 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Sensor Fusion against Inaudible Command Attacks in Advanced Driver-Assistance System
Paper and Code
May 30, 2023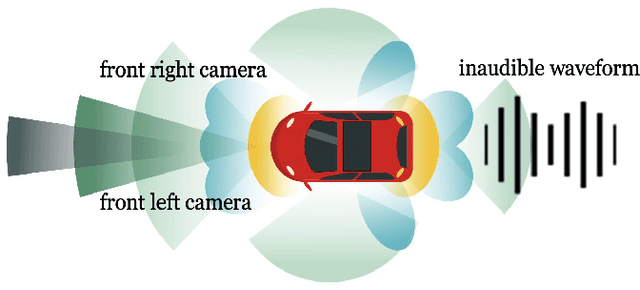
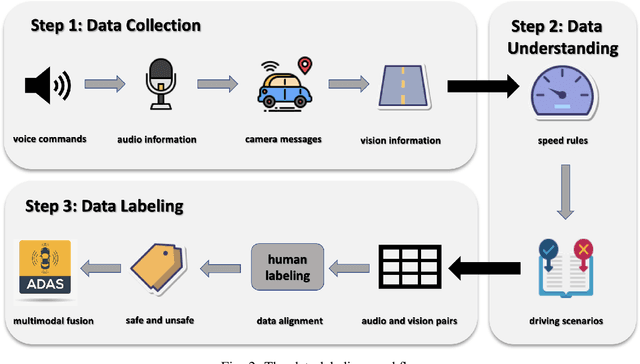
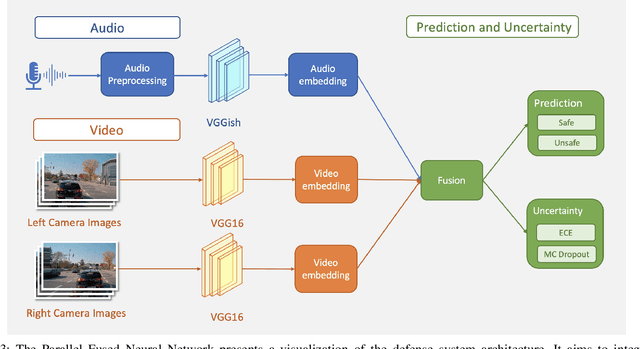
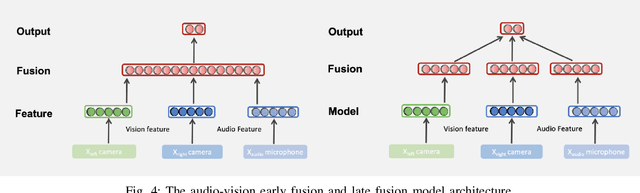
There are increasing concerns about malicious attacks on autonomous vehicles. In particular, inaudible voice command attacks pose a significant threat as voice commands become available in autonomous driving systems. How to empirically defend against these inaudible attacks remains an open question. Previous research investigates utilizing deep learning-based multimodal fusion for defense, without considering the model uncertainty in trustworthiness. As deep learning has been applied to increasingly sensitive tasks, uncertainty measurement is crucial in helping improve model robustness, especially in mission-critical scenarios. In this paper, we propose the Multimodal Fusion Framework (MFF) as an intelligent security system to defend against inaudible voice command attacks. MFF fuses heterogeneous audio-vision modalities using VGG family neural networks and achieves the detection accuracy of 92.25% in the comparative fusion method empirical study. Additionally, extensive experiments on audio-vision tasks reveal the model's uncertainty. Using Expected Calibration Errors, we measure calibration errors and Monte-Carlo Dropout to estimate the predictive distribution for the proposed models. Our findings show empirically to train robust multimodal models, improve standard accuracy and provide a further step toward interpretability. Finally, we discuss the pros and cons of our approach and its applicability for Advanced Driver Assistance Systems.