{G}eneration (SPG). To the best of our knowledge, we are the first to introduce the generative model into prompt learning in VLMs and explore its potential for producing soft prompts by relying solely on the generative model, ensuring the diversity of prompts. Specifically, SPG consists of a two-stage training phase and an inference phase. During the training phase, we introduce soft prompt labels for each domain, aiming to incorporate the generative model domain knowledge. During the inference phase, the generator of the generative model is employed to obtain instance-specific soft prompts for the unseen target domain. Extensive experiments on five domain generalization benchmarks of three DG tasks demonstrate that our proposed SPG achieves state-of-the-art performance. The code will be available soon.