Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Multi-Head Attention on Trojan BERT Models
Paper and Code
Jun 12, 2024


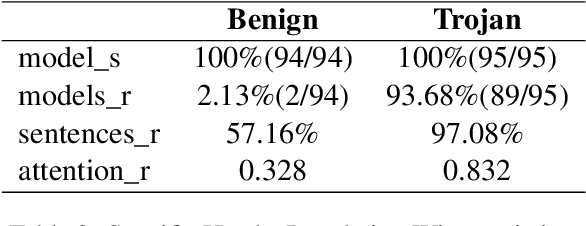
This project investigates the behavior of multi-head attention in Transformer models, specifically focusing on the differences between benign and trojan models in the context of sentiment analysis. Trojan attacks cause models to perform normally on clean inputs but exhibit misclassifications when presented with inputs containing predefined triggers. We characterize attention head functions in trojan and benign models, identifying specific 'trojan' heads and analyzing their behavior.
View paper on